The Knowledge Panel Patent
On August 3, 2012, an engineer named Jeromy William Henry filed a patent at Google describing a system for assembling "knowledge panels" — structured information cards displayed alongside search results. Twelve years and six continuations later, Google is still fighting for new claim scope on this exact same patent specification. The most recent continuation, filed in November 2023, received a Final Rejection from the USPTO. Google's attorneys responded. They haven't given up. Ninety-nine other patent families cite this architecture as foundational prior art. This isn't a historical curiosity. This is active intellectual property — and the system it describes determines whether Google shows a Knowledge Panel for your brand, your name, or your business. If you don't understand how this system works, you're building entity authority blind.
If you've read my analysis of the Entity Trust patent, that system measures how much the people behind your content are trusted by others. This patent answers a different question: once Google knows what you are — once you're recognized as a "factual entity" in its systems — how does it decide to display that recognition? Entity Trust is the social graph layer. This patent is the presentation layer. The Knowledge Panel doesn't prove you rank well. It proves Google knows you exist.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- The Knowledge Panel is generated by a dedicated subsystem — the "knowledge panel apparatus" — separate from the search ranking system. It is a presentation mechanism, not a ranking signal.
- KP generation requires identifying a "factual entity" referenced by the query. If no entity is identified, no panel is generated — only standard search results.
- Content for the KP must come from at least two different resources (Claim 1). Multi-source corroboration is a hard requirement, not a preference.
- The system selects an entity-type template (Person, Place, Business, Movie, etc.) with type-specific placeholder slots for content.
- The API leak reveals
KnowledgeGraphTriple(subject → predicate → object),cdoc(reference page list),referencePageIndex(canonical entity page), andconfidence(calibrated precision curve for entity identification). - The inventor — Jeromy William Henry — filed all 6 US applications. Same specification, different claims. All 5 granted patents remain active.
- The API's
confidenceattribute (0.3 = 75% precision, 0.5 = 87%, 1.0 = 98%) likely establishes a threshold for KP generation — entities below a certain confidence level don't trigger panels. Brand SEO's job is to push that confidence score above the threshold. - KG triples (
KnowledgeGraphTriple) are a strong candidate for the "facts" that the patent describes populating templates with — the triple's subject-predicate-object structure maps directly to the structured facts displayed in Knowledge Panels (Born: X, Spouse: Y, Founded: Z). - The
isNegationflag on KG triples suggests Google stores what is NOT true about entities — enabling fact-checking against contradictory claims. The patent does not mention negation. - The rapid continuation filing pattern (5 days after the parent was granted, 8 days before C4 was granted) indicates strategic IP management — Google is building a wall of claims around KP architecture.
- The exact
confidencethreshold that triggers KP generation. The calibrated curve exists; the activation point is unknown. - Whether the ≥2 resources requirement from Claim 1 is still enforced as a strict minimum, or whether the system now uses a probabilistic sufficiency model.
- How much having a Knowledge Panel contributes to ranking improvement in isolation. The patent describes a presentation system, not a ranking system. Entity recognition and ranking are connected — entity confidence feeds into authority scoring — but the KP itself is a symptom of entity recognition, not a cause of ranking improvement.
- Whether the 2024 pending continuation (US20240202224A1) will overcome its Final Rejection.
Patent Metadata

What This Patent Does (Plain English)
Google "Elon Musk" right now. On the right side of the results page, you'll see a structured card — his photo, net worth, companies, family. That's a Knowledge Panel. Now Google your own name. If you don't see one, that's the gap this patent explains. The patent describes the complete system that decides whether to show a panel, which type to use, where to pull the content from, and how to assemble it.
