The Reference Contexts Patent
In 2024, the Google API leak revealed an attribute called context2 — a hash stored on every single backlink in Google's index. Next to it sat two more: fullLeftContext and fullRightContext, storing the actual text surrounding each link. Most SEOs walked right past them. They shouldn't have. Because twenty years earlier, on March 15, 2004, Anna Patterson and Paul Haahr — two Google engineers whose work shaped the core ranking infrastructure — filed a patent that explains exactly what those attributes do. The text around your links isn't decoration. It's a fingerprint.
If you've read my analysis of the Historical Data patent, that system monitors when your links appear. This patent monitors where and how — the editorial context in which each link is embedded. Together, they form two halves of Google's link quality assessment. And the 2024 API leak strongly suggests both are still active.
The patent explicitly describes a system that captures text windows around links, extracts rare words via IDF, and hashes them into context fingerprints used for ranking and spam detection. The 2024 API leak contains matching attributes — context2, fullLeftContext, fullRightContext — that correspond to the patent's mechanisms. What we don't know: the exact weight of context fingerprinting in modern ranking, whether the original IDF extraction has been replaced by embedding-based analysis, or how this signal interacts with Google's neural ranking systems. This patent was filed in 2004 — Google's modern infrastructure is probabilistic and ML-driven, so the patented architecture describes design intent, not necessarily the current implementation.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
US8577893B1 explicitly describes analyzing text windows around links, extracting rare words via IDF weighting, hashing them into context identifiers, counting unique contexts as a ranking signal, and discounting statistical outliers as suspected spam. The patent was filed in 2004 and granted in 2013. Google has paid year-12 maintenance fees, meaning they've invested money to keep it active through at least 2025. The API leak exposes context2, fullLeftContext, and fullRightContext as live attributes stored per-link.
The 5-word window described in the patent has likely expanded — the patent itself mentions "fifteen words" as an alternative. The fullLeftContext and fullRightContext fields store lists of strings, suggesting the modern system captures more than individual rare words. indyrank — a 16-bit diversity metric — likely incorporates context diversity alongside other independence signals. The connection between context fingerprinting and anchorMismatchDemotion is an inference based on functional overlap: both classify links based on the relationship between link context and target content.
The exact weight of context fingerprinting in the modern ranking formula is unknown. Whether the IDF-based rare word extraction has been replaced by embedding-based semantic analysis is unknown — though the API still stores a hash field (context2), suggesting the hashing mechanism survives in some form. The relationship between context diversity and sourceType tiering (HIGH_QUALITY / MEDIUM / LOW) is unclear: it's possible that context quality influences the source quality classification, or they may be independent signals.
Patent Metadata
Note the nine-year gap between filing (2004) and grant (2013). This wasn't unusual for Google patents of that era — the technology was deployed long before the patent office issued the document. This patent was filed just three months after the Historical Data patent (US7346839B2) — December 2003 and March 2004. While different inventors filed each patent, the timing suggests a coordinated effort within Google to build the link quality evaluation layer: Historical Data monitors when links appear, while Reference Contexts evaluates how they're editorially embedded.
Note: This patent was filed in 2004. Google's modern ranking systems are neural and probabilistic — the patented architecture describes the design intent, not necessarily the current implementation. The API leak attributes suggest the core mechanism persists in some form, but the exact implementation has likely evolved.
What This Patent Does (Plain English)
Here's the problem this patent solves. Before it existed, Google's link evaluation was mostly about who linked to you and what the anchor text said. That created two exploits. First, link farms — hundreds of automated pages could generate thousands of links, all from identical templates. Second, Google bombs — coordinate enough links with the anchor text "miserable failure" and you could force a page to rank for that term. Google needed to understand not just the link, but the editorial environment surrounding it.
