For over a decade, Google's public position was that clicks don't influence rankings. Then the Department of Justice put them under oath, and they admitted everything.
Everything.
NavBoost is the system that tracks your clicks, measures how long you stay, and feeds that data directly into the ranking algorithm — precisely the kind of system that Google publicly denied existed for over a decade. Google's 2024 API leak revealed it under the internal codename CRAPS — visible in the API schema as QualityNavboostCrapsCrapsData. In a sworn statement during the United States v. Google LLC antitrust trial, an internal email from a Google VP (Exhibit UPX0197) was entered into evidence describing NavBoost as "more positive on clicks by itself than the rest of ranking." That makes it one of the most influential known re-ranking signals in Google's infrastructure — a feedback layer that acts on results after initial retrieval and scoring by systems like PageRank and BERT. The exact production weights and pipeline ordering are not public, but the direction of the evidence is clear: user behaviour is not a side note. It is central infrastructure.
If you want a grounding read on the system being described here, start with the NavBoost patent analysis — it covers the foundational mechanism in forensic detail. This guide goes well beyond that. I synthesize six patents in the NavBoost continuation chain, Google's leaked API documentation, sworn testimony from the DOJ antitrust trial, and over ten years of SEO work — including the practitioner data from those campaigns — into a unified theory of how NavBoost actually operates in production. Where claims rest on inference rather than direct observation, I've marked that clearly.
Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. This guide draws from three evidence tiers:
NavBoost tracks clicks and dwell time per query-document pair. The LC ratio (Long Click ratio — the proportion of quality clicks to total clicks) mechanism, three-level aggregation, and IRBoost (Information Retrieval Boost — how click signals modify ranking scores) are explicitly described in the patent. Production attributes (goodClicks, badClicks, lastLongestClicks, navDemotion) are confirmed via the API leak. A 13-month click memory window and NavBoost's independence from BERT are confirmed under sworn DOJ testimony. Mobile signals are stored separately. Position bias correction operates via a companion patent (US8938463B1).
Core Web Vitals primarily act as a NavBoost gateway — slow pages produce dishonest click data. Information architecture affects NavBoost through navigation satisfaction patterns. The host-level statistical distribution means inconsistent page quality hurts. clutterScore and NavBoost badClicks are correlated. onsiteProminence connects to NavBoost via within-site navigation data. Fresh positive data likely outweighs stale negative data within the 13-month window.
Exact current production weights (the patent values are examples). How NavBoost's influence varies by query type — it likely weighs more heavily on navigational and commercial queries than on YMYL queries where topical authority and E-E-A-T signals are likely prioritised. How NavBoost interacts with MUM (Multitask Unified Model — Google's multimodal AI system that understands content across languages and formats) and newer NLP ranking systems beyond "additive." Whether Chrome browsing data feeds NavBoost directly or only through SERP interaction. The exact mechanism by which NavBoost data flows into AI Overview source selection — and whether the rise of zero-click queries and AI Overviews is changing how much click data the system can collect. Whether the satisfaction tensor has been expanded beyond country × language × device × location.
NavBoost is not a "click signal." It's a complete feedback loop — a closed-circuit system where user behaviour modifies rankings, which modifies the behaviour data Google collects, which modifies rankings again. It connects to at least seven other production systems. Understanding NavBoost in isolation is like understanding a heart without understanding the circulatory system. This guide maps the full circuit.
The Evidence Stack
Evidence level: Confirmed — patent text, API leak fields, sworn federal testimony.
Let me show you what we're building from. Four categories of primary evidence — no secondary sources, no blog posts, no conference slides, no "a Google employee once said at a meetup." Here's the thing: everything in this guide traces back to patent text, leaked production code, or sworn federal testimony. If I can't point to the source document, it doesn't make the cut.
The Patent Chain (2004–2023)
NavBoost lives in a six-patent continuation chain. All six share identical specification text — the same technical mechanism, described in the same words. The only differences are in the claims (legal scope). This means the core architecture has been legally maintained, without fundamental revision, for over twenty years.
Filed 2006, granted 2014. Contains the complete LC ratio mechanism, click weighting, three-level aggregation, IRBoost, and anti-spam safeguards. Active through 2031. Full patent analysis →
Granted 2016. Narrows claims to the click-weighting function — the mathematical core of how long clicks and short clicks receive different weights.
Granted 2017. Claims the three-level aggregation method — query-document, query-level, and host-level scoring.
Granted 2019. Claims the IRBoost re-ranking mechanism — how NavBoost data feeds back into the ranking algorithm.
Granted 2021. Extended claims on the anti-spam safeguards — the democracy rule and behavioural anomaly detection.
Granted 2023. The most recent continuation — seventeen years after the original filing. Google doesn't continue patents they've abandoned. Maintenance fees alone tell you this is production infrastructure.
Six patents. Seventeen years of maintenance fees. Same specification text. This isn't legacy code — it's active production infrastructure. Google doesn't pay to maintain things they've abandoned.
But the patent chain doesn't exist in isolation. Three companion patents — some from the same inventors — feed into the broader NavBoost architecture:
Same inventor (Hyung-Jin Kim). Provides the mathematical framework for correcting position bias — clicks at position 1 are structurally different from clicks at position 8. Without this patent, raw NavBoost data would be unreliable. 226 forward citations. Full patent analysis →
Speed as a dual-threshold ranking multiplier with device-matched samples. Not a direct ranking factor — a gateway signal that determines whether users can form honest NavBoost opinions.
