Search my name. Go ahead — search "Alejandro Meyerhans." I'm not the only person in the world with this name. And yet, I'm the one that appears. This isn't about content quality or link building. This is about how Google decides which entity deserves the ranking. And there's a patent that describes a formula for it.
This article is built on three sources: the patent text itself (the legal document filed with the USPTO), the 2024 Google API documentation leak, and observable Knowledge Graph behavior. The patent proves Google designed this entity scoring system. The API leak shows data structures consistent with it. Neither proves that this exact formula runs in production today — the patent itself says the calculation shown is "merely an example" and that "any suitable calculation may be used." I'll be explicit throughout about where evidence ends and inference begins.
Patent Metadata
A few things stand out. This was filed in 2012 — the same year Google launched the Knowledge Graph publicly. That's not a coincidence. Google was building the Knowledge Graph and simultaneously patenting the scoring systems that would make it useful for ranking. The gap between filing and grant is 7 years. The patent is active, the maintenance fees are paid, and 38 patent families cite it. That citation count is important — it tells you this isn't an abandoned experiment. Other Google systems build on top of this one.
If you've read my On-Page SEO guide, this is the evidence behind the entity optimization section. Everything I recommend there traces back to mechanisms like this one.
What This Patent Does (Plain English)
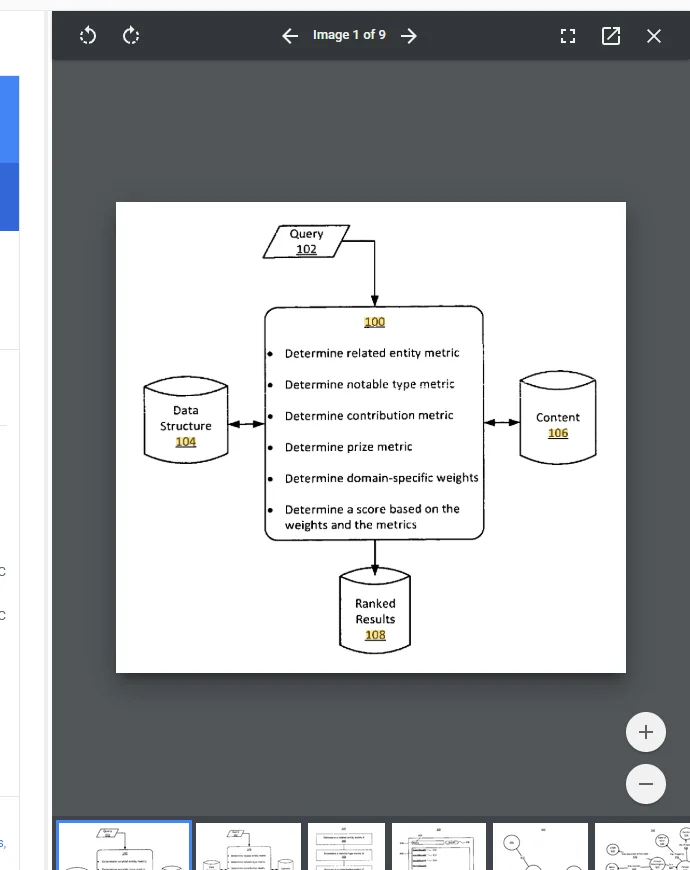
Here's the core problem. When Google retrieves search results from the Knowledge Graph, it gets a list of entities — people, places, movies, books, restaurants. But how does it decide which entity to show first? Which entity resolves when multiple share a name? Which restaurant deserves position one? The patent doesn't mention Knowledge Panels specifically, but it describes exactly this disambiguation and ranking problem.
This patent describes a system that:
- Retrieves search results from a Knowledge Graph data structure
- Identifies the entity type for each result (person, movie, book, place, etc.)
- Determines the domain each entity belongs to (Film, People, Books, Places, etc.)