Here's what the system actually does:
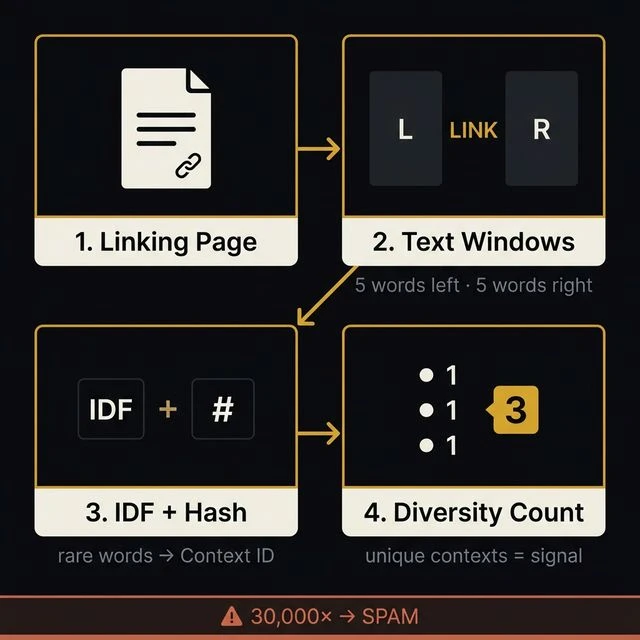
- Parse the linking page — identify all outbound links by their HTML tags
- Capture two text windows — five words to the left of the link, five words to the right
- Extract the rarest word from each window — using inverse document frequency (IDF) weighting, find the most unusual real word on each side
- Hash both rare words into a fingerprint — create a single numerical "context identifier" that represents the editorial environment of that link
- Count unique fingerprints per target — more diverse, independently-authored contexts pointing to a page = stronger signal of legitimate authority
- Discount suspicious patterns — if one context identifier appears 10,000 times while others appear 10 times, that context is flagged as machine-generated and discounted
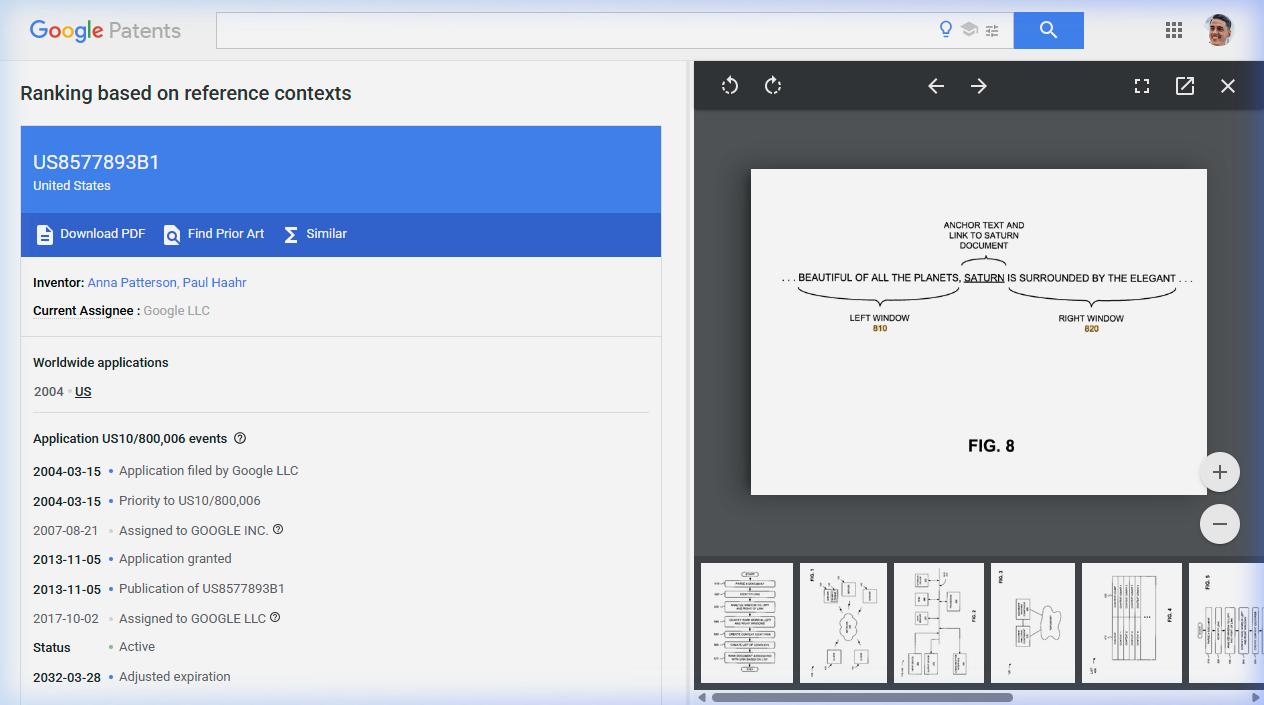
Here's the example from the actual patent. In FIG. 6, a document about Saturn contains a link to www.planetsaturn.com within the sentence: "Perhaps the most beautiful of all the planets, Saturn is surrounded by an elegant and interesting ring system."