The mathematical framework for host-level quality drag. Poor pages on your domain mathematically pull down good pages. This is how site-wide quality problems manifest in NavBoost — through the statistical distribution layer. Full patent analysis →
The API Leak — Production Attributes
In 2024, Google's internal API documentation leaked. It revealed the production attribute names that map directly to the patent's mechanisms:
| Attribute | Container | What It Maps To |
|---|---|---|
goodClicks |
CrapsData | Patent "long click" — user stayed, satisfied |
badClicks |
CrapsData | Patent "short click" — user bounced (negative weight) |
lastLongestClicks |
CrapsData | Final click + longest dwell — the strongest positive signal |
unicornClicks |
CrapsData | Disputed — see competing theories below |
mobileSignals |
CrapsData | Separate mobile click signals — device-specific NavBoost |
navDemotion |
CompressedQualitySignals | 10-bit [0–1023] navigational UX penalty from badClicks ratio |
pandaDemotion |
CompressedQualitySignals | Site-level quality penalty (Panda system) |
clutterScore |
NSR | Page clutter — ads, popups, navigation noise |
onsiteProminence |
Content Density | Simulated traffic from homepage + high-click internal pages |
unicornClicks — Two Competing Theories
unicornClicks is a COPPA/GDPR-K compliance flag that identifies click data from minor users (under 13 in the US, under 16 in the EU). This data would be excluded or down-weighted from NavBoost's LC ratio calculations to comply with children's privacy regulations.
Source: Naming convention analysis. Google's codebase uses "unicorn" as an internal label for child/minor user classification in other products. Cross-referenced with COPPA compliance requirements for click data retention.
unicornClicks represents clicks from "unicorn users" — a statistically rare, high-value cohort whose engagement patterns are disproportionately predictive of quality. These could be power users, domain experts, or users whose historical click patterns correlate strongly with eventual ranking stability.
Source: Industry interpretation. Several SEO practitioners and analysts interpreted the field name literally as "rare, exceptional" users. No direct documentation has confirmed or denied this reading.
Our position: Theory A has stronger circumstantial evidence (naming conventions, regulatory requirements), but Theory B cannot be ruled out. The field could serve both functions — compliance flagging AND cohort weighting are not mutually exclusive in a system this large.
Note CrapsData — the container name. CRAPS stands for Click Rate Adjusted by Position and Style. The internal codename leaked alongside the data, confirming the direct connection between the API attributes and the patent mechanism.
DOJ Sworn Testimony
During the United States v. Google LLC antitrust trial (Case No. 1:20-cv-03010, D.D.C.), Google executives testified about NavBoost under oath. Sworn testimony is the highest-confidence evidence available outside the patent text itself.
"NavBoost memorizes all clicks for the last 13 months." — Tr. 6405:15–22
"Quite literally all of the data that Google has collected over 13 months." — Tr. 6433:15–6434:2
BERT "does not subsume big memorization systems, NavBoost, QBST, etc." — Tr. 6440:13–18
"NavBoost alone was/is more positive on clicks by itself than the rest of ranking." — Proposed Findings of Fact at ¶214
"Do not discuss the use of clicks in search... Google has a public position. It is debatable. But please don't craft your own." — Proposed Findings of Fact ¶207
Read that last one again. Google had an internal policy — in writing — telling employees not to discuss whether clicks influence rankings. Because they knew it did, and saying so publicly would invite manipulation.
So for years, Google's stated position was that clicks don't influence rankings — a position that, by their own internal policy, they knew was "debatable." The denial didn't prevent sophisticated operators from reverse-engineering NavBoost through testing. It only prevented good-faith practitioners from understanding the system they were building for. That's the part that bothers me.
Or, as Mark Zuckerberg would have put it:
Senator, we use clicks.
The Core Mechanism
Evidence level: Confirmed (patent + API) for the feedback loop and anti-spam layers. Strong inference for the system interconnections.
I've covered the LC ratio, click weighting, and IRBoost formulas in the NavBoost patent analysis. Here's the thing: knowing the formula isn't enough. What matters is understanding what these mechanisms create when they run together — a feedback loop that connects to everything else in Google's ranking infrastructure.
The Feedback Loop
NavBoost operates as a closed circuit:
SERP Presented → User Clicks → Dwell Time Measured → Weight Applied → LC Ratio Updated → IRBoost Modifies Rankings → New SERP Presented → Cycle Repeats
But this understates its scope. NavBoost doesn't exist in isolation — it connects to at least seven other production systems:
VoltPerDocData — Render speed determines whether users can vote. Separate desktop and mobile scores.
RadishFeatures — NavBoost-driven passage coverage selects which snippets appear on the SERP.
clutterScore — Page clutter (ads, popups, navigation noise) correlates with badClicks.
CompressedQualitySignals — navDemotion feeds alongside pandaDemotion in the quality ensemble.
brandedSearchRatio — Site quality gates NavBoost effectiveness.
renderTreeQualityScore — If content isn't rendered properly, NavBoost gets corrupted data.
US8938463B1 — Adjusts raw click data because clicks at position 1 don't mean the same thing as clicks at position 8.
Anti-Spam Safeguards
Now, the patent describes two layers of click manipulation defence. Very straightforward:
- Democracy rule — Each user gets one vote per time period per query-document pair. Refreshing and clicking again doesn't generate additional signal.
- Behavioural model — Anomalous click profiles are detected and filtered. If 40 clicks arrive from the same IP range within 10 minutes, all with exactly 90-second dwell times, the system flags and discards them.
From the API leak, we know additional safeguards exist: unscaledIpPriorBadFraction stores an IP-based spam prior, and voterTokenCount tracks distinct users who contributed data (a privacy floor that doubles as a manipulation detector).
The safeguards aren't technically unbeatable — but the economics of circumventing them only work in certain industries. As we say in Spanish: "Echa la ley, echa la trampa" — describe the law, and you describe the workaround. Headless browser manipulation doesn't work for NavBoost — not because of bot detection at the CDN layer, but because NavBoost weights clicks by account trust. A headless Chrome instance with no logged-in Google account, or a fresh account with no history, produces clicks that carry zero or near-zero weight. Google can distinguish a real person — someone logged in with years of YouTube, Gmail, and Android activity — from a disposable account created yesterday. The fuller economics of why sophisticated manipulation is niche-dependent are covered in The Most Dangerous Thing About NavBoost.
The 4D Satisfaction Tensor
Evidence level: Confirmed for country, language, device (API leak fields). Strong inference for metro/location granularity (API feature data examples).