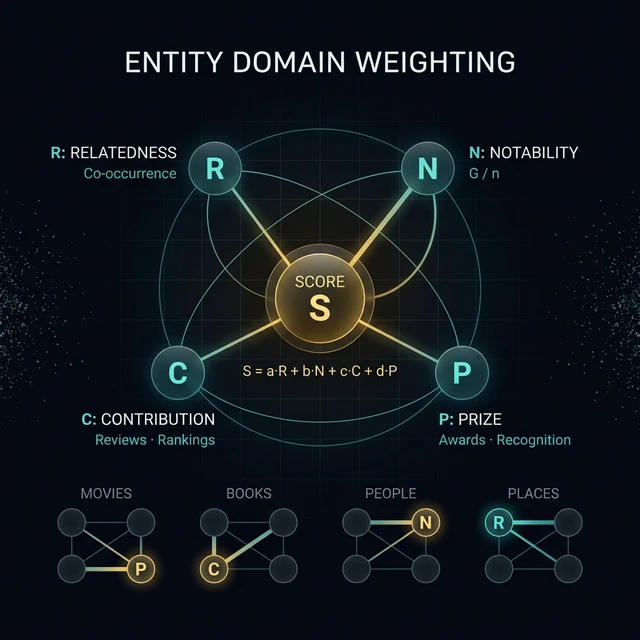
- Calculates four metrics for each entity — Relatedness, Notability, Contribution, and Prize
- Applies domain-specific weights to each metric
- Combines them into a single score that determines ranking
The output: a score S used to rank entity results. The patent calls this formula "merely an example" and notes that "any suitable calculation may be used" — but it's the only worked model we have, and the four metrics it names (R, N, C, P) are the core architecture.
Here's what this looks like in the actual patent. This is FIG. 1 — the core system architecture:
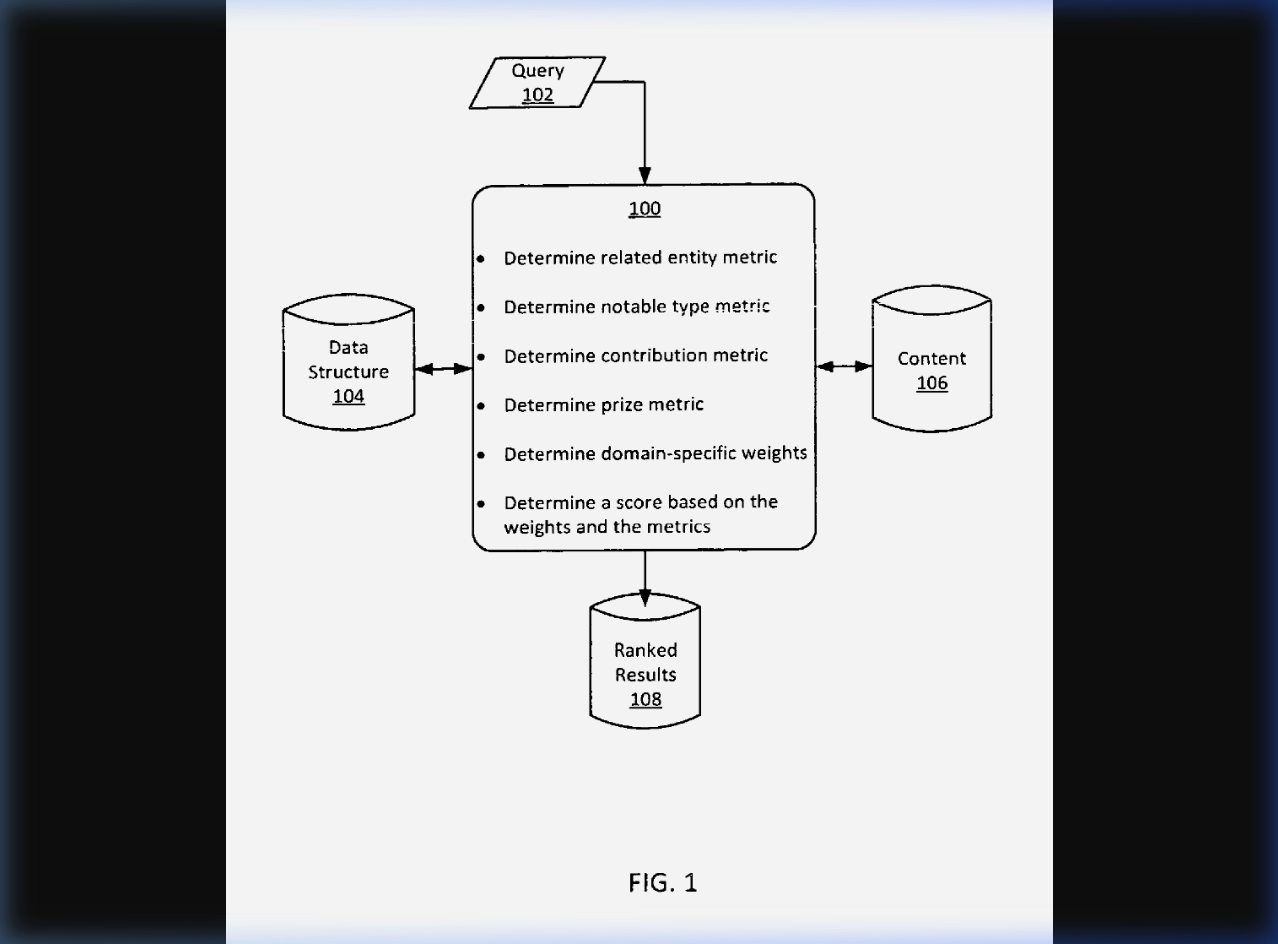
Let me translate that to human.
