Jeffrey Dean — the engineer behind MapReduce and TensorFlow — co-authored a patent that explains why pruning bad content from your site improves the rankings of your good content. Not metaphorically. Mathematically.
This patent describes group-based quality modification — a system where Google evaluates engagement signals at the host or domain level, then applies a single modification factor to every page on that host. The mechanism uses sigmoid functions that can reduce a page's score to as low as 10% of its original value. It's the mathematical proof behind what practitioners call "host-level quality drag." For how this connects to the broader click-based ranking architecture, see the NavBoost deep dive.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- The Repeat Click Fraction (RCF) formula is explicitly described: RCF = RC / UC, where RC = repeat clicks across sessions, UC = unique clicks
- The Deliberate Visit Fraction (DVF) formula is explicit: DVF = DV / SRV, where DV = direct navigations, SRV = search result visits
- Sigmoid functions map these fractions to modification factors between a base value (as low as 0.1) and 1.0
- The combined modifier M = (S_RCF(RCF) + S_DVF(DVF)) / 2 is applied as a multiplicative factor to initial scores
- Navigational queries are exempt — the system does not modify scores for queries navigational to the resource
- Resources are grouped by host name or domain name (address-based grouping)
- Patent is active — M1551 (yr 4) and M1552 (yr 8) maintenance fees paid
- The
pqData(page quality data) container in the API leak is a strong candidate for carrying group-based quality signals - The
siteQualityattribute likely incorporates some form of group-level engagement aggregation - HubSpot's 2024 traffic decline is consistent with this mechanism — topical dilution across thousands of pages shifted the statistical distribution
- The navigational query exemption explains why branded searches maintain rankings even when overall site quality degrades
- The exact sigmoid parameters (base values, inflection points, steepness) used in production
- Whether the system now uses neural approaches to learn these functions rather than hand-tuned sigmoids
- How finely Google segments "groups" — is it strictly by host, or by URL path sections?
- The relative weighting of RCF vs. DVF vs. average duration vs. group-specific query metric in the final modifier
Patent Metadata
The inventor list tells the story: Jeffrey A. Dean is a Google Senior Fellow — the engineer behind MapReduce, BigTable, and co-lead of TensorFlow. This isn't a niche search patent from a ranking team. This is infrastructure-level work from one of the most senior engineers in Google's history. The original application was filed on December 31, 2012 — the same year Google rolled out a series of Panda updates that hammered sites with thin content sections. This patent describes the mechanism behind that quality drag.
Notable in the backward citations: this patent cites US7603350B1 (Entity Trust) — the trust propagation system already covered on this site. Trust graph and engagement graph share infrastructure.
What This Patent Does (Plain English)
Google doesn't evaluate every page in isolation. This patent describes a system that evaluates groups of pages — typically all pages on the same host or domain — and computes a single quality modifier for the entire group. That modifier is then applied to every page in the group.
Here's what the system does:
- Group resources by host — All pages sharing the same domain or host name are placed in the same group
- Measure repeat clicks — Track how often users return to the same result for the same query across different search sessions. Compute the Repeat Click Fraction (RCF)
- Measure direct visits — Track how often users navigate directly to the site (bookmarks, typed URLs) versus arriving through search results. Compute the Deliberate Visit Fraction (DVF)
- Measure dwell time — Compute an average duration metric across all clicks on the group, capped at a maximum (5–60 minutes)
- Compute modification factor — Pass RCF and DVF through sigmoid functions, combine them into a single group-based modification factor M between a base value (as low as 0.1) and 1.0
- Apply to every page — Multiply each page's initial score by a resource-specific modification factor derived from M
The result: if your domain has strong repeat engagement and direct visits, the modifier approaches 1.0 (no change). If your domain has poor engagement, the modifier drops — potentially to 0.1, meaning every page on your domain has its score reduced to 10% of its original value.

Let me translate that to human.
↓
Think of it like a restaurant review system, but for entire chains. If McDonald's has 100 locations and 70 of them get bad health inspections, the health department doesn't evaluate each location independently — the chain's track record affects how every location is scrutinised. This patent does the same thing for websites. Your domain is the chain. Your pages are the locations. If most of your "locations" have bad engagement, the health inspector arrives at your good pages with prejudice already built in.
The Repeat Click Fraction: Core Signal
The most important formula in this patent:
RCF answers one question: "Do users come back?" If someone searches for "best CRM software," clicks your page, and then two weeks later searches the same thing and clicks your page again — that second click is a repeat click. A high RCF means your site is the kind of site people return to. A low RCF means people try you once and move on.