NavBoost doesn't store a single number per page. It stores a multi-dimensional satisfaction profile:

Geographic region. A page can rank well for users in Australia and poorly for users in Canada — same content, different NavBoost profile.
User language. English-language satisfaction and Spanish-language satisfaction are tracked separately, even on the same page.
The API leak confirms mobileSignals stored separately. Desktop and mobile NavBoost profiles are independent.
Metro/city level granularity. A page can satisfy users in NYC on mobile but fail in rural Montana on desktop.
This means optimization must be device-specific and location-aware. A site targeting US English on desktop has a different NavBoost profile than the same site targeting UK English on mobile.
The Statistical Distribution Layer
At the host/domain level, Google tracks the complete statistical distribution of engagement:
mean, medianCentral tendency of satisfaction across all pages. This is your site's "average engagement grade" — the baseline Google uses to understand your overall quality level.
pc10, pc25, pc75, pc90Percentile distribution — where your worst and best pages sit. A high pc90 means your best pages are excellent. A low pc10 means your worst pages are dragging the entire distribution down.
stddev, varianceConsistency of quality. High variance = inconsistent site. Google doesn't just care about your average — it cares about how far your worst pages deviate from your best.
This is where the real damage happens. If your site has 50 pages with excellent engagement but 200 pages with terrible engagement, Google sees high variance, low percentiles dragging the distribution, and 200 bad pages mathematically overwhelming the 50 good ones. This is the mechanism behind what happened to HubSpot — topical dilution across thousands of pages shifted the statistical distribution, and group-based quality scoring (US10055467B1) ensured those bad pages dragged the good ones down.
The 13-Month Memory Window
Pandu Nayak testified that NavBoost memorises "quite literally all of the data" from the last 13 months. Why thirteen and not twelve?

Thirteen months deletes seasonality. If you only use five months of data, you might be evaluating a travel site during the off-season. Thirteen months gives you one full seasonal cycle plus one buffer month — enough to account for the fact that March 2019 and March 2020 were very different months in the travel industry, even though seasonality alone wouldn't tell you that.
During the antitrust trial, the DOJ established that the volume of click data Google collects in 13 months is equivalent to over 17 years of data at Bing's scale. This was the entire point of the antitrust case — is Google too big? And here was the answer: their data advantage is so enormous that the next competitor would need nearly two decades to match what Google collects in a single year. The 13-month window isn't just a design choice — it's a competitive barrier that compounds with every query Google processes.

But storing 13 months of data doesn't mean applying all 13 months equally. If your LC ratio was 0.1 for twelve months and you fix everything, bringing it to 0.9, the system can't weight the twelve bad months equally against the one good month — that would make the system too punitive to be useful. Fresh positive data likely receives higher weight than stale negative data.
I've never seen a case where you have to wait six, seven, or eight months for NavBoost to "forgive" a site that has genuinely fixed its engagement problems. The recovery, in isolation, is faster than the 13-month window would suggest.
Speed as NavBoost Gateway
Evidence level: Practitioner observation from ~2,000 verified GSC accounts, supported by patent mechanism and API attributes.
Google's own documentation states that Core Web Vitals are used by its ranking systems. But the larger SEO impact of CWV is probably not as a standalone score. Let me be precise about what I think actually happens: CWV influences whether users can load, read, and stay long enough to form honest opinions — which influences NavBoost, which influences the re-ranking algorithm, which ultimately influences rankings. You move this lever and the engine works differently. This is more nuanced than most guides acknowledge — and getting the mechanism wrong leads to the wrong fixes.
Time to First Byte: The Real Lever
From approximately 2,000 verified Search Console accounts: the number of sites that hit 200 milliseconds or lower on Time to First Byte, I can count on both hands how many were already there when I first opened their Search Console.
Go to Google Search Console → Settings → Crawl Stats → top-right unit (the orange chart). Whatever number you see, reduce it to 200 milliseconds or lower. In my own verified GSC dataset — approximately 2,000 accounts over ten years — reducing TTFB to that level has consistently coincided with ranking improvements, often within a day. I treat it as one of the highest-leverage technical fixes available.
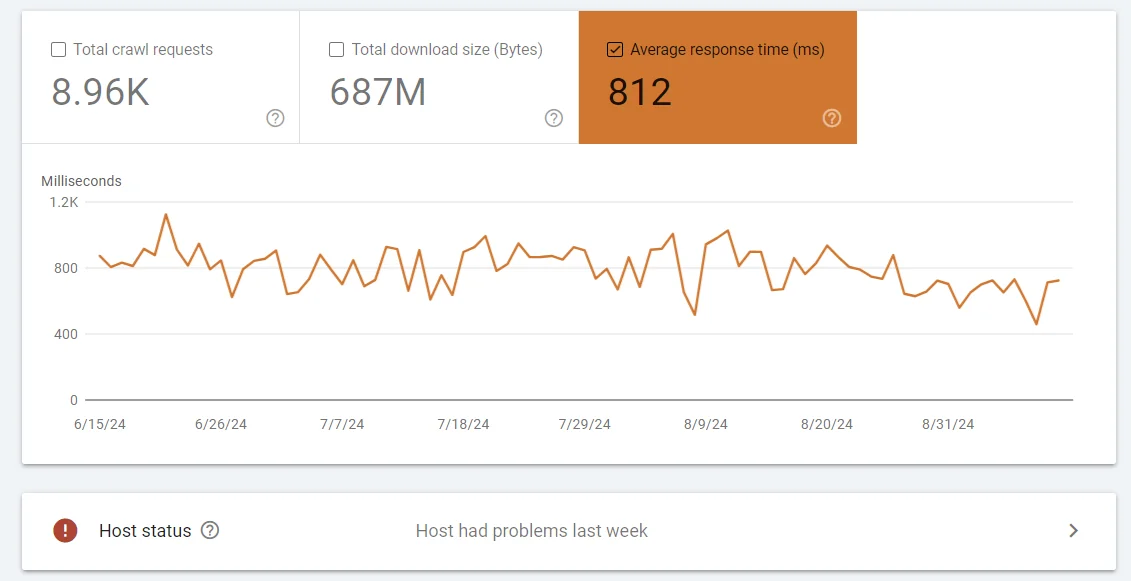
The mechanism is very straightforward: Informational Gain divided by Cost of Retrieval.