↓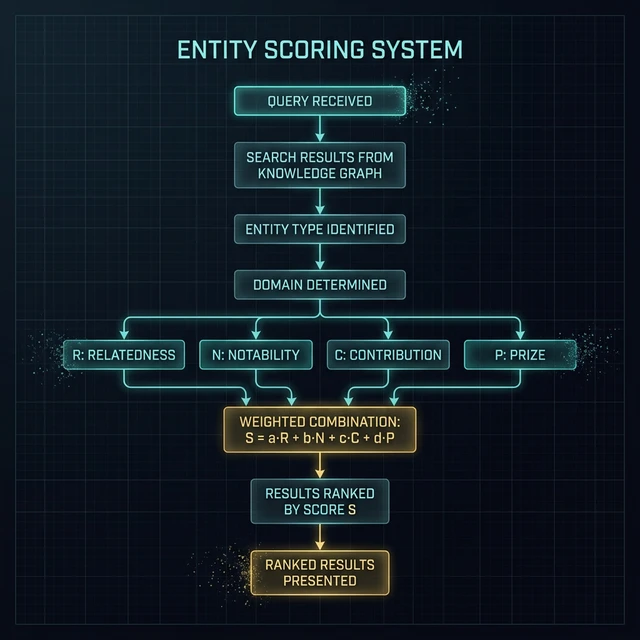
The Entity Scoring Formula
Let's break this down. Each letter represents a distinct scoring mechanism that the patent describes for evaluating entities. The weights a, b, c, d change depending on what kind of entity is being scored — and that's where this gets interesting.
My job here is not to teach so much as to reveal, with all the cards on the table, the real mechanisms of search as much as I can. In the process of doing so, I further my own understanding of this. Because if you can't explain it to a three-year-old, you don't really get it.
So let me show you what each variable actually measures.
This patent was filed in 2012 — the same year Google launched the Knowledge Graph. By 2026, Google's entity systems run on Graph Neural Networks and semantic embeddings, not simple linear equations. So why does this formula still matter? Because early patents like this one served as the grading rubrics that trained Google's neural networks. The AI learned which entities deserved high scores because the heuristic formula told it so. The formula's DNA lives inside the neural model's intuition. Today, a Graph Neural Network doesn't explicitly calculate a·R — it maps billions of entities into a high-dimensional vector space where entities with strong Relatedness, Contribution, and Prize naturally cluster at the centre, earning trusted status. The mechanics evolved; the architectural principles didn't.
R — Relatedness Metric
What the Relatedness Metric Measures
How strongly an entity co-occurs with its entity type across the entire web.
How Google Calculates Entity Relatedness
"The relatedness metric is determined based on the co-occurrence of an entity reference contained in a search query with the entity type of the entity reference on web pages."
The patent gives two formulas. The first is probability-based:
Where P(E) is the probability of finding entity reference E in a text corpus, and P(E, REⱼ) is the probability of finding both E and related entity reference REⱼ together. The second formula uses raw counts: N(E,REⱼ) / N(E).
The patent's example: if the search query contains "Empire State Building" (entity type: "Skyscraper"), Google measures how often "Empire State Building" and "Skyscraper" co-occur across web pages. Higher co-occurrence means higher Relatedness.