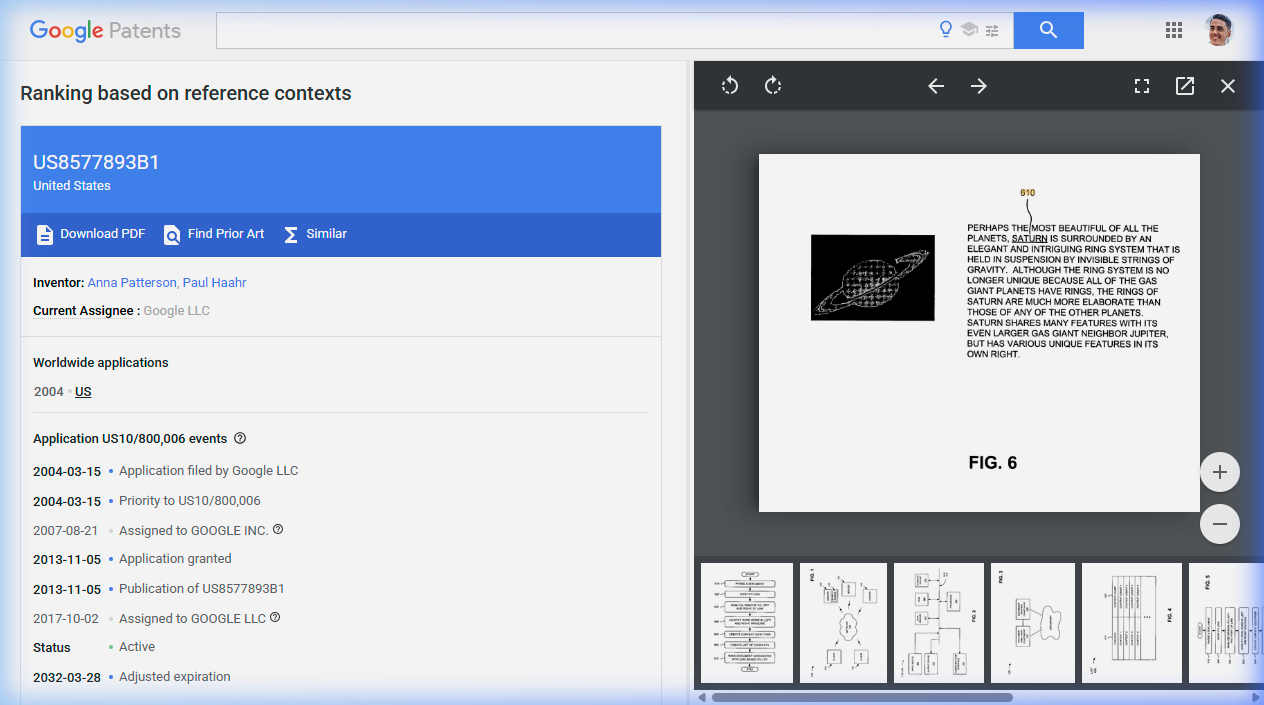
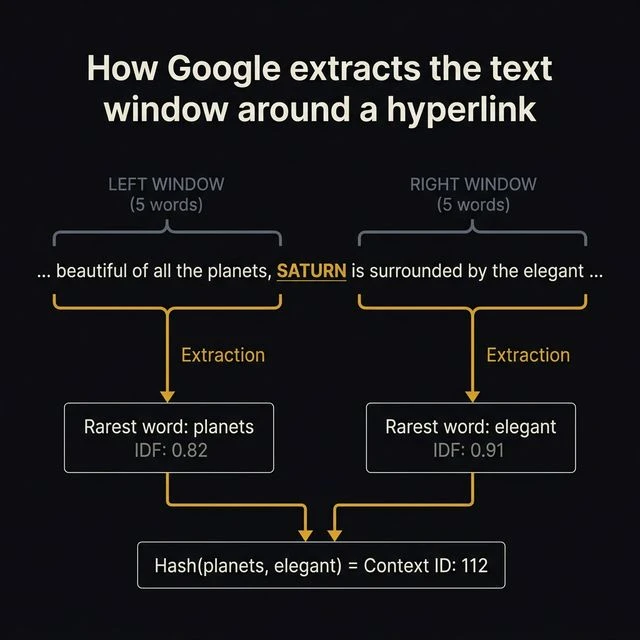
The system captures a 5-word left window — "beautiful of all the planets" — and a 5-word right window — "is surrounded by the elegant." It identifies "planets" as the rarest word on the left and "elegant" as the rarest on the right. Those two words are hashed into a context identifier: 112.
Wait. Let me translate that to human.
↓
That number — 112 — now represents this specific editorial placement. If fifteen other astronomy pages also link to planetsaturn.com, each from different editorial contexts, the target accumulates fifteen different context identifiers. A link farm that generates a thousand links from the same template? Same rare words every time. Same context identifier every time. Count = 1.