Informational gain is the quality of your content — how much genuine, structured, parsable information the page provides. Cost of retrieval is dominated by one factor: how long the page takes to respond. Speed is money. If your site takes 1.5 seconds to deliver the page with all the information Google needs to answer a query, that's the equivalent of taking a month and a half to answer a phone call.
When you reduce TTFB from 700ms to 70ms, something immediate happens at the crawler level: "Oh, I can fetch all these pages now for a lot cheaper." Your crawl budget increases. And since making a site genuinely fast requires changing the HTML output — prefetching fonts, lazy-loading images, compressing CSS — you're also changing your SEO, because the moment you change your HTML output, you are changing your search engine optimisation.
The Reverse Evidence
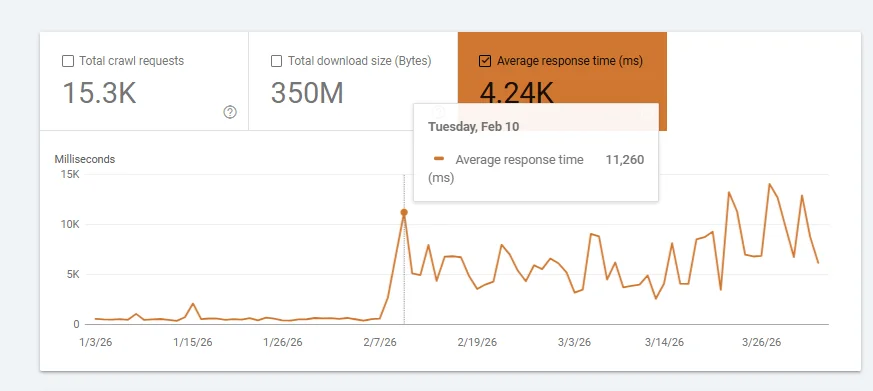
Sites that migrate to slower hosting see traffic drops of greater than 75% — the same day. I've watched it happen. The new hosting is a "much better" package deal: hosting and SEO and PPC and everything for one monthly fee. Of course, the hosting is shared infrastructure with hundreds of other sites running poorly-developed plugins that consume bandwidth. Every site on that server is slow, and the rankings reflect it immediately.
Two NavBoost Connections
If Google knows (via Chrome data) your site takes 3 seconds to load for a user on a 3G connection with a low-spec device, your site won't even load for that user. You won't just lose the click — you'll lose the impression entirely. You will be positioned nowhere for that user. This means you get less click data, which is bad for NavBoost, and you miss that user altogether. You can't convert someone who doesn't know you exist because you're too slow.
If your page loads in 6.5 seconds, the user bounces before they've even seen your content. NavBoost records a badClick — not because the content was bad, but because they never saw it. Passing CWV means users can form honest opinions about your content. You can qualify for 100% of the available click data.
You Can Cheat Core Web Vitals (But You Shouldn't)
Here's the thing: Lighthouse tests can pass with flying colours while the site is still slow. There are ways to make the test look good while the real user experience remains poor. If your site passes Core Web Vitals but the time to first byte is anything higher than 600 milliseconds, ask your developer why. The score on the test means nothing by itself — what matters is whether the real problems have been fixed.
Core Web Vitals only matter as a measurement of the real things being done to make the site work for actual humans. The score is not the point. The experience is the point.
Content Architecture as NavBoost Optimization
Evidence level: Strong inference — API attributes (clutterScore, onsiteProminence) confirmed; their NavBoost connection is inferred from functional overlap.
Every structural decision on your website — the number of items in your navigation, the topical scope of each page, how your content is organised — is a NavBoost decision. Not because Google reads your sitemap and assigns points, but because these decisions determine what users do when they arrive.
MECE Content Architecture
The McKinsey MECE principle — Mutually Exclusive, Collectively Exhaustive — applied to content architecture is a NavBoost optimisation strategy:
Each page covers one topic scope. No overlap. Users who land on a specific page don't need to check three other pages on the same site for the same answer. One page, one answer, one satisfied click.
The full set of pages covers the entire topic space. Whatever the user's question within your domain, there IS a page that answers it. No gaps, no "we don't have that" bounces.
MECE architecture structures your site so that users are far more likely to land on the right page and stay. That's a goodClick. Non-MECE content means users land on a partial answer, bounce to another page on the same site, or worse — return to the SERP and click a competitor. That's a badClick, and the competitor gets the lastLongestClicks signal.
Combined with a Bottom Line Up Front (BLUF) structure, MECE pages can produce short-but-satisfied dwell times. This works because of category-relative dwell scoring (US9514194B1) — Google compares your dwell time within content category, not globally. A 45-second visit to an emergency locksmith page is excellent. A 45-second visit to a comprehensive research guide is terrible.
Navigation Architecture: The 30→15 Play
Every navigation click within a site is potentially observable via Chrome user data. If a user clicks from the SERP to your site, then clicks three navigation items before finding what they want — that's a different signal profile than landing on the right page immediately.
The API leak reveals two attributes that connect navigation to NavBoost:
onsiteProminence— simulated traffic from homepage and high-click pages. This metric tracks internal navigation patterns. Fewer items in the main nav means each remaining item gets MORE navigational signal.clutterScore— excessive navigation elements increase clutter, which correlates withbadClicks. A mega-menu with 30 items is clutter. A focused navigation with 15 items is clarity.
Case Study: GetMeLinks.com Navigation Rebuild
A mega-menu with ~30 navigable items across three columns (8 link building products, 12 industry verticals, 3 other SEO services). Plus five buttons on the homepage fold and a 10% discount popup.