Entity Relatedness Scoring in Practice
The patent includes FIG. 4 — an entity relationship graph that shows exactly how Google models these connections:
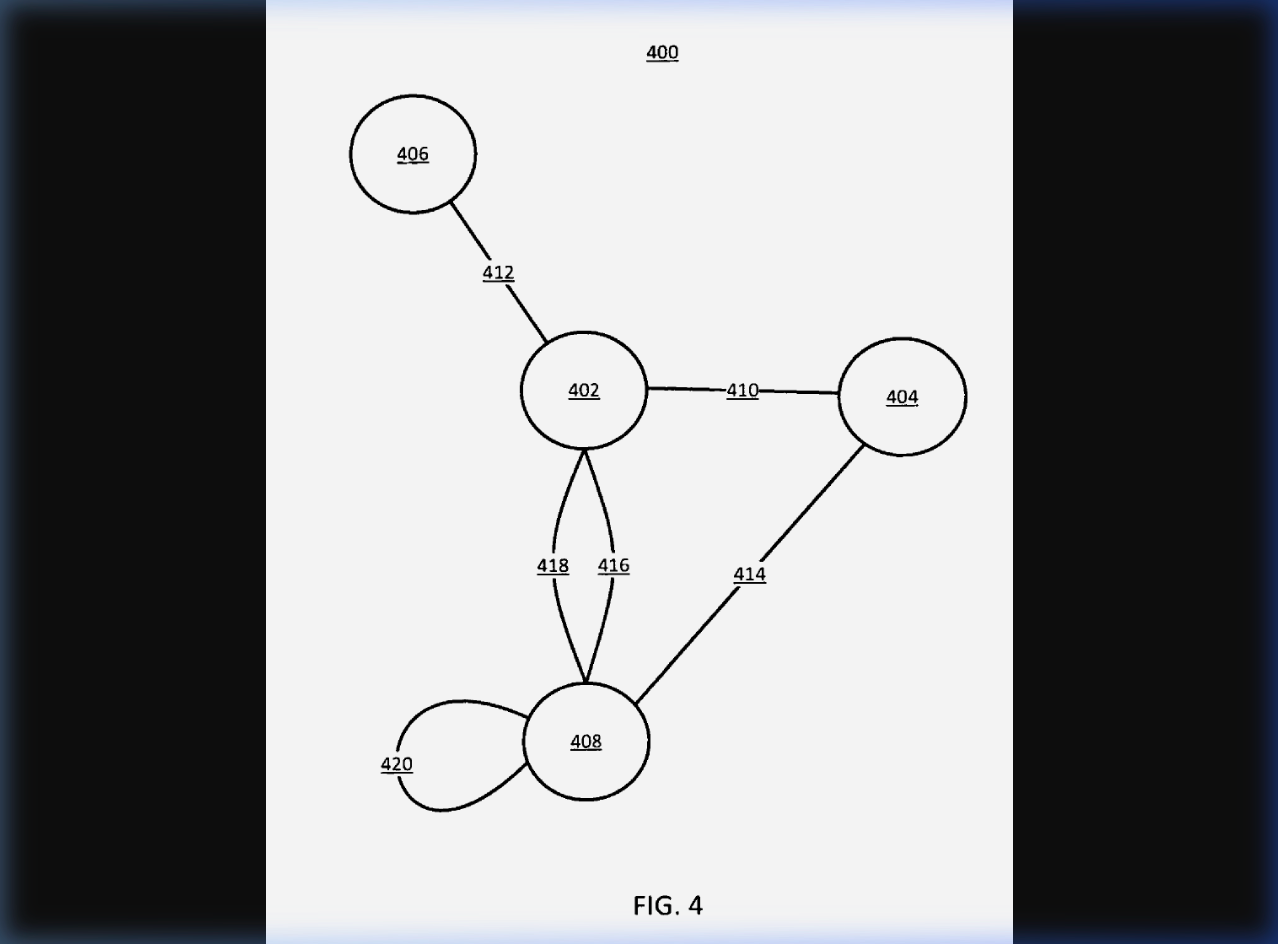
Think of each circle as an entity — a person, brand, concept, or place. The lines connecting them are co-occurrence relationships that Google has observed across the web. The more lines running between your entity and entities in your domain, the higher your R score. This is why getting mentioned alongside other established entities in your space — through PR, interviews, co-authored content, industry roundups — directly feeds your Relatedness metric.
Imagine you see "Alejandro Meyerhans SEO," "Alejandro Meyerhans link building," "Alejandro Meyerhans marketing" — and you see those consistently together across the web. What ends up happening is that when people search for SEOs and look for SEO practitioners, the connectedness between those attributes helps even when only one of the attributes is present in a different query.
It reinforces that the entity is what it claims to be. When the full string isn't present, Google can complete it from surrounding context. You could search for a "movie" and then "lead actress," and immediately Google resolves to the person entity — not the movie entity — because the co-occurrence data tells it which entity is being sought.