Left window: "beautiful of all the planets" → Rarest word: planets
Right window: "is surrounded by the elegant" → Rarest word: elegant
Context identifier: hash("planets", "elegant") = 112
This is how Google converts prose into a numerical trust signal. Every link the system processes gets one of these fingerprints.
The Context Fingerprint: How Google Reads Around Your Links
Let me walk you through how the fingerprinting mechanism actually works. It operates in three layers, each one more subtle than the last.
Layer 1: The Text Window
The patent specifies a default window of five words on each side of the link. In practice, the implementation "may include more or fewer words (e.g., fifteen words)." The key is that only real words count — the patent explicitly excludes "random blocks of text that include symbols or numbers." A real word is defined as one that "occurs at least a minimal number of times on many different documents" — the patent suggests at least fifty occurrences.
This is an elegant anti-gibberish filter. A page stuffed with random character strings to inflate the word count won't produce valid rare words. Only pages with genuine editorial content — real sentences written by real people — generate meaningful context identifiers.
Layer 2: The IDF Extraction
Finding the rarest word uses inverse document frequency — the same mathematical foundation behind modern information retrieval scoring. The system analyzes the entire web corpus and builds a hash table of every word's frequency. Words that appear less often across fewer documents score higher. "The" scores near zero. "Astronautical" scores high.
Here's the thing: this is why good writing naturally produces strong context fingerprints. A journalist at the New York Times covering a pharmaceutical breakthrough will naturally use precise, discipline-specific vocabulary — words like "pharmacokinetics" or "bioavailability" — that score extremely high on IDF. A link farm template stuffed with generic phrases like "click here for more information" produces words that score near zero.
Why does good digital PR link building produce such good results? Because a proper journalist wrote the content. People who write well write in a unique, clear voice — and that's not replicable at scale. This patent is looking for exactly that: content produced by unique authors who talk with richness and specificity about their subject. You don't have to be the New York Times. If you're a dedicated independent publisher putting real content effort into your pieces, your links will naturally produce strong, unique fingerprints. The fingerprint is a proxy for editorial care.
Layer 3: The Hash Function
The two rarest words — one from each side — are combined through a hashing function to produce a single context identifier. The patent describes two approaches: hashing each word individually and combining, or concatenating them first and hashing the pair. Either way, the output is a single numerical fingerprint that uniquely represents the editorial context of that specific link.
This appears to correspond to the attribute stored in the API leak as context2. And the raw text before the hash? That's likely what fullLeftContext and fullRightContext capture — Google stores both the fingerprint and the source material.
Context Diversity: Why Unique Editorial Contexts Win
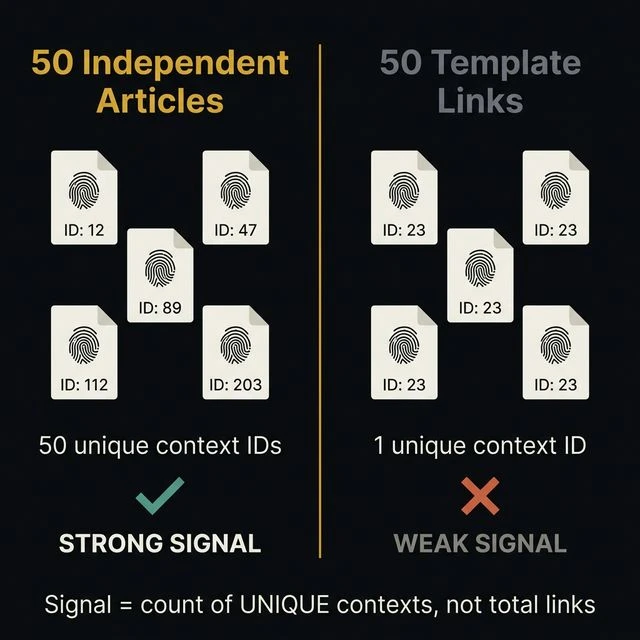
The ranking signal isn't the context identifier itself — it's how many different context identifiers a page accumulates. The patent is explicit: "document ranking component may use the number of different contexts (which may correspond to the number of entries in the list) for a document to determine a ranking score."
