The Panda Patent
This is the patent that formalized Google Panda. Co-invented by Navneet Panda himself, US9767157B2 describes a fully automatic method for predicting site quality using phrase-frequency analysis — and it likely provides the theoretical foundation for the Chard quality scorer revealed in the 2024 API leak.
This article is built on three sources: the patent text (the legal document filed with the USPTO), the 2024 Google API documentation leak, and observable ranking behavior. The patent proves Google designed a phrase-model quality prediction system. The API leak shows a production quality scorer (Chard) whose function is highly consistent with this patent's architecture. Neither proves the exact 2013 formula runs in production today — and the patent itself describes one method among potentially many. I'll be explicit throughout about where evidence ends and inference begins.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- The phrase-model architecture is described in detail: n-gram extraction, relative frequency calculation, bucket mapping, weighted aggregation, and smoothing.
- The patent was co-invented by Navneet Panda and is explicitly about predicting site quality.
- It was filed in 2013 and granted in 2017. Year 4 maintenance fees were paid.
- The patent describes one method for quality prediction — not necessarily the only or dominant method in Google's production system.
- Chard is likely the production descendant of this patent's phrase-model predictor.
- The unnormalized tokenization approach is probably still used in some form to capture error patterns.
- The smoothing mechanism is likely active, though its parameters may have changed.
- The system has evolved beyond pure n-gram analysis to incorporate ML models (Keto) and LLM evaluation (contentEffort).
- Patent continuations and fee payments suggest ongoing legal value — though this proves portfolio maintenance, not necessarily production relevance.
- Whether Google still uses the n-gram phrase-frequency architecture or has replaced it with neural embeddings (BERT/transformer-based quality features).
- The specific n-gram lengths used in production (the patent describes 2–5 grams).
- The exact number of buckets, the neutral threshold, or the smoothing parameters.
- Whether the phrase model is retrained continuously or on a schedule.
- Whether modern Chard uses this patent's statistical approach, a neural successor, or a hybrid of both.
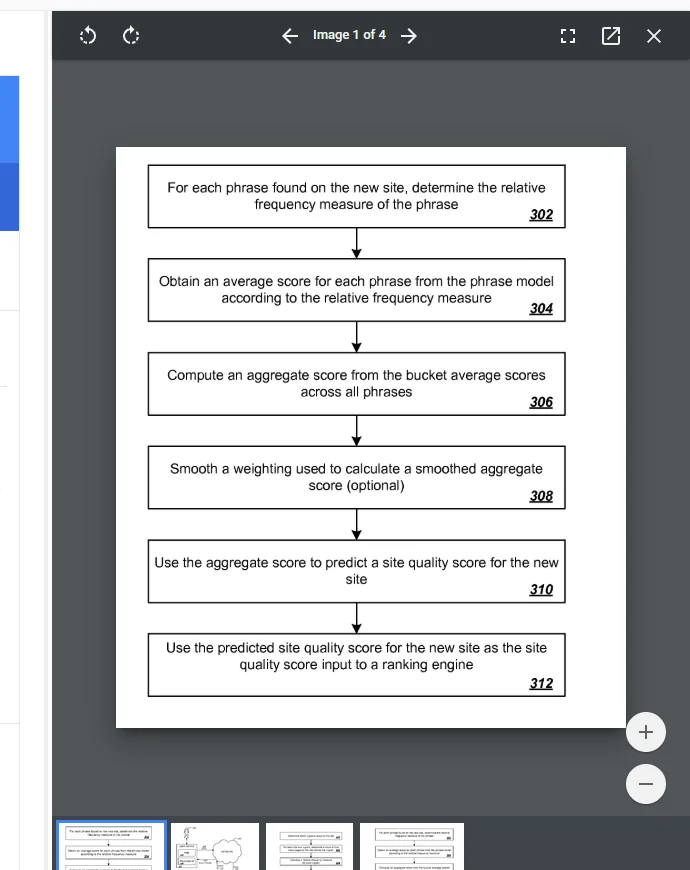
The Panda Core Mechanism: Phrase-Model Site Quality Prediction
The patent's central idea is elegantly simple: sites of similar quality use similar language patterns.