Entity-keyword co-occurrence on external pages is a direct input to R. It's not just your page that matters — it's the entire web corpus reinforcing that your entity IS the thing it claims to be.
The API's repositoryWebrefEntityJoin system extracts entities from raw text — no hyperlink required. In 2026, Google reads every mention of your brand name alongside your defining attributes, whether or not there's a link. This means PR mentions, podcast transcripts, social media bios, and unlinked citations all contribute to R. The patent's co-occurrence mechanism described traditional web-page counting; the modern Webref system extends it to any extractable text across Google's crawl.
N — Notable Entity Type Metric
What the Notability Metric Measures
How notable an entity's type is within its domain, scaled by global popularity.
The Entity Notability Formula
- G = Global popularity metric — aggregated user selections, link counts, site visits, and what the patent calls "a ranking that would be used to order results by a web search engine." That sounds like it includes PageRank-derived signals.
- n = Notable entity type rank — the position of an entity's type in a ranked list within its domain. Lower number = more notable.
The Patent's Worked Notability Example
In the Books domain, entity types might be ranked: "novels" first, then "non-fiction," then "short stories." A fiction novel with global popularity 50 and entity type rank 1 gets N = 50. A short story with global popularity 20 and entity type rank 8 gets N = 2.5. The novel scores 20x higher — not because the content is better, but because the entity type is ranked higher.
Entity Notability Scoring in Practice
Take my name — "Alejandro Meyerhans." I am not the only person in the world with this name. As odd as this first and last name combination is, there are others. And yet, when you search for it, I'm the one that appears. Under this patent's model, an entity classified as "CEO" versus the same name associated with "individual with no public career" would produce a different entity type ranking — the CEO classification has a lower n (higher rank in the notable entity type list). Then the global popularity of the CEO version — who operates publicly online, produces content, and runs a company — versus someone with no public digital presence produces a different N value.
That's N = G / n in action. The entity type classification determines n, and everything you do publicly determines G.
Being the right type of entity in your domain is a mathematical multiplier in this patent's model. Under the formula, a more publicly notable entity type has a lower n (higher rank), which directly divides into the score. Entity type classification isn't cosmetic — it's structural.
C — Contribution Metric
What the Contribution Metric Measures
An entity's quality, performance, and reputation based on external evaluations — reviews, rankings, best-seller lists, critical assessments.
How Google Calculates Entity Contribution
"The contribution metric is based on critical reviews, fame rankings, and other information. Rankings are weighted such that the highest values contribute most heavily to the metric."
The patent describes a decay-weighted function:
Where Sₖ is an individual contribution score, λ is a decay constant between 0 and 1, and k is the rank position ordered from highest to lowest. The critical insight: your best work counts the most. An actor's highest-rated movie dominates their C score; their worst movie barely registers.
The sources Google uses, per the patent: professional critic reviews (weighted higher), user reviews (weighted lower), best-seller lists, commerce site reviews (Amazon), dedicated review platforms (Yelp, IMDB), news sources, research publications, and social media. For people, the patent defines a "fame metric" — a summation of contribution scores from all associated works.
Entity Contribution Scoring in Practice
The contribution metric is being verified as extremely powerful because of AI rankings. We are seeing people publish listicles with their brand selected at the top — "the top 12 protein powders for women over 40 with rheumatoid arthritis." Hyper-specific. If that appears multiple times, and there's a review that says "I'm 42, I have three children, and I have rheumatoid arthritis, and this protein powder makes me feel great when I have my shake in the morning" — that feeds directly into C.
If there's a Reddit thread titled "best protein powder for women over 40" and your entity appears there, that's contribution too — with a side of co-occurrence. The individual contribution score Sₖ gets added to your stack, and the decay function ensures consistent, high-quality contributions compound.
This is your "body of work" score. Not just one page — the quality and external validation of everything associated with your entity. The decay weighting means your best stuff shines and your worst stuff fades. Consistency at the top end is what drives C.
P — Prize Metric
What the Prize Metric Measures
Awards, prizes, medals, and formal recognitions associated with an entity.
How Google Calculates Entity Prize Scores
Same decay-weighted structure as C:
Where Aₙ is the value of prize n, λ is the decay constant, and prizes are ordered from highest value to lowest. An Academy Award for Best Picture carries a higher prize value than a People's Choice Award for Cinematography. The weighting ensures the most significant awards dominate the score.