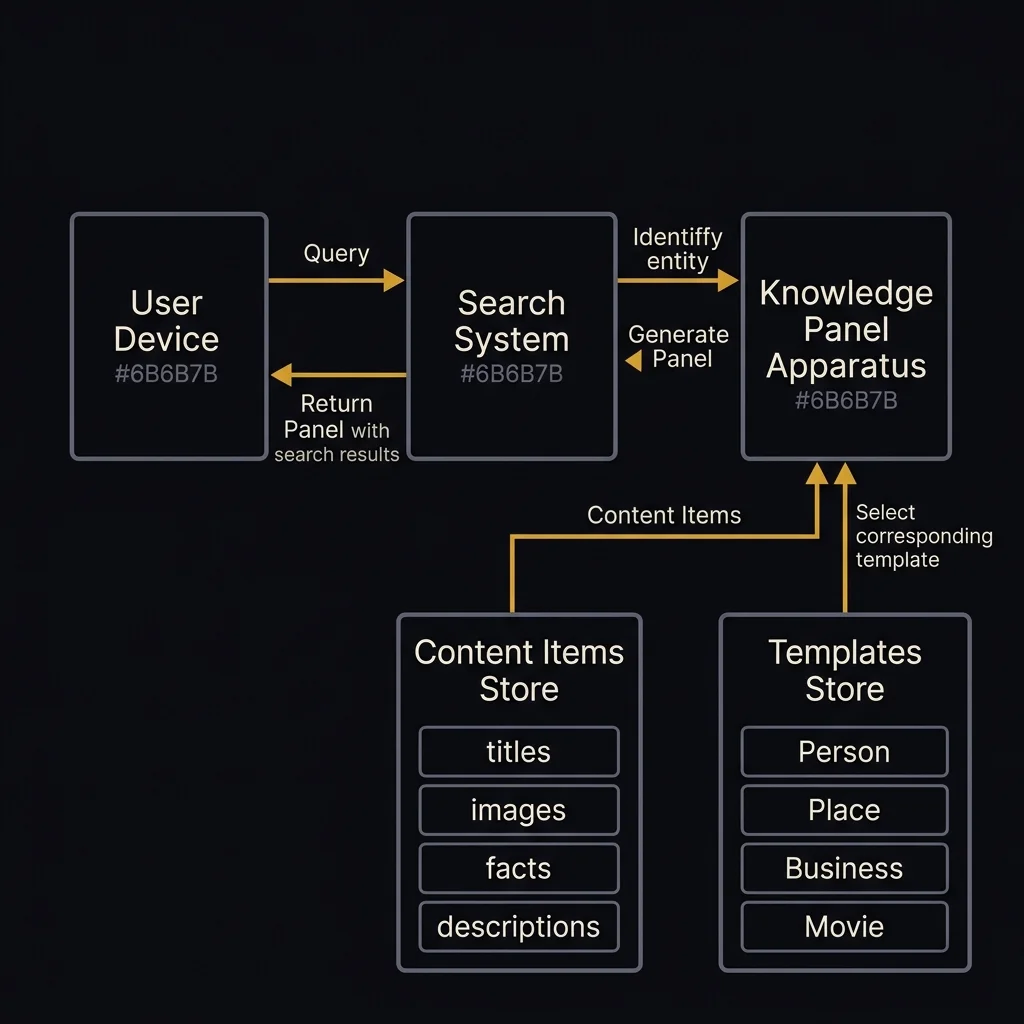
Here's what the system does:
- Receive a search query — and determine whether the query references a known "factual entity" (a person, place, organization, movie, game, or any other conceptual entity stored in Google's systems).
- If no entity match — return standard search results only. No panel. This is the gate.
- Determine the entity's type — Person, Place, Business, Movie, Sports Team, etc. Each type has different content requirements.
- Select a template — from a templates store. Each template has placeholder slots for type-specific content (a Person template asks for name, image, birth date, occupation, works; a Business template asks for logo, stock ticker, leadership, location).
- Aggregate content from multiple sources — pulling from at least two independent publishers (this is in Claim 1). Facts, images, descriptions, and related content are gathered from reference pages.
- Rank the content — using "historical user search events" (how often users have searched for facts about this entity) to determine which facts are most important.
- Assemble and display the panel — alongside the organic search results.

Let me translate that to human.
↓
Entity Recognition: The Gate That Opens Everything
Here's the thing. The most important mechanism in this patent is not the template system, not the fact ranking, and not the multi-source aggregation. It's Step 2 — and it's binary: does the query reference a known factual entity?
The patent describes this as a comparison operation: "the knowledge panel apparatus can determine whether the search query references a known factual entity by comparing one or more terms of the search query to a list of known factual entities." If the term "Ima Singer" appears in the query, the system checks whether "Ima Singer" or an alias of "Ima Singer" exists in the entity database. If there's a match, the KP pipeline activates. If not, only standard search results are returned.
The API leak reveals the infrastructure behind this binary decision. Entity identification isn't actually binary — it's probabilistic:
DetailedEntityScores.confidence in the API leak. Each entity identification carries a calibrated probability — not a yes/no flag. At confidence 0.3, Google is correct 75% of the time. At 1.0, it's 98% certain. The KP trigger threshold is likely somewhere in this range.This has a direct implication for brand SEO: your job is not to "optimize for a Knowledge Panel." It's to increase the confidence score of Google's entity identification for your brand — push it above whatever threshold triggers the panel. You do that by reducing ambiguity, increasing corroboration, and making the entity signal so clear that Google's system reaches high-precision identification.