What counts as a repeat click: the same user must click on a search result identifying the same resource, in response to the same query (exact text match), during a different search session (time between clicks exceeds a predetermined threshold). Only one repeat click per user is counted — if a user clicks the same result for the same query across three sessions, only the second click counts as a repeat; the third is discarded.
What counts as a unique click: a click by a user who has never previously clicked on any search result in the group. One click per cookie or login identifier per group — ever.
The system then passes RCF through a sigmoid function S_RCF that outputs a value between a base value (as low as 0.05 or 0.1) and 1.0. A high RCF (many users returning) → modifier approaches 1.0 → no penalty. A low RCF (users try once and never return) → modifier drops toward the base value → scores reduced by up to 90%.
Why This Matters
This mechanism rewards what practitioners call "stickiness" but measures it at the host level. Your best content page might have excellent repeat engagement — but if 80% of your other pages have users who click once and never return, the group-level RCF drags everything down.
I've seen this play out with clients who publish high-volume blog content alongside their core service pages. The blog posts — often thin, keyword-targeted pieces — generate thousands of one-and-done clicks. Users search, click, scan, leave, never return. Each of those zero-repeat-click pages is dragging the RCF denominator up while contributing nothing to the numerator. The fix isn't always "write better blog posts." Sometimes it's "delete the blog posts that nobody comes back to."
This patent was originally filed in 2012 and describes sigmoid-based group quality modification. By 2026, the production system likely uses learned functions rather than hand-tuned sigmoids. The core architecture — measuring engagement at the host level and applying modifiers to individual page scores — remains operationally confirmed through the API leak and DOJ testimony. The specific mathematical formulas have likely evolved; the principle of group-level quality drag has not.
The Deliberate Visit Fraction: Brand Trust Proxy
DVF answers: "Do people seek you out, or do they only find you through Google?" If your traffic is 90% from search and 10% direct, Google knows you're a search-dependent site. If it's 50/50, Google knows people type your URL into their browser — they trust you enough to go directly. That trust gets mathematically rewarded.
A deliberate visit is defined as a request initiated by a user directly inputting the URL or selecting a saved bookmark. A search result visit is a request initiated by clicking a search result. The DVF measures how much of your traffic arrives because users choose your site rather than discovering it through search.
This is effectively a brand trust metric at the host level. Sites with high direct navigation relative to search traffic receive a more favourable DVF modifier. The patent explicitly describes combining the DVF and RCF through their respective sigmoid functions:
The patent also describes weighted variants: M = min(w · S_RCF(RCF) + (1-w) · S_DVF(DVF) + w · S¹_RCF(RCF), 1), where w controls the relative importance of repeat clicks vs. direct visits.
The sigmoid function acts like a dimmer switch, not an on/off switch. Your site doesn't suddenly go from "fine" to "penalised." As your engagement metrics drop, the modifier gradually dims — from 1.0 (full brightness) toward 0.1 (10% brightness). The patent averages two dimmer switches: one for repeat clicks, one for direct visits. Both have to be dim for the full quality drag to kick in.
The patent notes that the repeat click fraction "may be determined to be a better indicator of the quality of a group" or that the deliberate visit fraction may be — it explicitly allows for experimentation with weighting. This is a tunable system.
The Modification Pipeline: From Group Score to Page Score
The system doesn't blindly apply the group modifier to every page. It applies a three-tier threshold system (FIG. 6 in the patent):
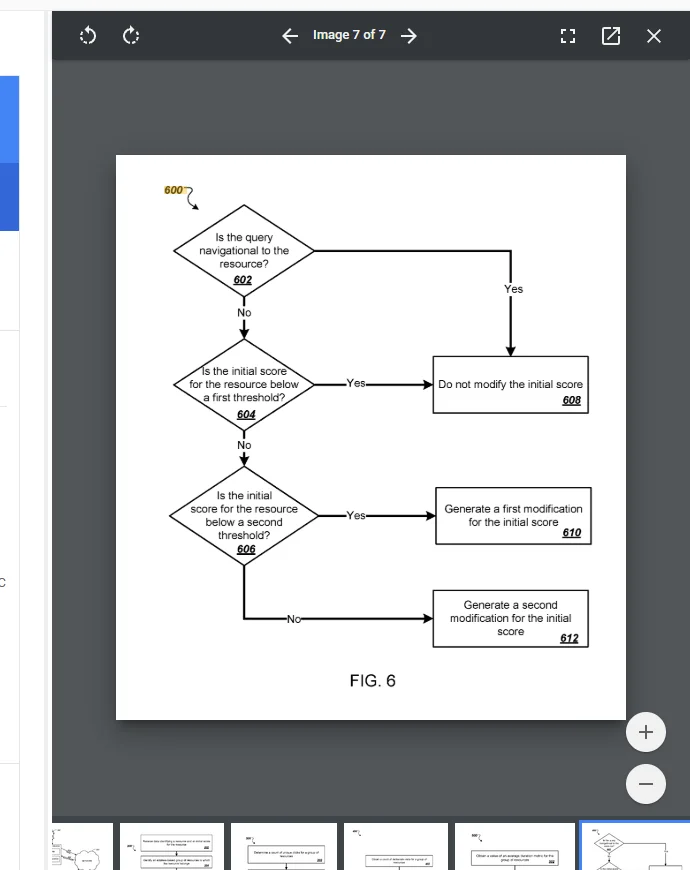
- Below T1 (first threshold, e.g. 0.65) — No modification. Pages already scoring low are left alone. The patent explicitly states: "it may not be desirable to modify the initial score because it is already low."