"A domain may include a set of award values associated with particular awards, categories of awards, and competitions."
Entity Prize Scoring in Practice
Consider two people with the same name. One is a Hall of Fame basketball player. The other is an everyday professional — strong LinkedIn presence, popular in their own network, well-respected in their field. But their name is owned by a more publicly recognized figure. Just the Hall of Fame induction alone builds the Knowledge Graph tremendously for the basketball player. That formal recognition creates asymmetric entity density that the everyday professional can't match with social media presence alone.
Awards, certifications, industry recognitions, and structured data marking them up aren't vanity metrics. Google maintains a ranked system of prize significance. Real-world formal recognition translates directly into scoring advantage.
The Entity Weight System: Why Entity Type Is Everything
Here's the thing. The weights a, b, c, d are not universal. They're domain-specific. The patent is explicit about this:
"The search system may place the highest weight on the prize metric for entities associated with the 'Film' domain and may place the highest weight on a contribution metric for entities associated with the 'Book' domain."
| Domain | Likely Highest Weight | Why |
|---|---|---|
| Movies | d (Prize) | Oscars and awards are the strongest relevance signal for films |
| Books | c (Contribution) | Reviews, best-seller lists, and literary quality matter most |
| People | b (Notability) | "U.S. President" vs. "random person" is the most differentiating signal |
| Places | a (Relatedness) | How strongly a place co-occurs with its defining characteristics |
The patent goes further: weights can be zero (a metric is completely ignored for certain domains) or even negative (a high value actually hurts the entity's score). The weights are determined experimentally, stored in the system, and retrieved when a query is received.
SEO Implications: The 4-Variable Entity Framework
This isn't academic. If you're building a brand — personal or commercial — each variable in this formula maps to a specific set of actions:
| Variable | Patent Says | Operator Translation |
|---|---|---|
| R | Co-occurrence of entity reference with entity type across web pages | Get your entity and its defining attributes mentioned together consistently — PR, guest posts, interviews, directory listings, social profiles. The web must associate your name with your thing. |
| N | Global popularity metric divided by notable entity type rank | Ensure structured data correctly classifies your entity type. Build public presence that increases G — the global popularity metric. Correct Knowledge Panel classification, if you have one, is a visible proxy for this. |
| C | Decay-weighted aggregation of critical reviews, rankings, and quality signals | Accumulate quality contributions — reviews, rankings, publications, features. The decay function rewards consistency at the top end. A few excellent contributions matter more than many mediocre ones. |
| P | Weighted sum of awards and formal prizes | Pursue industry awards, certifications, and formal recognitions. Mark them up with structured data. Prize is potentially the hardest metric to fake — which may make it increasingly valuable. |
Patent Says = what the patent text directly describes. Operator Translation = the modern SEO action I infer from it. The distinction matters — the patent provides the mechanism; the operator column is my applied interpretation.
Google's public E-E-A-T framework (Experience, Expertise, Authoritativeness, Trustworthiness) maps directly onto this patent's metrics — Expertise aligns with Contribution, Authoritativeness with Notability, and Trustworthiness with Relatedness and Prize. But here's the insight the industry misses: you can't optimise a page for E-E-A-T if the entity behind it has no graph presence. E-E-A-T is a qualitative framework; entity scoring is its quantitative foundation. If your entity's S approaches zero — no co-occurrence, no classification, no contributions, no prizes — no amount of "E-E-A-T page optimisation" changes that underlying score.
API Leak Cross-Reference
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — revealed internal attribute names that align with this patent's mechanisms. While we can't prove direct implementation, the overlaps are notable:
| Patent Concept | API Leak Attribute | API Evidence |
|---|---|---|
| Entity reference and entity types | repositoryWebrefEntityJoin |
✅ STRONG MATCH — Entity resolution and joining; the system that connects entity references to Knowledge Graph entries |
| Knowledge Graph data structure | repositoryWebrefWebrefEntities |
✅ STRONG MATCH — Webref entities module handles entity extraction and matching from web content |
| Global popularity metric G | qualitySalientTermsSalientTerm |
🔶 API EXTENDS — salient term identification may feed into entity relatedness and popularity scoring |
| Entity type classification | repositoryWebrefEntityNameSignals |
✅ STRONG MATCH — entity name signals contribute to entity type resolution and disambiguation |
| Co-occurrence across web pages (R metric) | qualityNsrNsrData |
🔶 API EXTENDS — NSR data includes topic and entity co-occurrence signals that extend the R metric concept |
| Domain-specific weights | repositoryWebrefEntityCategory |
📜 PATENT ONLY — entity categories inferred to drive domain-based weight selection; no direct API attribute confirms weight values |
✅ STRONG MATCH = the API attribute exists and its name/structure aligns closely with this patent mechanism. This confirms the data structure is present in production, not that Google implements this specific patent's formula as described. 🔶 API EXTENDS = the API attribute goes beyond what the patent describes. 📜 PATENT ONLY = described in the patent but no direct API confirmation.