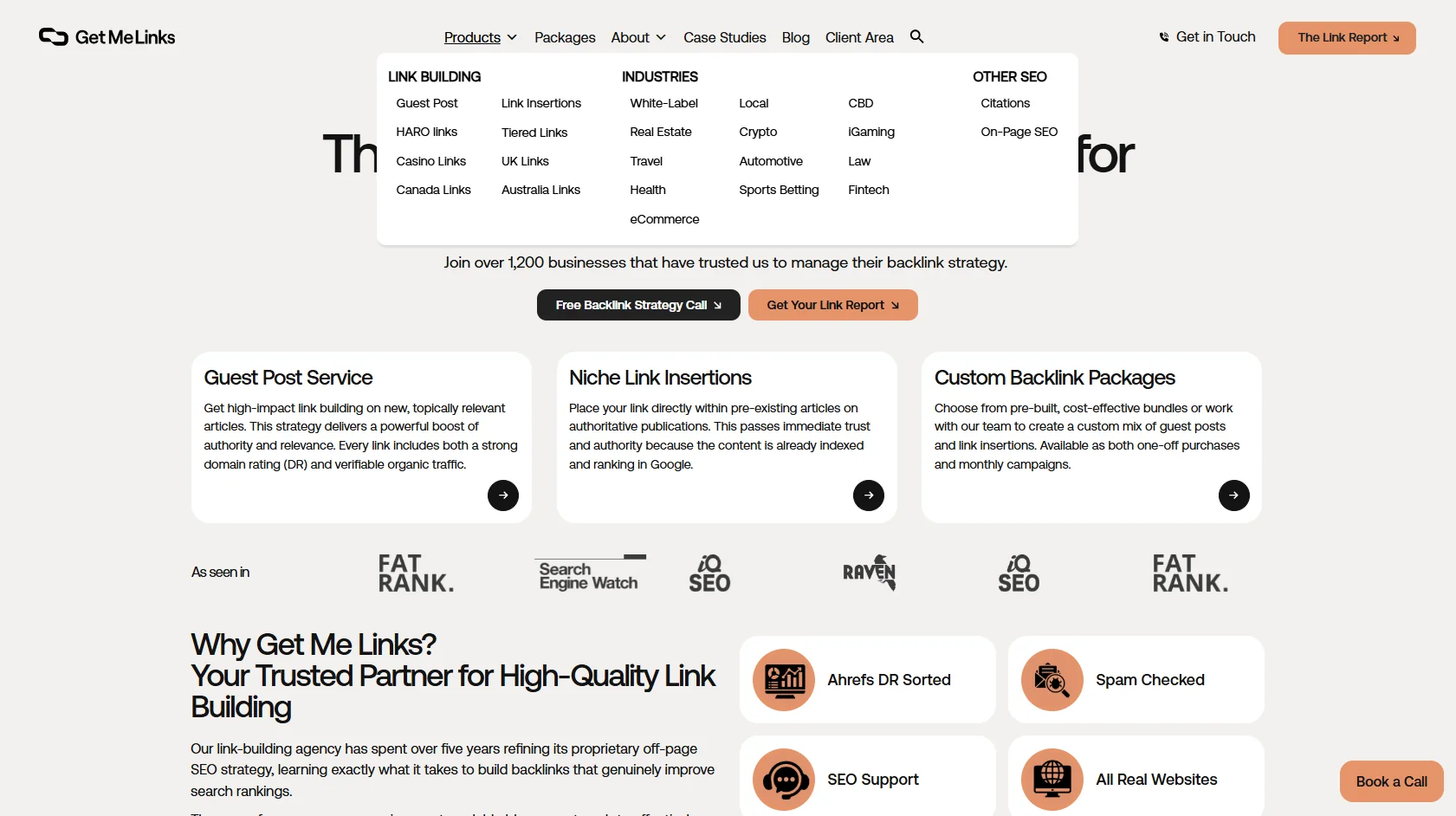
A focused navigation with ~15 items across three clean dropdowns (Services: 6, Results: 2, Learn: 4). Zero buttons on the fold. Zero popups. One clear CTA.
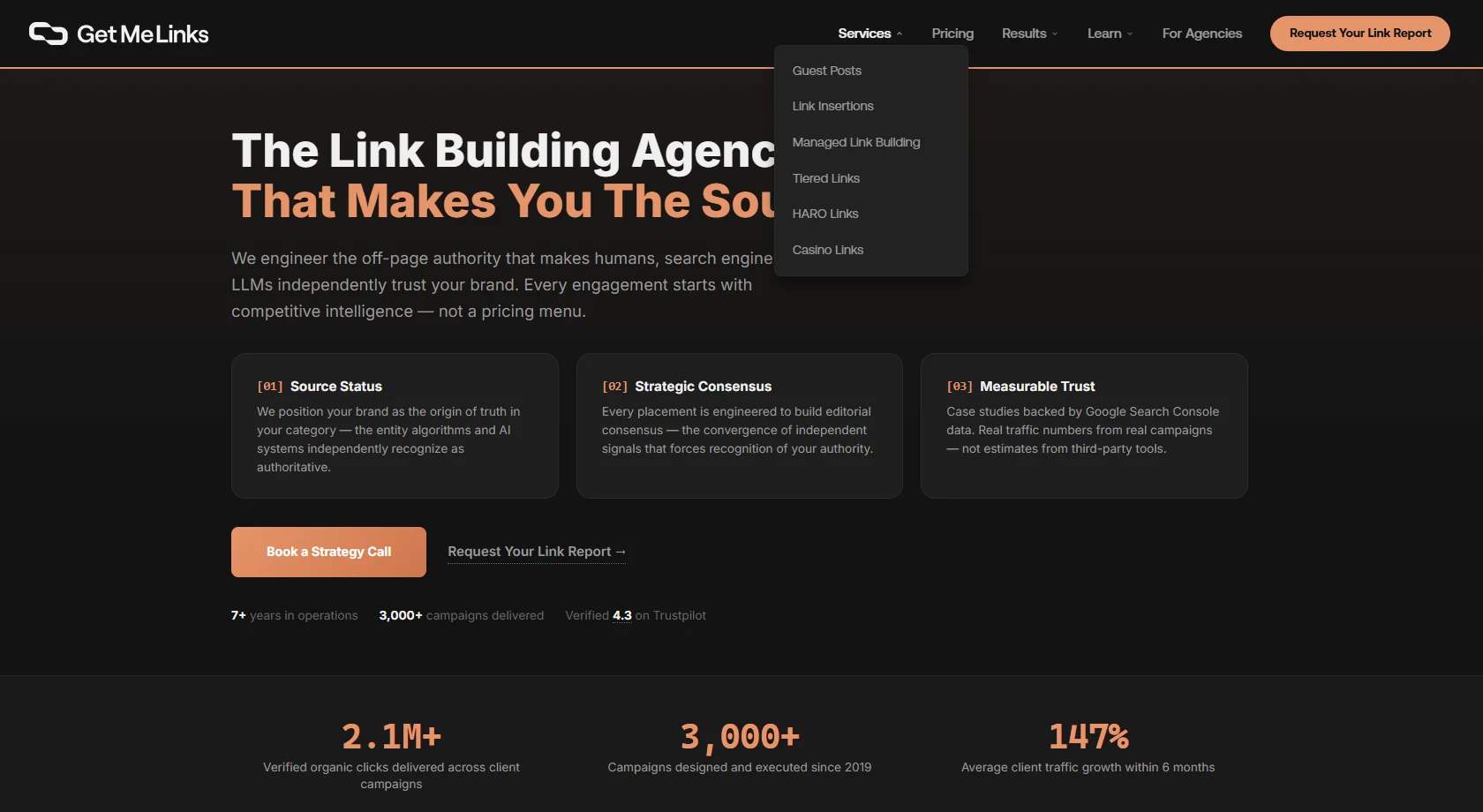
The math: 30 items means decision paralysis. The user doesn't click, dwells briefly on the homepage in confusion, and either bounces or fumbles through irrelevant pages. That's noise in the statistical distribution. 15 items means clear choices. The user navigates, finds content, stays. Each remaining page gets stronger onsiteProminence signal because it's not competing with 15 other pages for navigation attention.
The Brand Signal Amplifier
From the Panda patent, site quality incorporates branded search volume:
Brand searches generate navigational queries where NavBoost operates differently. When someone searches "GetMeLinks" and clicks the homepage, that's a navigational query with expected short dwell — the user found what they wanted quickly. NavBoost uses the Viewing Length Differentiator for navigational queries, meaning shorter dwell is acceptable and even positive.
High brand search volume creates a positive feedback loop: more navigational queries → more navigational satisfaction → better NavBoost profile → higher rankings → more brand awareness → more brand searches. This connects Brand SEO directly to NavBoost mechanics.
The Most Dangerous Thing About NavBoost
Evidence level: Practitioner synthesis — editorial interpretation grounded in confirmed evidence from prior sections.
The most dangerous thing about NavBoost isn't getting the mechanism wrong. It's ignoring it entirely.
An internal Google email described NavBoost as "more positive on clicks by itself than the rest of ranking." Google had an internal policy telling employees not to discuss it publicly. And yet: the majority of the SEO industry's attention is currently focused on how to manipulate AI Overviews.
A lot of the attention in the industry goes to whatever is hot in the minds of prospects so that services can be sold to them, and not to whatever actually influences rankings. You can very clearly tell who belongs to the "I must know how this works and I must rank this website" camp versus the "I must be relevant in the conversation that's being had right now so that I can sell my services" camp.
NavBoost is in the first camp. It's not new. It's not trendy. It doesn't have a SaaS dashboard. But it's one of the most important signals in the ranking infrastructure, and most competent SEOs with a decade of experience either don't know it exists or have never read the patent.
NavBoost Is Machine Learning