Think of it as an editorial vote counter that ignores duplicates. Not "how many links do you have?" but "how many independently written editorial contexts mention you?"
| Scenario | Links | Unique Contexts | Effective Signal |
|---|---|---|---|
| 50 links from 50 independent articles | 50 | 50 | Strong — diverse editorial endorsement |
| 50 links from the same PBN template | 50 | 1–3 | Weak — same template = same context |
| 50 links from AI-generated articles using the same prompt | 50 | 2–5 | Weak — LLMs produce similar word patterns |
| 10 links from expert-written industry publications | 10 | 10 | Strong — every author has a unique vocabulary |
This mechanism is a conceptual ancestor of what the API leak calls indyrank — stored as uint16 [0–65535] per link, measuring source independence and diversity. The patent measures context diversity; IndyRank measures source independence. The underlying principle is identical: genuine authority comes from diverse, independent endorsements.
A Private Blog Network of 200 sites using 5 content templates will produce at most 5 unique context identifiers — regardless of how many links they generate. The patent specifically addresses this: "standard frames sometimes include 'products' links, 'jobs' links… this duplication of links may artificially inflate the ranks." Template-based link building is the modern version of the same problem.
Spam Detection: When Context Counts Get Suspicious
Now here's where it gets interesting. The patent doesn't just count unique contexts — it analyzes the distribution of context counts. This is the spam detection layer, and it works on two dimensions: absolute distribution and temporal distribution history.
Absolute Distribution
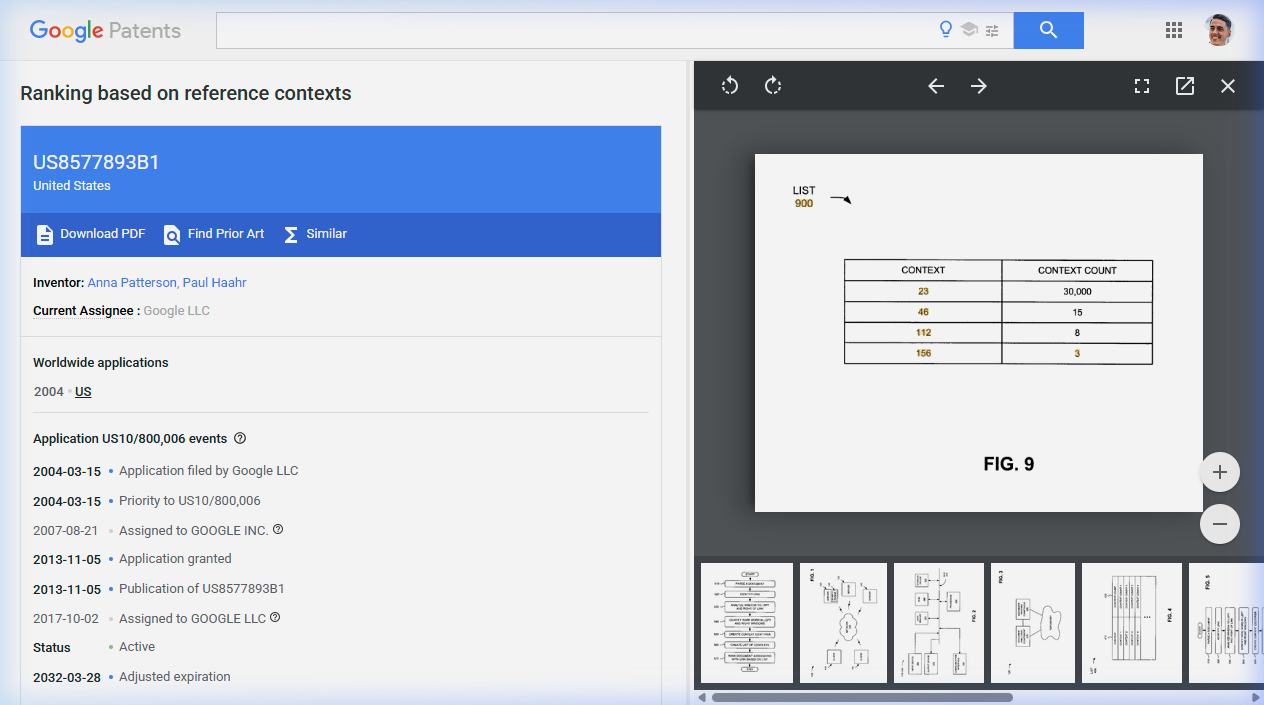
The patent gives a concrete example in FIG. 9: a target page with four context identifiers — 23, 46, 112, and 156. Their counts: 30,000, 15, 8, and 3. Context 23's count is wildly disproportionate. The system's response: "Document ranking component may discount context 1 as suspicious (e.g., possibly machine generated)." Context 23 is eliminated from the ranking process, leaving three legitimate contexts.
Wait. Let me translate that to human.