This patent was filed in 2012. The entity identification described here — comparing query terms to a "list of known factual entities" — was the 2012-era approach: string matching against a database lookup. In 2026, entity identification likely runs on transformer-based models that understand semantic meaning, not just exact string matches. The concept — does this query map to a known entity? — is permanent. The mechanism has likely evolved from database lookups to neural entity linking. The confidence calibration curve in the API leak suggests the current system outputs probabilistic scores, not binary matches — consistent with ML-based entity resolution rather than the deterministic string comparison the patent describes.
The patent also handles disambiguation — when a query maps to multiple entities. "Phoenix" could be the city, the mythical bird, the band, or the NBA team. The system considers other terms in the query to narrow the match. If the query is "phoenix Arizona," the city wins. If it's just "phoenix," the system may generate a disambiguation panel showing multiple entities. The API confirms this with isDisambiguationPage — an explicit flag for pages that serve as disambiguation resources.
I don't have a Knowledge Panel. At the time of writing — April 27, 2026 — if you Google "Alejandro Meyerhans," you get a list of pages about me, but no structured Knowledge Panel card on the right. I'm writing this article about the system that determines whether I get one. The irony is intentional. I know what the patent says needs to happen: my entity needs to exist in Google's Knowledge Graph with sufficient confidence, corroborated by at least two independent sources, with a designated reference page. My about page on this site is my Entity Home — the "Source Document" in Jason Barnard's framework. The GetMeLinks about page is the second source. Both need schema:sameAs cross-references pointing to each other and to any third-party corroborating profiles. This article is me building in public.
Entity-Type Templates: The Blueprint System
Once the system identifies an entity, it needs to decide what kind of panel to display. A panel for a person looks nothing like a panel for a movie, which looks nothing like a panel for a sports team. The patent describes this through a template selection system.
Let me show you what that looks like. The patent lists seven distinct template types, each with specific placeholder slots that determine what information Google looks for:
| Entity Type | Template Slots | Example Content |
|---|---|---|
| Person | Name, image, description, facts (born, occupation, net worth), social feed, works | "Famous Actor" — filmography, awards, birth date |
| Place / Country | Name, map, description, facts (population, capital, GDP), images | "Australia" — flag, landmarks, demographics |
| Landmark | Name, map, description, facts (location, height, year built), visitor images | "Eiffel Tower" — location, visiting hours |