- Between T1 and T2 (second threshold) — Partial modification using factor f₁ = (T1/IS) × M, where IS = initial score, M = group modifier. The modification ramps up as the page score increases.
- Above T2 — Full modification with smoothing: f₂ = f₁^(log_T2(IS)) × g(f₁), where g(f₁) is a smoothing function that reduces the effect for extreme cases.
The three tiers work like a progressive tax bracket. Pages that already score low aren't touched — there's nothing to take. Mid-range pages get a moderate adjustment. High-scoring pages get the full effect. The system specifically targets the pages that appear to be ranking well but belong to a host with poor overall engagement. If your page is scoring 0.3, the modifier barely matters. If your page is scoring 0.9 and your host modifier is 0.5, your effective score drops to roughly 0.45. The better your individual page, the more you have to lose from poor host-level engagement.
Additionally, the system applies two protective mechanisms:
- Navigational query exemption — If the query is navigational to the resource (e.g., "news event examplesite"), the modification factor is set to 1.0. Branded queries are exempt from group-based quality drag.
- Protection factor — The system computes a GS (group-specific query metric) from site: queries and click diversity: GS = max(s-a, 0)^b / q^c. Combined with average duration, this generates a protection factor that shields sites with strong engagement diversity from excessive modification.
The third protective input is average duration — dwell time per group. The patent specifies that the duration for any given click is capped at a predetermined maximum (5 minutes, 10 minutes, 20 minutes, 30 minutes, or one hour). Combined with the group-specific query metric, this creates the final modification factor M that absorbs all three signals plus the protection factor.
SEO Implications
Content Pruning Has Mathematical Backing
This patent provides the formal mathematical framework for why deleting low-quality content can improve the rankings of remaining content. If a domain has 1,000 pages but 600 of them generate zero repeat clicks and minimal dwell time, the group-level RCF is being dragged down by 60% of the pages. Removing those pages changes the statistical distribution — the RCF rises, the group modifier M improves, and every surviving page gets a higher modified score.
Topical Dilution Is a Mathematical Problem
When a site publishes content outside its core expertise (e.g., a cooking site publishing finance content), the off-topic pages typically have lower engagement — fewer repeat clicks, fewer direct visits, lower dwell time. These pages don't just fail individually. Through this group-based quality mechanism, they mathematically reduce the modification factor for the entire host. This is why NavBoost architecture operates on multiple levels — per-page and per-host.
The Navigational Query Shield
The patent explicitly exempts navigational queries from modification. When someone searches "your brand name + topic," the system sets the modification factor to 1.0. This means brand strength provides a mathematical shield against group-based quality drag. Branded queries always receive the full initial score — only informational queries where the user has no brand intent are subject to the modifier.
Direct Traffic Is a Ranking Signal (Through This Mechanism)
The DVF component means that sites with higher proportions of direct traffic receive a more favourable group modifier. This connects directly to the brand entity work covered in the Knowledge Panel patent analysis and Implied Links patent analysis — brand recognition drives direct navigation, which feeds a better DVF, which produces a better group modifier.