↓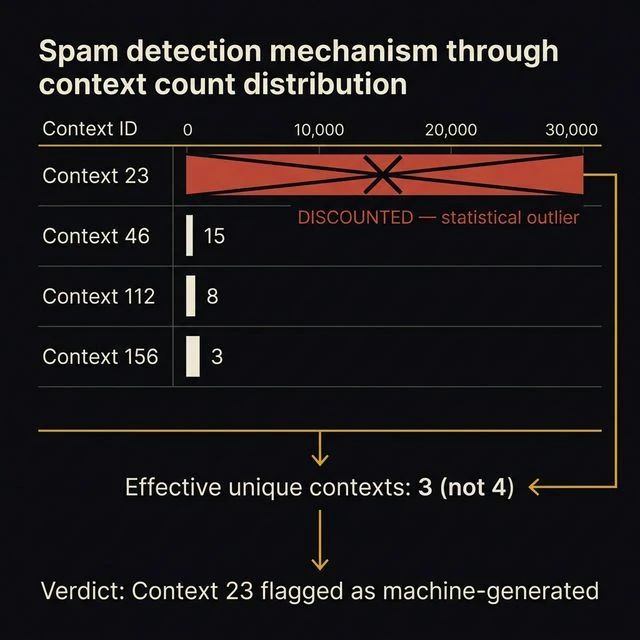
The mathematical logic is clean: real editorial mentions follow a natural distribution. Three independent bloggers and one industry publication might produce counts of 15, 8, 3, and 1. A link farm producing 30,000 identical contexts is statistically impossible through organic editorial activity. The outlier is the signal.
Temporal Distribution History
The second detection layer is temporal — tracking how context counts change over time. Again, the patent provides a concrete example: in period 1, a document has two contexts with counts of 20 each (total: 40). In period 2, a third context appears with a count of 18,000 (total: 18,040). The system's verdict: "Based on this large change in the distribution of the context counts, document ranking component may identify the document as suspicious."
This is the precursor to what the API leak stores as the AnchorPhraseSpamInfo system — nine attributes tracking phraseAnchorSpamDays (how quickly 80% of spam phrases appeared), phraseAnchorSpamRate (daily discovery rate), and phraseAnchorSpamPenalty (the applied demotion). The patent's temporal distribution monitoring evolved into a full-blown velocity detection system.
This temporal checking mechanism connects directly to the Historical Data patent (US7346839B2) — filed just three months earlier by the same team. That patent tracks link velocity over time. This patent tracks context distribution over time. Together, they create a two-layer temporal defense: the Historical Data patent catches sudden spikes in link volume, while Reference Contexts catches sudden spikes in context homogeneity. You can drip-feed links slowly to bypass the velocity filter — but if they all come from the same editorial template, the context filter still catches you.
Reference Contexts SEO Implications: What This Means for Your Link Building
1. The Brand Anchor + Keyword Context Strategy
At GetMeLinks, we build most of our links with the brand name as the anchor text and put the target keyword in the surrounding text. Every campaign, every guest post — that's the fundamental approach. I don't like pointing to the homepage with keyword-rich anchors; I try to avoid that as much as possible. Instead, I ensure the keyword appears naturally in the text before or after the link.
This isn't just about avoiding anchor text penalties. It's about producing strong context fingerprints. When the brand name sits inside a paragraph that naturally discusses the target topic, the rare words surrounding the link become topically aligned with the target page. The context identifier becomes a relevance signal, not just a diversity signal.
2. Link Insertions Need New Editorial Context
When you just insert a link on an existing paragraph — slap the keyword link right there — it typically does nothing. The surrounding content doesn't cut it, plus the content doesn't have sufficient freshness and informational gain besides the new link. But when you add an entire new section — a paragraph or two, an image, rich data, and the backlink — those link insertions perform dramatically better.
The reason is now clear: a bare link insertion inherits the existing paragraph's context fingerprint — a fingerprint Google has already seen and indexed. There's no new editorial context. Adding a full new section creates a new fingerprint: new rare words, new context identifier, new signal.
3. Guest Post Quality Is a Context Quality Signal
This patent explains something I've seen across thousands of campaigns: links from well-written guest posts outperform links from template content. Now I know the mechanism. It's the IDF extraction. Expert writers naturally use rare, precise vocabulary. Their prose generates strong, distinctive context fingerprints — fingerprints that no other page will duplicate. Template writers use generic, high-frequency words that produce weak, non-distinctive fingerprints.