| Business / Organization | Logo, description, stock element, leadership images, map, external links | "Big Business" — stock ticker, CEO, headquarters |
| Movie | Poster, description, facts (genre, rating, release date), cast images, related films | "Blockbuster Movie" — Rotten Tomatoes rating, cast |
| Game | Logo, description, vendor list, screenshots, related games | "Fun Game" — purchase links, gameplay images |
| Sports Team | Logo, description, facts (stadium, manager, championships), roster table, schedule | "Big League Team" — player stats, win record |
The API leak confirms this with DomainSpecificRepresentation in EntityJoin — entity type stored via KG Topic, Wikipedia classification, and MapFacts representation. The entity type is stored as a property of the entity itself, and template routing happens at serving time.
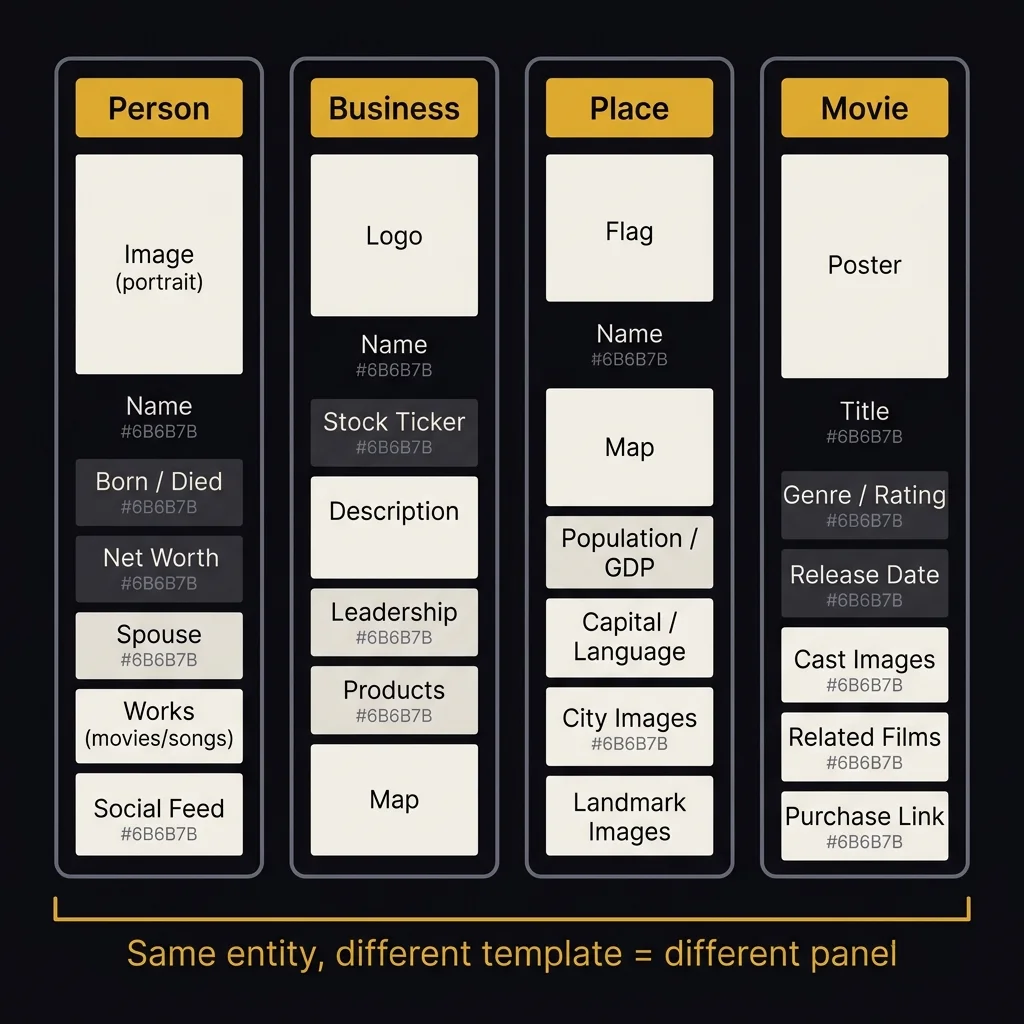
If your entity is misclassified, the KP shows the wrong template — and may display misleading information or miss critical fields entirely. A personal brand classified as a "Business" gets a logo slot instead of a portrait slot, a map instead of a bio. The entity classification determines the template, and the template determines what facts Google looks for. This is why Schema.org markup matters: Person, Organization, and LocalBusiness are not interchangeable. Using the wrong schema type can send the wrong classification signal. Google's system can likely override schema signals with its own classification — but making it guess is never better than telling it directly.
Multi-Source Aggregation: The ≥2 Resources Requirement
Claim 1 of this patent — the broadest independent claim — contains a requirement that changes how you think about Knowledge Panel optimization:
The patent describes a "content items store" that indexes content from "multiple disparate content sources." When the KP apparatus needs to populate a template, it accesses this store dynamically — pulling titles, images, facts, and descriptions from different publishers for the same entity.
The API leak provides the infrastructure: cdoc (a list of SimplifiedCompositeDoc reference pages per entity in EntityJoin) stores the reference pages Google uses as sources for entity information — Wikipedia, official websites, IMDB, industry databases. Becoming a cdoc reference page means your content is in the entity's core knowledge — Google's KP literally pulls facts from your page.
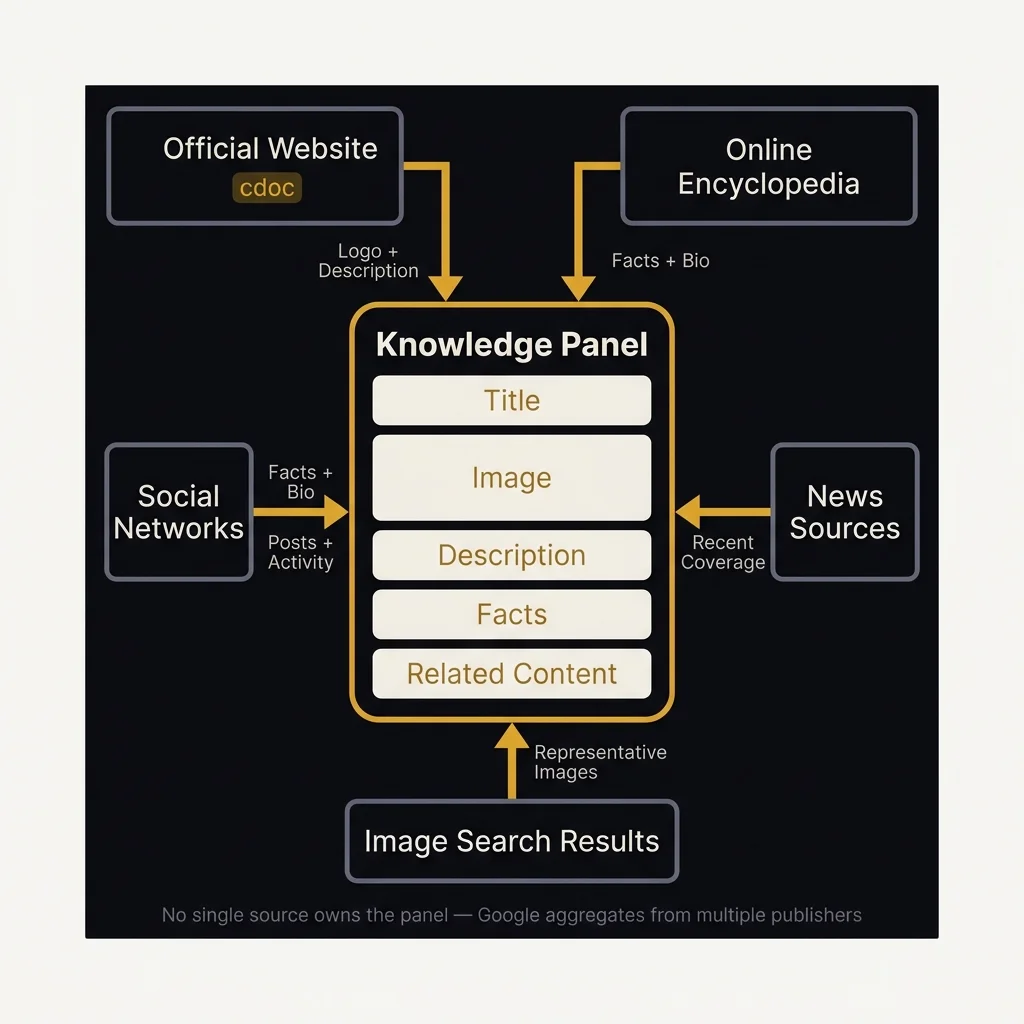
The patent also describes fact ranking: "the higher ranked image in a search for the entity is ranked higher in the knowledge panel than a lower ranked image." Content items within the KP are ranked by "historical user search events" — essentially, the facts users search for most about an entity get the most prominent placement. The API confirms this through Navboost data (totalClicks) being fed into entity annotation systems.