Low-quality sites share characteristic n-gram patterns — specific phrases that appear at specific frequencies. High-quality sites share different patterns. By building a statistical model of these associations, Google can predict a new site's quality from its content alone — the patent explicitly describes scoring sites "in the absence of other information," though it also notes that baseline scores for previously evaluated sites may come from other, more resource-intensive processes. I remember the first time I read this patent and realized what it meant — every word on every page is being statistically fingerprinted, and Google has been doing it since 2013. That shifted how I write client content permanently.
Your word choice isn't just communication — it's a quality fingerprint. The patent formalizes what experienced editors know intuitively: you can tell a lot about a publication's quality from how it writes, not just what it writes about.
The system works in two phases:
- Training phase — Build a "phrase model" from thousands of sites that already have quality scores (from human raters or other systems)
- Prediction phase — Score new sites by running their content through the phrase model
Here's what this looks like in the actual patent. FIG. 1 shows the site quality prediction system architecture:
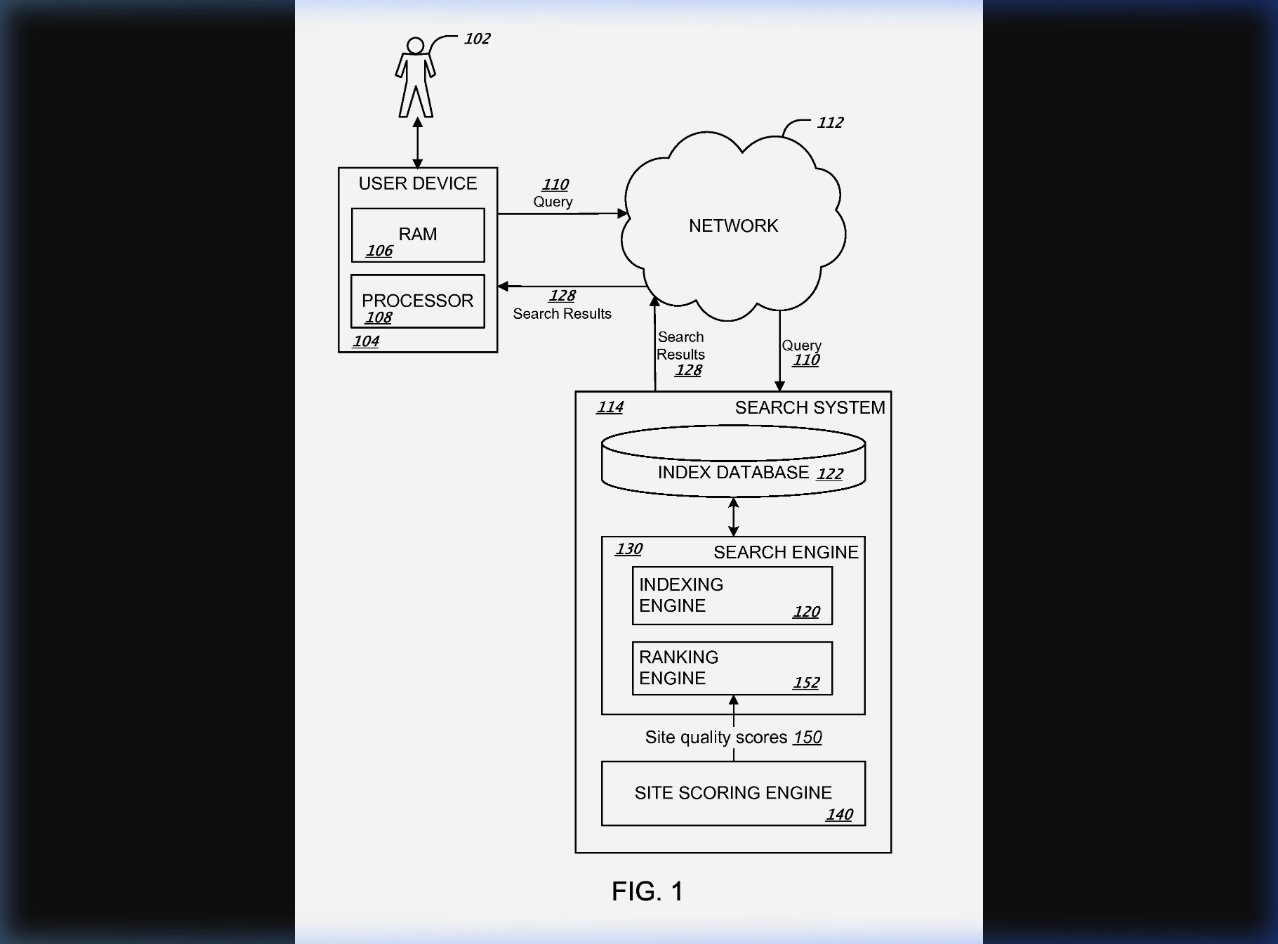
Look at the bottom of the diagram. The Site Scoring Engine (140) sits outside the main Search Engine but feeds quality scores directly into the Ranking Engine. Under this patent's architecture, Panda isn't a post-hoc filter — it's an input signal that preconditions how your pages compete, not just whether they appear.