4. The Passage-Level Placement Strategy
If you've been paying attention to heading vectorization and content chunking — how Google breaks pages into passages for independent ranking — you arrive at a 2026 synthesis of this patent. The paragraph where your link appears needs to address a long-tail query that could be a chunked-down answer. The passage should have relevance, visibility, and traffic potential. That's the modern reading: the guest post's homepage is sharp, and where your backlink lives is a strong passage that has value for LLMs and passage-level indexing.
US7346839B2 — "Historical Data" — Monitors link velocity and temporal patterns. Filed three months before this patent by the same team.
US11409748B1 — "Passage Ranking" — The heading vectorization system that determines how Google chunks pages into passages. The intersection of passage ranking and reference contexts is where 2026 link building lives.
Google API Leak Cross-Reference: Context Fingerprinting Attributes
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — revealed multiple attributes that align directly with this patent's mechanisms:
| Patent Mechanism | API Attribute | Alignment |
|---|---|---|
| 5-word left/right text window | fullLeftContext / fullRightContext | 🔶 STRONG MATCH — field names and data types align directly with patent mechanism |
| Rare word extraction → context fingerprint | context2 (hash) | 🔶 STRONG MATCH — hash field corresponds to patent's context identifier |
| Anti-anchor-text-bombing (context ≠ target) | anchorMismatchDemotion [0–1023] | 🔶 STRONG INFERENCE |
| Context diversity as ranking signal | indyrank [0–65535] | 🔶 API EXTENDS |
| Temporal distribution history | phraseAnchorSpamDays, phraseAnchorSpamRate | 🔶 API EXTENDS |
| Standard frame / nav link devaluation | parallelLinks [0, ∞) | 🔶 API EXTENDS |
| Distribution-based spam discounting | anchorMismatchDemotion [0–1023] | 🔶 API EXTENDS |
| Rare phrase identification (multi-word) | — | 📜 PATENT ONLY |
Two core patent mechanisms — text window capture and context fingerprinting — have strongly corresponding API attributes (field names and data types align directly with the patent's descriptions). One more (anti-anchor-bombing) has a strong functional inference in the API. Four additional mechanisms have been extended beyond the patent's original scope. Only one — rare phrase identification — has no direct API counterpart.
The API leak provides attribute names and data types — not the actual scoring formulas. The patent provides the mechanisms. Together they form a strong evidentiary chain. context2 as a hash field directly corresponds to the patent's "context identifier." fullLeftContext / fullRightContext as string arrays directly correspond to the patent's text windows. Neither alone is proof; together, they're as close to proof as we get in SEO.
Citation Network
Forward Citations (Patents Citing This Patent)
| Patent | Relevance |
|---|---|
| US9576053B2 | Extends reference context analysis with additional ranking signals |
| US11561987B1 | Modern evolution — likely integrates context fingerprinting with neural methods |
| US11841912B2 | Recent 2023 patent — suggests continued Google investment in context-based ranking |
| US12061612B1 | 2024 patent — latest in the citation chain, confirming continued evolution |
Key Patents This Patent Cites
| Patent | Relationship |
|---|---|
| US7020847B1 | Earlier link analysis methods that Reference Contexts improves upon |
| US5848407A | Foundational document retrieval — the information retrieval base this patent builds on |
Related Articles on This Site
- US7346839B2 (Historical Data Patent) — Filed three months before Reference Contexts by overlapping inventors. Monitors link velocity over time while this patent monitors link context quality. Together, they form the temporal + contextual defense layer.
- US11409748B1 (Passage Ranking Patent) — The heading vectorization system that chunks pages into independently rankable passages. The 2026 intersection: place your links inside passages strong enough to rank independently.
- US8661029B1 (NavBoost Patent) — User behavior signals that determine whether a linking page is HIGH_QUALITY or LOW_QUALITY. Links from pages with real user engagement pass context fingerprints that matter; links from zero-traffic pages pass fingerprints that get ignored.
- US10235423B2 (Entity Scoring Patent) — Entity trust signals that complement link context. When the rare words around a link match recognized entity names, the context identifier carries additional topical weight.
- US7603350B1 (Entity Trust Patent) — If Reference Contexts evaluates the how of an endorsement, Entity Trust evaluates the who. This patent describes trust propagation between people — the entity-level complement to the editorial quality that context fingerprinting measures.
- US7716225B1 (Reasonable Surfer Patent) — The Reasonable Surfer determines per-link equity using 23 features including font size, position, and surrounding context. Reference Contexts validates the editorial environment around that link. Together, they form a complementary system: Reasonable Surfer assigns the weight; Reference Contexts verifies the editorial quality.