The ≥2 resources requirement explains a pattern I've seen in the industry. Jason Barnard — widely recognized as the foremost authority on Knowledge Panel optimization — has built his entire Kalicube Process around this principle: the "Entity Home" (your official page) is Source One. Wikipedia, Wikidata, Crunchbase, LinkedIn, and industry databases are Source Two through N. The more independent sources corroborate the same facts about your entity using consistent structured data, the higher the entity confidence score rises. Jeremy Rivera proved the minimum viability of this when he published a 2-page book on Amazon — "I Self Published An SEO Book & All I Got Was This Lousy Knowledge Panel" — and triggered entity recognition. I was a guest on his podcast. He demonstrated that you don't need a Wikipedia page or ten years of history. You need multi-source corroboration with sufficient confidence. The bar is lower than most people think.
And the API reveals something the patent doesn't mention: Google tracks fact provenance — which source asserted each fact. KnowledgeGraphTriple.provenance records where every triple came from. Combined with isNegation — a flag indicating what is NOT true about an entity — Google can fact-check claims against contradictory information from different sources. If one source says you're the CEO of Company X while another says you left in 2023, the system has the infrastructure to detect and resolve the conflict.
The 12-Year Prosecution Arc: Why Google Keeps Filing
Most patents get filed once and granted once. This one has been filed six times — all by the same inventor, all citing the same specification, all seeking different claim language:
| Filing | Filed | Granted | Status | Strategic Context |
|---|---|---|---|---|
| US9268820B2 (Origin) | Aug 2012 | Feb 2016 | ✅ Active | Foundational KP architecture — 30 claims |
| US9454611B2 (C1) | Jan 2016 | Sep 2016 | ✅ Active | Filed 5 days after parent granted — immediate scope expansion |
| US10318567B2 (C2) | Aug 2016 | Jun 2019 | ✅ Active | KP rapidly expanding to brands and businesses |
| US11093539B2 (C3) | May 2019 | Aug 2021 | ✅ Active | Entity types expanding — brands, local businesses |
| US11836177B2 (C4) | Aug 2021 | Dec 2023 | ✅ Active | Added: animals, works of art, sporting events, songs, albums |
| US20240202224A1 (C5) | Nov 2023 | — | ⏳ Pending | Filed 8 days before C4 granted — Final Rejection cycle active |
The pattern is deliberate: each continuation is filed within days of the previous patent being granted. This is standard practice in high-value patent families, but the duration is remarkable — 12 years of continuous prosecution on the same specification. Google is building a wall of claims around the Knowledge Panel architecture. Any competitor attempting to build a similar entity panel system would need to navigate claims from five granted patents plus whatever scope C5 eventually achieves.