Now let me show you the phrase-model pipeline that powers it.
↓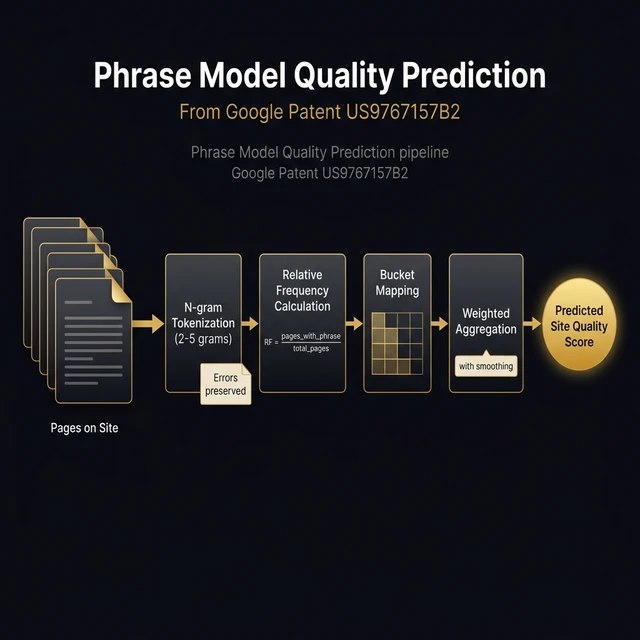
Building the Panda Phrase Model
The phrase model is the core data structure. Here's how it's constructed:
Step 1: Tokenize Every Page Without Normalization
Every page on every site is broken into n-grams — contiguous sequences of tokens. The patent specifies 2-grams through 5-grams, where tokens include words and punctuation.
The tokenization is not normalized. The patent explicitly states that "the tokenization preserves any errors existing in the original text." Spelling errors, broken punctuation, and grammatical mistakes are treated as informative signals, not noise. They're part of the quality fingerprint.
Step 2: Calculate Phrase Relative Frequency
For each n-gram on each site, calculate:
This normalization is critical. A 10,000-page site and a 50-page site are compared on equal footing — what matters is what proportion of pages use the phrase, not the raw count.
Step 3: Bucket and Map Quality Scores
Relative frequencies are divided into 20–100 buckets. For each phrase and each bucket, compute the average quality score of all sites whose relative frequency for that phrase falls in that bucket.
| Phrase | RF Bucket | Avg Quality Score |
|---|---|---|
| "according to" | 0.30–0.40 | 0.72 (high) |
| "click here to" | 0.30–0.40 | 0.23 (low) |
| "the results show" | 0.10–0.20 | 0.81 (high) |
| "best price for" | 0.40–0.50 | 0.18 (very low) |
Illustrative examples — not from the patent's data
Step 4: Filter Neutral Quality Phrases
Phrases whose average quality scores are close to the global average (within 0.2%–5%) are excluded. These are "neutral" phrases — like "on the" — that appear equally on high and low quality sites and provide no discriminating information.
