Every SEO guide tells you to write "quality content." None of them show you the five machine learning models Google appears to use to determine whether your content qualifies as quality. The 2024 API leak revealed them all — five quality-scoring attributes co-located in a single module, structured in a way that strongly suggests a coordinated evaluation system.
This article is built on one primary source: the 2024 Google API documentation leak — specifically the QualityNsrPQData module. The leak reveals attribute names, data types, and module structure. It does not reveal scoring formulas, model weights, or how these attributes interact at runtime. Where I connect API attributes to observable ranking behavior or patent mechanisms, I'll flag it as inference. The API gives us the vocabulary of Google's quality system — not its grammar.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this research:
- The
QualityNsrPQDatamodule exists and contains five quality-scoring attributes. - Their names (
chardScore,tofu,ketoScore,rhubarbScore,contentEffort) appear in the leaked API schema. - Chard has multiple variants including YMYL and hoax detection.
- Tofu is a bootstrap predictor for new URLs.
- Keto is a
VersionedFloatSignal. - Rhubarb is described as a site-URL delta signal.
contentEffortis LLM-based.- These signals feed into Panda/BabyPanda demotion scoring.
- Chard likely implements the phrase-model architecture from Patent US9767157B2.
- Tofu's bootstrap function is consistent with the observed "sandbox" effect for new sites.
- Keto's versioning may explain why quality guidelines seem to shift without announced updates.
- The ensemble architecture is an ML best practice and fits the observed behavior.
contentEffort's LLM-based approach is consistent with why AI-generated content performs worse since late 2023.- The system has evolved beyond this 2024 snapshot — Keto's versioning virtually guarantees model updates.
- The exact weights each model receives in the final quality computation.
- The specific ML architectures behind Keto and
contentEffort. - How frequently each model is retrained.
- Whether additional quality models exist beyond these five.
- The exact threshold at which Rhubarb can override a site-level penalty.
- How
contentEffortdistinguishes AI-assisted content from AI-generated content. - Whether the attribute names and structure have changed since the early 2024 snapshot.
The Source: Google's QualityNsrPQData Module
In March 2024, an automated bot accidentally pushed over 2,500 pages of Google's internal Content Warehouse API documentation to a public GitHub repository. SEO researchers Mike King and Rand Fishkin brought the leak to public attention, revealing more than 14,000 attributes used in Google's ranking systems.
Among the most significant revelations was a module called QualityNsrPQData — a data structure that encapsulates page-level quality signals feeding directly into Google's core ranking systems. Inside this module sit five quality scoring models, each with a food-related codename, each evaluating your content from a different angle.
NSR stands for Normalized Site Rank — Google's unified site-level quality score. The "PQ" in QualityNsrPQData stands for Page Quality. This module bridges the gap between site-level authority and page-level content assessment. It's where site reputation meets individual page quality.
Google later acknowledged the leak's authenticity while cautioning against "inaccurate assumptions" based on "out of context, outdated, or incomplete information." That's Google's way of saying: yes, these documents are real, but the system is more complex than what you can see here.
Google's Quality Scoring Ensemble: Five Models, One Verdict
Wait. Let me translate that to human.
What you're looking at is Google's actual internal data structure — the raw API schema that defines quality-scoring attributes. Each line is a quality signal: chard appears to be the baseline quality score, contentEffort likely evaluates authoring effort, keto is their most actively versioned quality model, rhubarb measures a page-vs-site quality delta, and tofu provides an initial score for new URLs. These are the variable names Google's engineers typed into the codebase — though the exact scoring logic behind each name is not revealed.