API Leak Cross-Reference
The 2024 API leak didn't expose a field called "groupQuality" by name. But several confirmed attributes align with this patent's mechanism:
| Patent Concept | Likely API Attribute | Evidence Tier | Reasoning |
|---|---|---|---|
| Group-level quality modifier | siteQuality / pqData |
Inferred | pqData contains page quality signals at multiple aggregation levels |
| Host-level engagement | CompressedQualitySignals |
Inferred | Contains host-level quality metrics matching the group concept |
| Repeat engagement patterns | CrapsData (NavBoost container) |
Confirmed (API Leak) | NavBoost captures the same click/dwell data this patent aggregates to host level |
| Direct visit measurement | Chrome usage data | Inferred | Chrome provides direct URL entry and bookmark usage data — the exact inputs this patent needs for DVF |
| Navigational query exemption | isNavigational |
Inferred | Query classification is well-documented; navigational detection is a standard pipeline component |
The key structural insight: NavBoost (US8661029B1) measures engagement per query-document pair. This patent measures engagement per host. They share input data but operate at different granularities — and the outputs feed into the same final ranking adjustment pipeline.
Citation Network
This patent sits at the intersection of trust, engagement, and quality scoring:
Backward Citations (This Patent Cites)
- US7603350B1 — Entity Trust / TrustRank. Trust propagation through links; this patent adds engagement-based trust at the host level.
- US8442984B1 — Related to quality scoring mechanisms.
- US8818838B1 — Scoring systems for search results.
Related Patents in This Research Library
- US8661029B1 (NavBoost) — Per-document click scoring. This patent operates at the host level and feeds the same ranking pipeline.
- NavBoost Deep Dive — Comprehensive analysis including production attributes (
goodClicks,badClicks,lastLongestClicks) and sworn DOJ testimony confirming the 13-month click memory window. - US9767157B2 (Panda) — Content quality scoring at the site level. Panda evaluates content quality; this patent evaluates engagement quality. Both apply group-level modifiers.
- US8682892B1 (Implied Links) — Brand mentions as link proxies. Brand strength drives direct navigation, which feeds DVF in this patent.
- Quality Scoring Ensemble — How all quality signals combine in the final ranking equation.
Group-Based Quality: What Doesn't Matter as Much as SEOs Think
The nature of this patent is that quality is a collective property, not an individual one. Your best page doesn't exist in isolation. It exists on a host, and the host has a reputation built from the aggregate behaviour of every user who visited any page on it.
The flavour — sigmoid functions with hand-tuned parameters — was the 2012 approach. By 2026, the system likely uses learned functions. But the architecture hasn't changed: group resources by host, measure engagement, apply a modifier.
The SEO discourse around "site quality" often focuses on content — thin pages, duplicate content, AI-generated filler. This patent reveals that the actual mechanism is engagement-based, not content-based. Google isn't reading your pages to decide if they're good. It's measuring whether users come back, whether they navigate directly, and how long they stay.
I think about this patent every time I see a site with 50 incredible articles and 500 index-bloating tag pages, archive pages, and thin category listings. The site owner points to the 50 and says "look at the quality." The sigmoid looks at all 550 and says "10% of users came back." The 50 brilliant articles don't save the other 500 — the other 500 drag down the 50. The math doesn't negotiate.
The practical implication: quality improvement programs should be measured by engagement metrics — repeat visit rate, direct traffic ratio, dwell time distribution — not just content audits. The content is the vehicle; the engagement is the signal. Same meal. The recipe changed — the kitchen didn't.
FAQ
What is Google's group-based quality patent US10055467B1?
US10055467B1 describes a system where Google evaluates quality signals — repeat clicks, direct visits, dwell time — at the host or domain level, then applies a modification factor to every page on that host. Poor-quality pages mathematically drag down good pages through a sigmoid function that can reduce scores to as low as 10% of original value.
How does host-level quality drag work in Google's ranking?
Google groups resources by host or domain, measures aggregate engagement signals (Repeat Click Fraction, Deliberate Visit Fraction, average dwell time), passes them through sigmoid functions, and generates a single modification factor for the entire group. This factor is then applied as a multiplier to every page's initial score — meaning one bad section of a site can reduce the ranking potential of all pages.
What is the Repeat Click Fraction in Google's patent?
RCF = RC / UC, where RC is repeat clicks (same user clicking the same result for the same query across different sessions) and UC is unique clicks. A high RCF means users keep returning to your site — a quality signal. A low RCF means users try once and never come back.
What is the Deliberate Visit Fraction?
DVF = DV / SRV, where DV is deliberate visits (direct URL entry, bookmarks) and SRV is search result visits (clicks from SERPs). A high DVF means users navigate directly to your site rather than finding it through search — a proxy for brand trust and site quality.
How does this patent connect to NavBoost?
NavBoost measures engagement per query-document pair. Group-Based Quality aggregates engagement at the host level. They share the same input data — clicks and dwell time — but operate at different granularities. This patent answers: what happens when NavBoost signals are good for some pages but bad for many others on the same host?