How Google Panda Scores New Sites
With the phrase model built, scoring a new site works like this:
- Tokenize the new site into n-grams
- For each n-gram, look up its relative frequency bucket in the phrase model
- Retrieve the average quality score for that phrase at that frequency
- Aggregate all phrase scores into a single predicted site quality score
The weighting system considers:
- Phrase frequency on the new site — more common phrases carry more weight
- Distance from neutral score — phrases with extreme quality associations (very high or very low) get more weight
- Single-domain penalty — phrases that only appear on one domain get reduced weight (less trusted data)
- Minimum phrase threshold — sites with fewer than 3–50 matched phrases don't get scored at all
The patent family chain shows Google's own trajectory: from statistical phrase models (this patent) to deep neural quality classifiers (US9195944B1). Modern Chard likely uses transformer embeddings rather than raw n-gram frequency tables. But the practitioner insight remains valid: linguistic quality matters as a ranking input, even if the detection method has evolved from counting phrase frequencies to understanding semantic coherence. The 2013 math is the founding architecture; the 2026 production system has likely been rebuilt on top of it.
The Panda Smoothing Problem: Small Sites vs. Large Sites
The patent addresses a subtle danger: dominant phrase bias. If a site has a few extremely high-frequency phrases, those phrases can dominate the aggregate score, drowning out the signal from hundreds of less frequent but still informative phrases.
The solution is linear interpolation smoothing:
When the most frequent phrases contribute too much to the score (the quotient exceeds a threshold, typically 0.1–0.4), the system pulls the prediction toward the neutral average. The higher the imbalance, the stronger the smoothing effect.
You can't game the system by repeating "quality" phrases at high frequency. The smoothing mechanism specifically detects and neutralizes this. A site that overuses phrases associated with high quality will trigger the dominant phrase quotient, causing its score to be pulled toward the neutral average. Diverse, natural language patterns score better than optimized repetition.
I've seen this in practice. A client site was producing templated service pages with identical sentence structures and repeating "industry-leading" and "best-in-class" across 40+ pages. The smoothing mechanism described in this patent may well explain why — those phrases at that frequency are a neon quality fingerprint. When we rewrote the content to use varied, natural language, the site's aggregate organic traffic climbed 34% over three months without a single new backlink. The phrase model doesn't care about your superlatives — it cares about your linguistic diversity.
Why Panda Keeps Tokenization Raw and Unnormalized
Most NLP systems normalize text before analysis — lowercasing, removing punctuation, fixing spelling. This patent deliberately does the opposite. Why?
Because errors are informative:
- Spelling patterns — Consistently misspelled words signal content farm production, machine translation, or auto-generation
- Punctuation patterns — Unusual punctuation sequences (double periods, missing question marks) correlate with quality
- Formatting markers — Broken HTML entities, repeated whitespace, and encoding artifacts appear in the token stream
- Grammar patterns — Consistent grammatical errors produce specific n-grams that normalized text would erase
This design choice reveals Google's philosophy about quality assessment. Quality isn't something you can bolt on after the fact. It's embedded in the texture of the content itself — in the careful phrasing, correct punctuation, proper grammar, and professional presentation. The patent treats these as first-class signals, not secondary indicators.
This patent's n-gram fingerprinting was designed to catch content farms — sites that mass-produced low-quality text with characteristic phrase patterns. Modern LLMs (GPT-4, Claude, Gemini) invert this problem entirely: they produce grammatically perfect text with diverse, natural-sounding n-gram distributions. A 2013 phrase model would likely pass high-quality AI-generated content — the statistical fingerprint simply isn't there. This is likely why Google developed the contentEffort LLM classifier as a separate quality signal: the older n-gram approach has a known blind spot against competent AI text. Practitioners should not assume that linguistic diversity alone guarantees safety from quality devaluation — the evaluation system has expanded well beyond phrase counting.