A common critique is that patents describe how a system could work, not how a modern ML-driven system currently works. But here's the thing: NavBoost is machine learning. What does the machine learn? It learns that this result gets clicked more, gets dwelled on longer, produces more engagement signals — and it uses those patterns to determine that a higher-satisfaction page should be placed above a lower-satisfaction page.
That's the exact same fundamental principle behind Google's content quality classifier. 16,000 human raters evaluate pages against the 176-page Quality Rater Guidelines. Those ratings don't directly affect rankings — they train a machine learning model that can replicate those judgments at scale. One ML system evaluates the page at discovery, based on its content. The other — NavBoost — evaluates the page after it meets real users, based on what those users actually do. Pre-ranking quality is learned from raters. Post-ranking quality is learned from clicks. Both are machine learning. NavBoost isn't some legacy system running alongside modern ML. It is modern ML — the version that learns from the real world instead of from a training set.
The Economics of Manipulation
People ask me whether click manipulation works. The answer is nuanced, and it's niche-dependent.
Sophisticated manipulation can work. Server rooms with thousands of physical devices, aged Google accounts, rotated residential IPs, VPNs for geo-targeting, all running 24/7 — those operations exist. I've seen videos of them. I've known people who run them. They are real, and they are primarily deployed in industries where the unit economics justify the infrastructure: online casino, pharma, adult content. When the difference between position 3 and position 2 is five million dollars a month, the calculus changes entirely.
But you're not going to find that being done for a dentist in Tallahassee. A thousand physical devices, a thousand aged accounts with real activity history, a thousand residential proxies, and the infrastructure to orchestrate all of it — that costs serious money. The industries where click manipulation is economically rational are, by nature, industries where everything goes — and they are not the industries this guide is written for. If you're reading this site, you're most likely operating in what I'd call kosher niches: legitimate businesses where the competition is won on substance, not on who has the most sophisticated manipulation operation. In those niches — which is the vast majority of the SEO market — the cost of building and maintaining a manipulation operation genuinely exceeds the cost of doing the work properly.
The patent's anti-spam safeguards don't need to be perfect. They just need to make manipulation expensive enough that the honest path is cheaper — and for the niches where honest practitioners operate, they do.
The One Test That Matters
If you read this entire guide and walk away ready to make one change, here it is.