The most recent continuation (US20240202224A1) has been through multiple rejection-response cycles — non-final action, response, advisory action, second non-final action, and now a Final Rejection. Google hasn't abandoned the application. Their patent attorneys continue to argue for additional claim language. This is normal for high-value filings where the applicant keeps narrowing claims until the examiner grants. The fact that this prosecution is ongoing in 2024–2025 confirms the KP patent family is still strategically important to Google.
Each continuation adds new entity types to the claim scope. C4 (2023) explicitly added "animal," "work of art," "sporting event," "song," and "album." This expansion tracked real-world KP deployment: Knowledge Panels for brands and businesses became common around 2016–2019, panels for niche entity types (artworks, songs) expanded in the early 2020s. The patent family isn't describing a static system — it's evolving with the product.
Knowledge Panel SEO Implications: What This Means for Your Brand
1. The Knowledge Panel Is Built, Not Optimized
The patent describes a system that presents information about entities — it doesn't describe a ranking mechanism. You don't "optimize for" a Knowledge Panel the way you optimize for a featured snippet. You build the conditions that allow Google to generate one: entity recognition, multi-source corroboration, consistent facts across sources, and a designated reference page. The distinction matters because the work is different — it's entity building, not content optimization.
2. Own the Source Document
The patent describes content items being pulled from reference pages. The API confirms this with referencePageIndex and cdoc. If your entity's reference page is Wikipedia, you're at the mercy of editors. If it's your own site's About page — technically the "Entity Home" in Barnard's framework — you control the facts, the structured data, and the Schema markup. Your entity's About page should be treated like a product page for your brand: every fact in the format of an information triple (Subject → Predicate → Object), every claim backed by verifiable external corroboration.
3. Multi-Source Corroboration Is Non-Negotiable
Claim 1 requires content from at least two different resources. In practice, more sources with consistent information increases entity confidence. This is why citation consistency across directories, profiles, and industry databases matters — not because citations are link building, but because they're the corroborating sources the KP system needs. LinkedIn, Crunchbase, industry associations, published interviews, podcast appearances — each one is a potential second or third source.
4. Topicality Discipline Protects Entity Confidence
The entity-type classification determines the template. But entity confidence is also influenced by topicalityE2 — how relevant your page is to the entity — and by siteFocusScore and siteRadius, which measure how topically concentrated your domain is. If I start publishing articles about motorcycles and poetry on this site, my entity signal as an SEO practitioner and researcher gets diluted. The patent's template system rewards clarity: the more unambiguous your entity classification, the cleaner the template selection, the more accurate the facts displayed. Topicality discipline — keeping your entity tightly focused — is an entity confidence optimization.
5. Use schema:sameAs to Connect Sources
The patent describes a system that aggregates content from multiple sources for the same entity. The system needs to know that "Alejandro Meyerhans on alejandromeyerhans.com" and "Alejandro Meyerhans on getmelinks.com" are the same entity. schema:sameAs is the mechanism. It explicitly tells Google: these two pages describe the same person/organization. Without it, Google must infer the connection — and inference is always less reliable than declaration.
US10235423B2 (Entity Scoring) — The entities that populate Knowledge Panels are scored by this patent's relatedness and notability signals. Entity scoring determines which entities are important enough to warrant recognition. Read the Entity Scoring analysis →
US7603350B1 (Entity Trust) — The trust layer determines which entity sources Google treats as authoritative for KP content. A high-trust reference page is more likely to be selected as a cdoc source.
Read the Entity Trust analysis →
US9767157B2 (Panda) — Site quality scores influence whether a page qualifies as a reference page (cdoc) for an entity. A low-quality site won't become an entity's reference page — even if the facts on it are accurate.