Citation Network
Backward Citations (Prior Art)
This patent cites 7 prior patents, all related to search result ranking and knowledge graph construction:
- US20050060312A1 — Search result ranking via entity metadata
- US20080033939A1 — Content-based entity scoring
- US20090077059A1 — Structured data retrieval
- US20090144609A1 — Knowledge graph querying
- US20100250523A1 — Entity-based search ranking
- US20120095996A1 — Graph-based information retrieval
- US20130218866A1 — Entity resolution in search
Forward Citations (38 Patent Families)
38 patent families cite this patent — a significant forward citation count that indicates this scoring framework has become foundational infrastructure. Notable citing patents include:
- US11048765B1 — Entity understanding systems
- US11741090B1 — Advanced entity classification
- US11809506B1 — Knowledge graph enrichment
- US11922475B1 — Entity scoring refinements
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- The formula S = a·R + b·N + c·C + d·P is explicitly described as an illustrative model for entity ranking.
- The four metrics, their calculation methods, and the domain-specific weighting system are documented in detail.
- Google filed this patent in 2012 (the year the Knowledge Graph launched), and it was granted in 2019.
- 38 other patent families cite this patent — it is a foundational node in Google's entity-ranking patent graph.
- The maintenance fees are current — the patent is active.
- The patent itself states the formula is "merely an example" and that "any suitable calculation may be used."
- The API leak attributes (
repositoryWebrefEntityJoin,repositoryWebrefEntityNameSignals,repositoryWebrefWebrefEntities) closely match this patent's entity resolution and classification architecture, suggesting the underlying data structures remain in production. - The emphasis on domain-specific weights matches observable differences in how Google handles different verticals (e.g., film vs. people vs. places).
- The 38 forward citations suggest the scoring framework has evolved but the core approach — multi-metric entity evaluation with domain-specific weighting — persists as an architectural pattern.
- Google's public E-E-A-T guidelines map onto the four metrics in ways that are too structurally close to be coincidental.
- Whether the linear S = a·R + b·N + c·C + d·P formula has been superseded by Graph Neural Networks that score entities via high-dimensional embeddings rather than explicit weighted sums. We use the patent's formula to illustrate the architectural logic, not as a literal production equation.
- The exact weight values for any domain.
- Whether the formula has been extended with additional metrics beyond RNCP.
- How often the weights are recalibrated.
- Whether the prize and contribution sources have expanded beyond those listed in the patent.
- Whether AI Overviews and LLM-generated answers consult entity scores directly or use them indirectly through the Knowledge Graph's trust layer.
Entity Scoring: What Doesn't Move the Needle as Much as SEOs Think
I'm not trying to chase the changes in the weights and the flavor of the algorithm.
Here's the thing. The formula might change. The weights of these factors will change — Google might determine that Prize matters more because real-world awards are harder to fake. Contribution might get downweighted because AI can generate fake reviews at scale. Relatedness might spike in importance because genuine co-occurrence across the web is harder to manufacture than it used to be.
I aim to lock down a thorough understanding of the nature of the algorithm, so that when we see the flavor change, we can do a quick assessment of the actual search engine result pages and say: "Yep, this is the way the weights have changed. The results are saltier now — same meal, more salt." No mystery. No surprises. We know what's already on the recipe, so when the flavor shifts, we can name the ingredient that moved.
To put it in engineering terms: Google's incentive — whether for traditional blue links or AI Overviews — is always to minimise the cost of retrieving accurate information. An entity with strong R, N, C, and P is a trusted, anchored node in the Knowledge Graph that LLMs can cite confidently without risk of hallucination. An entity with weak scores is ambiguous, unreliable, or invisible — exactly the kind of node a Retrieval-Augmented Generation system will skip in favour of a better-anchored competitor. By building the signals this patent describes, you're not just optimising for a 2012 formula — you're making your brand retrievable and citable across every surface Google serves answers on.