Open your website in incognito. Fresh browser. No cache, no cookies. Let it load with completely fresh eyes — and try to hate it.
Can you? If you can, most likely any user who has never seen your site before and doesn't know where things are will be frustrated.
Fix that thing. Then do it again. Keep digging until you can no longer find anything that could potentially be making your site harder to use than it needs to be.
Now think about it this way. Imagine a business owner who just got an email from their partner on a Sunday afternoon: our organic traffic is down. They're panicking about Monday because if organic is down, sales follow — and they're about to make a big business move that depends on that revenue. So they pull out their phone and start looking for an SEO agency. Right now. On their phone. On a Sunday.
Can that person use your site? Can they find what you do? Can they tell within seconds that you're competent? Can they book a call for Monday morning — without a popup blocking their view, without a chatbot opening in the corner, without a background video that takes seven seconds to load while the button they were about to click shifts to a different position on the page? All they need is one thing: a simple site that works, where they can quickly confirm yes, these people look like they know what they're doing, and book a call. Please — please — don't give them a difficult website.
Now picture the other end. A marketing manager has had three months of internal discussions about whether to pursue organic traffic for a new market expansion. The CMO has finally approved the budget. It's a Tuesday afternoon. They've opened their project management tool, ticked a box that says "Research link building providers," and they're methodically working through the task — YouTube reviews, Reddit threads, agency websites, ChatGPT for a shortlist. Controlled office environment. Full attention. Zero stress. They're building a dossier: this is who I want to work with, this is what they do, this is how much they charge.
Those two people will have fundamentally different experiences on your website — and they're looking for fundamentally different information. The Sunday-night business owner needs confidence and a booking button. The Tuesday-afternoon researcher needs depth, proof, and pricing. They both exist in your analytics. If your site is designed to work only under ideal conditions — the Tuesday afternoon researcher, the high-attention desktop session — you are failing every single person who doesn't fit that profile. And NavBoost is recording every one of those failures.
I find it funny — and a little sad — that one of the most important re-ranking signals in Google's entire infrastructure comes down to something this simple. Not a formula. Not a framework. Just: can a real person use your website when they need it most? Twenty years of patent engineering, thirteen months of memorised click data, seven connected production systems — and the answer to all of it is whether your site works for someone who's stressed, distracted, and holding a phone.
You cannot circumvent the work. But if the work is good, and the people building it actually care about the humans on the other side? That's when things compound.
The NavBoost Checklist
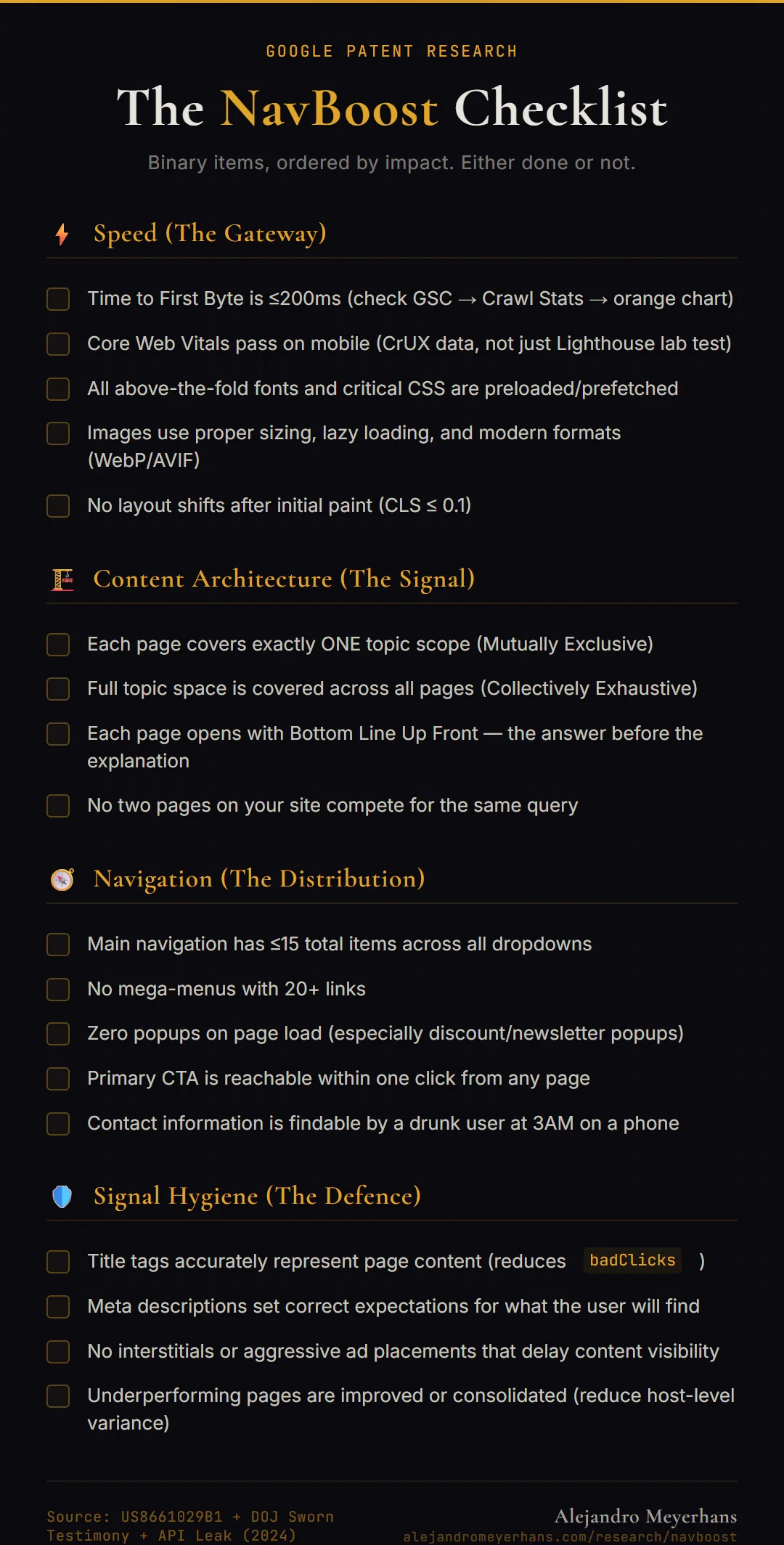
Binary items. Either done or not. Work through these from top to bottom — they're ordered by impact.