Read the Panda analysis →
Google API Leak Cross-Reference: Knowledge Panel Infrastructure
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — reveals 18 attributes that align with this patent's mechanisms:
| Patent Mechanism | API Attribute | Alignment |
|---|---|---|
| Entity identification for query | encoded_mid — entity MID list | ✅ CONFIRMED |
| Entity-type template selection | DomainSpecificRepresentation (KG Topic, Wikipedia, MapFacts) | ✅ CONFIRMED |
| Multi-source content aggregation (≥2 resources — Claim 1) | cdoc — reference page list per entity | ✅ CONFIRMED |
| Reference page designation | referencePageIndex — canonical entity page | ✅ CONFIRMED |
| Knowledge Graph fact structure | KnowledgeGraphTriple — subject → predicate → object | ✅ CONFIRMED |
| Fact provenance tracking | KnowledgeGraphTriple.provenance | ✅ CONFIRMED |
| Fact ranking by user search events | totalClicks (Navboost → entity annotation) | 🔶 STRONG MATCH |
| Per-entity topicality scoring | topicalityE2 — [0–100] relevance per entity | 🔶 STRONG MATCH |
| Entity relationship graph | linkInfo + isBoostedPrimaryWeightLink | 🔶 STRONG MATCH |
| Entity connectedness | connectedness — [0–1] inter-entity density | 🔶 STRONG MATCH |
| Disambiguation handling | isDisambiguationPage | ✅ CONFIRMED |
| Author entity detection | isAuthorIndex | 🔷 API EXTENDS |
| Publisher entity detection | isPublisherIndex | 🔷 API EXTENDS |
| Entity name variants | nameInfo + contextNameInfo | 🔷 API EXTENDS |
| Entity confidence calibration | confidence — calibrated precision curve | 🔷 API EXTENDS |
| Negation facts | KnowledgeGraphTriple.isNegation | 🔷 API EXTENDS |
| Latent entity associations | latentEntities — implicit connections | 🔷 API EXTENDS |
| Interactive UI objects (stock charts, widgets) | — | 📜 PATENT ONLY |
✅ CONFIRMED = direct API attribute match. 🔶 STRONG MATCH = API attribute strongly corresponds to patent mechanism. 🔷 API EXTENDS = API reveals more than patent describes. 📜 PATENT ONLY = no direct API attribute found.
88% of patent mechanisms have API-level evidence (CONFIRMED + STRONG MATCH + API EXTENDS). Only one mechanism — interactive UI widgets — has no API footprint, likely because those are rendering-layer components, not indexing-layer attributes.
The API leak provides attribute names and data types — not the scoring formulas. The patent provides the architectural concepts. Together they form a strong evidentiary chain. Neither alone is proof; together, they're as close to proof as we get in SEO. One important calibration: the "facts" in the patent text and the KnowledgeGraphTriple in the API are a strong match, not a confirmed match — the patent uses the term "facts" to describe content items, while the API structures those facts as subject-predicate-object triples. The architectural alignment is clear, but the patent doesn't use the word "triple."
Citation Network
Patent Family Chain
US9268820B2 (this patent, filed 2012, granted 2016 — active) → US9454611B2 (2016, active) → US10318567B2 (2019, active) → US11093539B2 (2021, active) → US11836177B2 (2023, active) → US20240202224A1 (2024, pending)
Unlike the Entity Trust patent family — which let three continuations expire — every granted patent in the KP family remains active with maintenance fees paid. Google is defending this IP aggressively. The difference is telling: entity trust mechanisms were absorbed into the Knowledge Graph and structured data systems (making continuation claims redundant). KP architecture remains actively protected because the presentation system is still a distinct, defensible product.
Related Articles on This Site
- US10235423B2 (Entity Scoring) — The entity scoring system determines which entities are "notable" enough to warrant Knowledge Panel treatment. Entity scoring is the upstream signal; this patent is the downstream presentation. Without sufficient notability and relatedness scores, the KP apparatus never activates.
- US7603350B1 (Entity Trust) — Entity trust determines which sources are authoritative for KP content. A high-trust reference page is more likely to be selected as a
cdocsource. This patent describes what gets displayed; Entity Trust describes who gets believed. - US8661029B1 (NavBoost) — Fact ranking in the KP uses "historical search events" — the same user interaction data that NavBoost processes for organic ranking. The click data pipeline feeds both systems.
- US9767157B2 (Panda) — Site quality scoring influences reference page eligibility. A low-quality site cannot become a
cdocreference page — not because the facts are wrong, but because the source doesn't meet the quality threshold. - US8682892B1 (Implied Links) — Implied links feed the brand awareness signals that contribute to entity recognition. The more independent sources mention your brand (linked or unlinked), the stronger your entity profile becomes — and the more likely the KP apparatus is to trigger.
- NavBoost Deep Dive — The practitioner synthesis of how click-based ranking signals work in production. The KP's fact ranking uses "historical search events" — the same data NavBoost processes. The deep dive maps the full pipeline from click to re-ranking signal, including the 4D satisfaction tensor that determines how engagement is measured across device, country, language, and location.
Knowledge Panels: What Doesn't Matter as Much as SEOs Think
The nature of this patent is straightforward: Google needs to know what you are before it can show what you are. The Knowledge Panel is not a ranking signal. It is the visible manifestation of entity recognition — the system saying, "I have identified a factual entity with sufficient confidence, I know its type, I have collected facts from multiple independent sources, and now I'm displaying those facts in a structured format." Everything else — rankings, featured snippets, AI Overviews citing your content — flows downstream from whether Google recognizes your brand as an entity in the first place.
The flavor — the specific template architecture, the ≥2 resources hard requirement, the 2012-era string-matching entity identification — that's the implementation. Templates will change. Entity types will expand. The threshold for "factual entity" will shift. But the fundamental truth — that Google operates on entities, and entities must be unambiguously identified before the presentation system activates — is permanent.