This was a question I received from Edward Sturm on a recent episode of his show — the tension between chasing algorithmic updates and understanding the underlying mechanics. The answer is the same: know the nature deeply enough that the flavor changes become diagnostic, not disruptive.
That's what this series is about. Not predicting the next update. Understanding the kitchen well enough that when the recipe changes, we can taste it and name every ingredient.
Related Research in This Series
This patent is part of a growing registry of Google ranking patents I'm documenting and cross-referencing:
- US8661029B1 — NavBoost (CRAPS) — How Google uses click signals and dwell time to rewrite rankings. The most powerful ranking signal nobody explains. NavBoost operates as a rank modifier on top of all other scoring systems, including the entity scores described in this patent. See also: How NavBoost Really Works.
- US11409748B1 — Passage Ranking — How heading hierarchy becomes a mathematical vector for passage-level scoring. Where entity scoring works at the page level, passage ranking works at the sub-page level. Together, they show Google scoring content at two granularities simultaneously.
- US9767157B2 — Panda (Site Quality) — Panda evaluates content quality at the site level using phrase-frequency analysis. Entity scoring determines who deserves to rank; Panda determines whether the site hosting that entity's content is quality enough to surface it.
- Quality Scoring Ensemble — Five quality models (Chard, Tofu, Keto, Rhubarb, contentEffort) run simultaneously. Entity scoring determines ranking position; quality scoring determines whether demotion applies. The two systems operate in parallel.
- US7346839B2 (Historical Data) — Entity Scoring evaluates who deserves to rank based on knowledge graph signals; Historical Data evaluates the temporal legitimacy of the links pointing to that entity's pages. Both systems must pass for a page to rank well.
- US7603350B1 (Entity Trust) — Entity Scoring evaluates entity-document connections using the RNCP formula; Entity Trust evaluates entity-entity trust propagation — how much the people who vouch for your content are themselves trusted. One scores the node; the other scores the edges between nodes.
- US9268820B2 (Knowledge Panel) — Entity scoring determines which entities are notable enough to warrant Knowledge Panel treatment. The KP patent describes the downstream presentation system — once an entity passes the scoring threshold, how does Google assemble and display the structured panel? Entity Scoring is the qualifying exam; the Knowledge Panel is the diploma.
- US8682892B1 (Implied Links) — Entity Scoring measures entity authority through the RNCP formula. Implied Links measures brand awareness through reference queries (brand searches). Both feed
CompressedQualitySignals. An entity with high scoring but disproportionate link growth triggers the modification factor — the two systems cross-validate each other.
All seven analyses are cross-referenced in my On-Page SEO guide, which provides the applied framework built on this evidence base.
Frequently Asked Questions
What does Google patent US10235423B2 actually do?
It ranks search results retrieved from the Knowledge Graph by scoring each entity on four metrics — Relatedness (R), Notability (N), Contribution (C), and Prize (P) — then combining them into a weighted score: S = a·R + b·N + c·C + d·P. The weights change based on the entity's domain.
What is the entity scoring formula?
S = a·R + b·N + c·C + d·P. R is Relatedness (entity co-occurrence across the web). N is Notability (global popularity ÷ entity type rank). C is Contribution (aggregated reviews, rankings, critical assessments). P is Prize (weighted awards and formal recognitions). The weights a, b, c, d are domain-specific.
How does entity type affect ranking in this patent?
In two ways. First, through the Notability metric: entities of more notable types within a domain score higher. Second, through domain-specific weights: the formula uses different weight sets for different domains. Prize carries more weight for movies; Notability carries more weight for people.
Does this patent prove that Knowledge Graph presence affects rankings?
Yes. The patent explicitly describes a system where search results are retrieved from the Knowledge Graph and ranked using entity-derived metrics. Stronger Knowledge Graph signals mean higher scores and higher rankings.
How does the Contribution metric work?
It aggregates quality signals from multiple sources — professional reviews, user reviews, best-seller lists, commerce reviews, and domain-specific platforms. A decay-weighted function gives the most weight to an entity's highest-rated contributions. For people, it includes a "fame metric" — the sum of contribution scores from all their associated works.
What should I do to improve my entity's score based on this patent?
Four things. Build co-occurrence (R). Ensure correct entity type classification (N). Accumulate quality contributions (C). Pursue formal recognitions and awards (P). The relative importance of each depends on your entity's domain.