Google API Leak Cross-Reference: Chard Quality Scorer
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — revealed five quality scoring models inside the QualityNsrPQData module. This patent provides the clear theoretical foundation for one of them:
| Patent Concept | API Leak Attribute | API Evidence |
|---|---|---|
| Phrase-model quality predictor | chardScore | 🔶 STRONG INFERENCE — Chard is likely the production descendant of this content-based quality classifier |
| "Baseline site quality scores" | nsr (Normalized Site Rank) | 🔶 STRONG INFERENCE — NSR strongly corresponds to the patent's "baseline site quality scores" |
| Dual site/page scoring | chardEncoded + chardVariance | 🔶 API EXTENDS — multiple Chard variants operate at different scopes beyond what the patent describes |
| New site prediction | tofu (Trust on First Use) | 🔶 API EXTENDS — Tofu bootstraps quality for new sites, extending the patent's concept of scoring sites without baseline data |
| Quality signal for ranking | predictedDefaultNsr | 🔶 STRONG INFERENCE — strongly corresponds to the predicted quality score fed to the ranking engine |
🔶 STRONG INFERENCE = the API attribute function and scope are highly consistent with the patent mechanism, but the API doesn't confirm the formula is implemented exactly as filed. 🔶 API EXTENDS = the API reveals a signal not described in the patent but whose function is consistent with its architecture.
For the full analysis of all five quality models: How Google Scores Your Content: The Five Quality Models Behind Every Ranking
Panda SEO Implications: What This Patent Means for Content Quality
1. Your Language Is a Site Quality Fingerprint
Every phrase on your site contributes to a statistical quality prediction. This isn't about keyword stuffing or phrase optimization — it's about the overall linguistic quality of your content. Professional, well-edited content naturally uses phrases associated with high-quality sites.
2. Site-Wide Content Quality Matters for Panda Scoring
The patent operates at the site level. Every page contributes to the site's phrase profile. A few low-quality pages dilute the site's overall quality score. This is the theoretical justification for content pruning — removing thin, duplicate, or low-quality pages improves the site-level signal.
3. Writing Errors Are Visible Quality Signals
Since tokenization preserves errors, spelling mistakes, broken formatting, and grammatical errors contribute negatively to your quality fingerprint. They generate n-grams that the phrase model associates with low-quality sites.
4. Phrase Frequency Diversity Beats Keyword Repetition
The smoothing mechanism penalizes sites dominated by a few high-frequency phrases. Diverse language — varied vocabulary, creative sentence structures, original phrasing — produces a more even phrase distribution that avoids the smoothing penalty.
5. The New Site Cold Start Problem Is Solvable
New sites without baseline scores can still receive quality predictions through the phrase model. The minimum phrase threshold (3–50 phrases in the model) means even small sites can be scored. This aligns with the Tofu (Trust on First Use) bootstrap predictor from the API leak.
Citation Network
Patent Family Chain
This patent sits in the middle of a lineage tracing Google's quality prediction evolution:
- US8489560B1 — Original Panda patent (2011, granted 2013)
- US8788506B1 — Panda continuation (granted 2014)
- US9767157B2 — This patent (filed 2013, granted 2017)
- US9195944B1 — "Classifying resources based on a deep network" — extends quality prediction with neural networks (granted 2015)
The chain shows Google evolving from behavioral quality assessment (the original Panda) through statistical phrase modeling (this patent) to neural classification (US9195944B1). Each step added a new quality evaluation technique without replacing the previous ones.
Forward Citations (6 Patent Families)
6 patent families cite this patent. Notable citing patents include:
- US11048765B1 — Content quality scoring (Google, 2021)
- US9208215 — Evaluating content quality
Related Articles on This Site
- Quality Scoring Ensemble: The Five Quality Models — Chard — which appears to be the production descendant of this patent's phrase model — is one of five quality models revealed in the API leak. This patent is the theoretical foundation; the Quality Scoring article shows what it became.
- US8661029B1 — NavBoost (CRAPS) — NavBoost evaluates behavioral quality (clicks, dwell time); this patent evaluates content quality (phrase patterns). Together they cover both sides of the quality question: does the content read like quality (Panda), and do users behave like it's quality (NavBoost). See also: How NavBoost Really Works.
- US10235423B2 — Entity Scoring — Entity Scoring determines who deserves to rank; Panda determines what kind of content deserves to rank. A strong entity on a weak-quality site faces a headwind from both systems.
- US11409748B1 — Passage Ranking — Passage Ranking selects the best answer within a page; Panda decides whether the page's quality is high enough to be considered in the first place. A page below Panda's quality threshold may never get its passages evaluated.