Speed (The Gateway)
- [ ] Time to First Byte is ≤200ms (check GSC → Settings → Crawl Stats → orange chart)
- [ ] Core Web Vitals pass on mobile (CrUX data, not just Lighthouse lab test)
- [ ] All above-the-fold fonts and critical CSS are preloaded/prefetched
- [ ] Images use proper sizing, lazy loading, and modern formats (WebP/AVIF)
- [ ] No layout shifts after initial paint (CLS ≤ 0.1)
Content Architecture (The Signal)
- [ ] Each page covers exactly ONE topic scope (Mutually Exclusive)
- [ ] Full topic space is covered across all pages (Collectively Exhaustive)
- [ ] Each page opens with Bottom Line Up Front — the answer before the explanation
- [ ] No two pages on your site compete for the same query
Navigation (The Distribution)
- [ ] Main navigation has ≤15 total items across all dropdowns
- [ ] No mega-menus with 20+ links
- [ ] Zero popups on page load (especially discount/newsletter popups)
- [ ] Primary CTA is reachable within one click from any page
- [ ] Contact information is findable by a drunk user at 3AM on a phone
Signal Hygiene (The Defence)
- [ ] Title tags accurately represent page content (no bait-and-switch → reduces
badClicks) - [ ] Meta descriptions set correct expectations for what the user will find
- [ ] No interstitials or aggressive ad placements that delay content visibility
- [ ] Pages that consistently underperform are either improved or consolidated (reduce variance in host-level distribution)
Frequently Asked Questions
What is NavBoost and how does it work?
NavBoost (internally codenamed CRAPS) is Google's system for re-ranking search results based on user click behaviour. It tracks every click on a search result, measures dwell time, applies a weighting function, calculates an LC (Long Click) ratio for each query-document pair, and feeds that ratio into the ranking algorithm via IRBoost. Under sworn DOJ testimony, Google confirmed it stores 13 months of click data. An internal Google email entered into evidence described it as 'more positive on clicks by itself than the rest of ranking.'
Does Google really use clicks to rank websites?
Yes. Google denied this publicly for years, and even had an internal policy instructing employees not to discuss it. During the United States v. Google LLC antitrust trial, VP of Search Pandu Nayak confirmed under oath that NavBoost memorises all clicks for the last 13 months and that NLP systems like BERT do not replace it.
Do Core Web Vitals directly affect rankings?
Google states that Core Web Vitals are used by its ranking systems, but their larger SEO impact is probably indirect. CWV acts as a gateway to NavBoost — they determine whether users can load, read, and stay long enough to generate honest satisfaction data. A page that takes 6 seconds to load produces a badClick not because the content is bad, but because the user never saw it. Fixing CWV means NavBoost can collect accurate data.
How long does NavBoost store click data?
13 months, confirmed under sworn DOJ testimony. This window is likely designed to eliminate seasonal bias — one full cycle plus one buffer month. Fresh positive data likely outweighs stale negative data, meaning sites that genuinely improve their engagement can recover faster than the window would suggest.
Can you manipulate NavBoost with click bots?
Headless browser manipulation doesn't work for NavBoost — not because of Cloudflare or bot detection, but because NavBoost weights clicks by account trust. You need to be logged into Chrome with a Google account that has real history — years of YouTube activity, Gmail, Maps, Android device pings. A headless browser with no logged-in account, or a freshly created account with no history, produces clicks that carry zero or near-zero weight in the NavBoost ledger. Sophisticated operations using thousands of aged, active Google accounts on physical devices can work, but those exist almost exclusively in industries where the unit economics justify it: casino, pharma, adult. For the vast majority of niches, the cost of that infrastructure exceeds the cost of doing genuine SEO.
What is the single most impactful thing I can do for my NavBoost signals?
Reduce your Time to First Byte to 200ms or below. Check it in Google Search Console under Settings, Crawl Stats. From approximately 2,000 verified accounts I have worked with, fewer than 10 were already at that level. In my field data, reducing TTFB to 200ms or below has consistently coincided with ranking improvements — often within a day.
How does navigation architecture affect NavBoost?
Every navigation item on your site is a potential destination that affects your host-level engagement distribution. Thirty menu items means decision paralysis and noise in your statistical profile. Fifteen focused items means clear choices and stronger onsiteProminence signal. Google tracks clutterScore and onsiteProminence — both directly affected by navigation architecture.
Citation Network
This deep dive synthesizes multiple primary sources into a production-level theory. The following resources on this site provide the forensic detail behind each evidence layer:
Related Research on This Site
- US8661029B1 — NavBoost Patent Analysis — The foundational patent mechanism: LC ratio, click weighting, three-level aggregation, IRBoost, and anti-spam safeguards. Start here for the mathematical detail.
- US10055467B1 — Group-Based Quality Modification — The host-level quality drag mechanism. Explains why poor pages mathematically pull down good pages through statistical distribution scoring.
- US9767157B2 — Panda Patent Analysis — Site quality scoring, branded search ratio, and the quality gates that determine NavBoost effectiveness at the domain level.
Primary Source References
- DOJ Antitrust Trial — United States v. Google LLC, Case No. 1:20-cv-03010 (D.D.C.). Testimony of Pandu Nayak, VP of Search. Proposed Findings of Fact at ¶¶207, 214.
- API Leak (2024) — Google's internal Content API documentation. Containers:
CrapsData,CompressedQualitySignals,NSR. - Patent Chain — US8661029B1 (anchor), US9235627B1, US9811566B1, US10229166B1, US11188544B1, US11816114B1. Companion: US8938463B1 (position bias), US9229989B1 (speed), US10055467B1 (group quality).