Here's the uncomfortable pushback I've gotten when presenting this work: "I've ranked for years without a Knowledge Panel. Knowledge Panels don't matter." And they're right — for now. Technical SEO is increasingly solved by frameworks like Astro. Content is becoming commodity-cheap through AI pipelines. The moment everything on your website can be cloned in a weekend — and it can, today — there are exactly two things that remain defensible: your position in the Knowledge Graph and your backlink profile. One is brand. The other is links.

At Google Search Central Live Toronto in April 2026, Google presented a slide explicitly distinguishing "Commodity Content" from "Non-Commodity Content." Commodity content — generic advice that AI can replicate — was contrasted with non-commodity content driven by first-hand experience, proprietary data, and unique examples. Chris Long connected this to Cyrus Shepard's study on the December 2025 update, which found "proprietary data" as the third most correlated variable to ranking success. At the same time, Google is issuing scaled content abuse manual penalties for sites publishing mass AI-generated content. The direction is clear: content that can be cloned in a weekend is becoming a liability. Entity recognition — the thing this patent describes — is the infrastructure that rewards the content that can't.
You can't replicate a backlink profile in a weekend with Claude Code. You can't build the brand presence and the Knowledge Graph entity depth in a weekend with any tool. That takes real time, real effort, and real value delivered to a real marketplace — for long enough that Google's multi-source aggregation system accumulates sufficient confidence to trigger the panel.
Your ten-year content moat can be replicated in a weekend. Your Knowledge Graph entity can't. You cannot circumvent the work. But if the work is good — if you're building something real, with a real name behind it, in service of a real marketplace — the Knowledge Panel is just the system catching up to what you've already built. Don't mistake the dashboard light for the engine.
Frequently Asked Questions
What does patent US9268820B2 actually do?
It describes the complete system for generating Knowledge Panels — the structured information cards that appear alongside Google search results. When a query references a known "factual entity," the system selects an entity-type template, aggregates content from multiple independent sources, ranks the content by user search popularity, and assembles it into a panel displayed next to the organic search results. The KP apparatus is architecturally separate from the search ranking system.
How does Google decide whether to show a Knowledge Panel?
The system checks whether the search query references a known "factual entity" in Google's entity database. If there's a match with sufficient confidence, the KP pipeline activates: entity type determined, template selected, content aggregated, panel assembled. If there's no match — or if the confidence is below the threshold — only standard search results are returned. The API leak reveals a calibrated confidence score from 0 to 1, with precision ranging from 75% at 0.3 to 98% at 1.0.
Does having a Knowledge Panel improve your SEO rankings?
The patent describes a presentation system, not a ranking system. There is no evidence that the Knowledge Panel itself boosts organic rankings. However, the entity recognition that triggers a KP — high entity confidence, multi-source corroboration, Knowledge Graph presence — feeds into other systems like authorityPromotion and siteAuthority that do affect rankings. The KP is a symptom of entity recognition, not a cause of ranking improvement.
What is an "Entity Home" and why does it matter for Knowledge Panels?
The Entity Home (a term coined by Jason Barnard) is the page that serves as the primary reference document for your entity — the "Source Document" that Google's system designates as referencePageIndex in the API. This is typically your About page. The patent requires content from at least two independent sources, but the reference page is the anchor — it's where Google starts when assembling your entity's facts. Owning the Entity Home means controlling the facts that populate your Knowledge Panel.
Can a small website trigger a Knowledge Panel?
Yes. Jeremy Rivera demonstrated this by publishing a 2-page book on Amazon and triggering entity recognition. The API reveals a smallPersonalSite promotion signal that actively boosts small sites. The barrier isn't site size — it's multi-source corroboration with sufficient entity confidence. A small personal site corroborated by an Amazon listing, a LinkedIn profile, and an industry directory can reach the threshold.
What is the difference between the Knowledge Graph and the Knowledge Panel?
The Knowledge Graph is the database — Google's structured entity store containing entities, their types, their facts (as triples: subject → predicate → object), and their relationships. The Knowledge Panel is the visual presentation — the card displayed alongside search results. This patent describes how the panel is generated from the graph. You need to be in the Knowledge Graph before a Knowledge Panel can be assembled for you.
Why has Google filed 6 continuations on this patent?
Each continuation seeks additional claim scope — different legal protections on the same specification. The pattern tracks KP product evolution: the original (2012) established the architecture, continuations expanded entity types (businesses in 2016–2019, animals and artworks in 2021–2023), and the 2024 pending application seeks additional language. Google is building a wall of claims around KP architecture — 99 patent families cite this chain. Any competitor building a similar system must navigate claims from five granted patents.