- NavBoost Deep Dive — Reference Contexts determines the quality of the editorial context around links. NavBoost determines whether users who follow those links actually stay. Both signals feed the same ranking infrastructure — context quality predicts click quality, and NavBoost measures whether that prediction holds. The practitioner synthesis maps the full pipeline.
Reference Contexts: What Doesn't Matter as Much as SEOs Think
The nature of this patent is that links are not isolated objects. They are embedded in prose, surrounded by meaning, placed by authors with varying degrees of care and competence. The most fundamental truth this patent asserts is that the quality of the editorial environment around a link is itself a signal — perhaps more important than the anchor text.
The flavor — a 5-word window, IDF-weighted rare word extraction, numerical hashing — was the 2004 approach. It was designed to be computationally cheap at web scale, back when crawling a billion pages was still a serious engineering challenge. The precise window size, the specific hashing function, the exact IDF corpus — these implementation details have likely evolved. The patent's own text acknowledges this: "more or fewer words" may be used.
The precise scope — just five words before, just five words after — has most likely evolved beyond what had to be cheap mathematically to operate and fit inside an algorithm. But the underlying principle most certainly cannot have disappeared. It makes too much sense. It's an elegant solution for both context disambiguation and link spam detection. And in 2026, it's likely been absorbed into a larger, probably LLM-driven system that evaluates this alongside dozens of other signals.
Here's the frame that matters: it's not the same thing to read the word "plane" when the text before says "American Airlines" and the text after says "landed" — versus the text before says "Magic Mushrooms" and the text after says "of existence." The surrounding text absolutely changes the meaning of the anchor. That's not a technical insight. That's a linguistic one. And it's the kind of insight that doesn't get deprecated with a software update.
You cannot circumvent the editorial work. But if the work is good — if the person writing around your link actually cares about the subject — the fingerprint takes care of itself.
Frequently Asked Questions
What does patent US8577893B1 actually do?
It analyzes the text surrounding every link on the web — specifically, a window of words to the left and right of each link. The system extracts the rarest words from each side using IDF weighting, hashes them into a numerical "context identifier" fingerprint, and uses the count of unique fingerprints pointing to a page as a ranking signal. More diverse editorial contexts = higher trust. Suspiciously uniform contexts = discounted as likely spam.
How does Google's context fingerprinting work for links?
Google captures five words to the left and five words to the right of a link. From each window, it identifies the rarest real word using inverse document frequency (IDF) — the same mathematical framework behind modern retrieval scoring. It hashes both rare words into a single context identifier. Each unique identifier represents a unique editorial environment. The API leak stores these as context2 (the hash) and fullLeftContext / fullRightContext (the raw text).
What does the Google API leak confirm about reference contexts?
The 2024 API leak reveals three directly corresponding attributes: context2 (a hash on every anchor record — the fingerprint), fullLeftContext and fullRightContext (lists of strings storing the actual surrounding text), and anchorMismatchDemotion (a 10-bit penalty [0–1023] applied when anchor context doesn't match the target page). The core patent mechanisms — text windows and context hashing — have direct API counterparts, with additional mechanisms extended beyond the patent's original scope.
Should I focus on anchor text or surrounding text for link building?
Both matter, but this patent suggests the surrounding text is the stronger quality signal. A practical approach: use brand names as anchor text and ensure the target keyword appears naturally in the surrounding paragraph. This produces a strong context fingerprint while avoiding anchor text over-optimization penalties. The surrounding editorial context provides topical relevance without the risks of exact-match anchor manipulation.
Does this patent still apply in 2026?
The specific 5-word window likely evolved — the patent itself mentions fifteen words as an alternative, and modern NLP can analyze full paragraphs. But the core principle — evaluating the editorial context around links — is confirmed by active API attributes (context2, fullLeftContext, fullRightContext). Google has also paid year-12 maintenance fees to keep the patent active, indicating ongoing commercial value.
Why do link insertions on existing paragraphs perform poorly?
When you insert a link into an existing paragraph without adding new content, the surrounding text's context fingerprint is one Google has already indexed. There's no new editorial context, no content freshness, and no informational gain. Adding a full new section — new paragraphs, images, and data — creates a new context fingerprint with fresh rare words, giving the link a stronger and more distinctive signal.
What is the relationship between US8577893B1 and the Historical Data patent?
They were filed three months apart by different Google engineering teams within three months of each other. The Historical Data patent (US7346839B2) monitors when links appear — velocity, freshness, temporal spikes. Reference Contexts monitors how links are editorially embedded. Together, they form a dual-layer defense: volume-based anomaly detection plus context-based quality assessment.