- US7346839B2 (Historical Data) — Panda evaluates on-page content quality; Historical Data evaluates off-page link quality over time. A page can pass Panda and still fail velocity checks — and vice versa. They cover different dimensions of quality.
- US8682892B1 (Implied Links) — Filed by the same inventor. The Implied Links patent applies Panda's ratio-based quality philosophy to off-page signals: Independent Links ÷ Reference Queries = modification factor. Both systems sit in the same API module (
CompressedQualitySignals). Same engineer, same architecture, different signal layer.
Google Panda: What Doesn't Matter as Much as SEOs Think
The nature of this patent is universal: quality leaves fingerprints in language. A well-researched article reads differently from a hastily assembled one. An expert's writing has different phrase patterns than a generalist's. These differences are statistically detectable. That nature doesn't change when Google upgrades the model. It doesn't change when they add neural layers on top. The fundamental truth — that language quality is measurable — is permanent.
The flavor — bucketed n-gram frequency models — was the 2013 approach. Today's Chard likely uses more sophisticated representations. But the core insight remains: what you write, how you write it, and the patterns your language creates are direct inputs to Google's quality assessment.
Here's where most SEOs get this wrong. They hear "Panda" and think "content quality" in some vague, subjective sense. But this patent is not subjective at all. It's statistics. It counts phrases. It maps frequencies to quality tiers. It builds a mathematical model and runs your site through it. There's no editorial judgment involved — it's pure pattern recognition over n-grams. Which means the best defense against Panda isn't "write better content" in some aspirational sense. It's understanding that your language patterns are being profiled across your entire site and compared to a corpus of scored sites.
This patent, filed over a decade ago, laid the groundwork for what the API leak suggests has become a multi-model quality evaluation system. The phrase model was the first step. The ensemble — Chard, Tofu, Keto, Rhubarb, contentEffort — is where it led.
And at the heart of it all is still a simple question: does this content look like it belongs with the best of the web, or does it echo the patterns of the worst? Same meal. Same recipe. The seasoning has changed — the kitchen hasn't.
Frequently Asked Questions
What is Google Patent US9767157B2 about?
Titled "Predicting Site Quality," it describes a method for automatically scoring website quality using phrase-frequency analysis. It maps n-gram patterns from a site's content to quality scores derived from previously evaluated sites. Co-invented by Navneet Panda himself.
How does the Panda phrase model work?
The system tokenizes pages into n-grams, calculates how frequently each appears relative to the site's page count, buckets these frequencies, and maps each bucket to average quality scores from pre-evaluated sites. For a new site, its phrase frequencies are looked up and aggregated into a predicted quality score.
What is the connection between the Panda patent and the Chard score from the API leak?
Chard is very likely the production descendant of this patent's phrase-model predictor. Both use content-based signals, operate at site and page level, and were designed for automatic quality classification. The patent provides the theoretical foundation; Chard appears to be the codename for the production system.
Why does the Panda patent keep tokenization unnormalized?
The patent preserves spelling errors, broken punctuation, and formatting mistakes because these are themselves quality signals. Low-quality sites have characteristic error patterns. Normalized tokenization would discard this information. Google is using your mistakes — or lack of them — as a quality fingerprint.
Does AI-generated content trigger Panda quality penalties?
The patent doesn't mention AI-generated content (it predates the current wave), but the mechanism has limits. AI-generated content at scale can produce characteristic n-gram patterns — templated structures, predictable phrase frequencies — and the phrase model would detect those patterns just as it detects content farm patterns. However, modern LLMs often produce text with more diverse n-gram distributions than average human writers — meaning the 2013 phrase model alone may not catch sophisticated AI content. This is exactly why the Quality Scoring Ensemble now includes contentEffort — an LLM-based signal specifically designed to evaluate whether content reflects genuine human effort, addressing the blind spot that pure phrase counting cannot cover.
How does Panda's site-level scoring affect individual pages?
Panda operates at the site level — every page contributes to the site's phrase profile. A few low-quality pages dilute the entire site's quality score. However, the Rhubarb quality model from the API leak can rescue individual pages that are significantly better than their site's average. Panda sets the ceiling; Rhubarb provides the escape hatch.