Google doesn't run one quality check. The API leak reveals five quality-scoring models, each measuring a different dimension of quality:
| Model | What It Measures | Scope |
|---|---|---|
| Chard | Content quality baseline | Site + Page level |
| Tofu | Initial quality for new URLs | Page level (bootstrap) |
| Keto | Versioned quality prediction | Site + Page level |
| Rhubarb | Page quality vs. site quality delta | Page-relative-to-site |
| contentEffort | LLM-judged authoring effort | Page level |
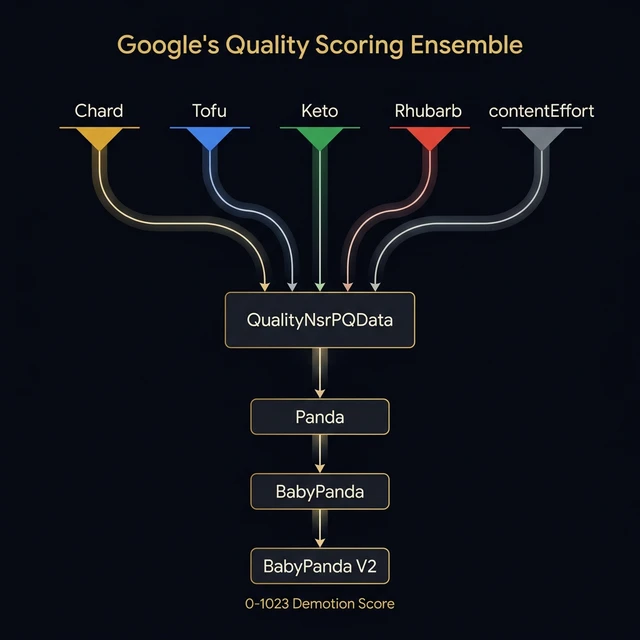
The co-presence of five quality attributes in a single module is consistent with ensemble architecture — the same approach used in modern ML systems where multiple models contribute to a prediction, and the aggregate is more reliable than any individual model. If these models do function as an ensemble, disagreement between them would reduce confidence while agreement would increase it.
This API documentation was leaked in early 2024. Keto's VersionedFloatSignal data type tells us Google actively deploys new model versions — meaning the quality ensemble has very likely been updated since. The attribute names and ensemble structure are probably stable (Google rarely renames core infrastructure), but the specific model weights, versions, and thresholds are not frozen. Treat this as the architecture of the system, not its current tuning.
Google's engineering teams have a long tradition of using unconventional internal codenames. The Panda update was named after its co-inventor, engineer Navneet Panda. Penguin and Hummingbird followed the animal-themed convention. The quality scoring models — Chard, Tofu, Keto, Rhubarb — continue the tradition with their own food-themed twist. It's an engineering culture thing, not a meaningful signal about the systems themselves.
Google's Chard Quality Scorer: The Content Quality Baseline
Google's Chard Model
Role: Content-based quality predictor operating at both page and site level
API attributes: chardScore, chardEncoded, chardVariance
Chard is the baseline quality classifier — the model most consistent with the original Panda algorithm's design. It evaluates content quality using content-based signals (not behavioral or link-based), generating a score that describes how inherently good or bad a page's content is.
What makes Chard distinctive is its variant system. The API leak reveals multiple Chard variants, each specialized for different detection tasks:
- Standard Chard — General content quality assessment
- Hoax detection variant — Identifies misinformation and factually unreliable content
- Translated content variant — Detects machine-translated or poorly translated pages
- YMYL variant — Applies heightened scrutiny to Your Money or Your Life content (health, finance, safety)
If your site covers health, financial, or safety topics, the YMYL variant of Chard applies stricter thresholds. The same content quality that passes for a recipe blog may fail for a medical advice page. This is why YMYL sites need demonstrably higher E-E-A-T signals — the scoring bar itself is higher.
Chard's dual-level operation (page AND site) means it generates two signals: how good this specific page is, and how good the entire site is. The site-level signal creates a ceiling. If your site's aggregate Chard score is low, individual pages face a headwind — unless Rhubarb rescues them (more on that below).
Chard's Patent Connection to Google Panda
Chard is likely the production implementation of the phrase-model quality prediction described in Patent US9767157B2 (Predicting Site Quality), where n-gram frequency patterns are mapped to baseline quality scores. The patent, co-invented by Navneet Panda himself, describes precisely this kind of content-based quality predictor.
Google's Tofu Quality Model: Trust on First Use
Google's Tofu Model — Trust on First Use
Role: Bootstrap quality predictor for new URLs with no behavioral history
API attributes: tofu
Every new page has a cold start problem. NavBoost needs click data. Chard needs enough content to analyze. Behavioral signals take weeks to accumulate. So how does Google decide where a brand-new page should rank?
Tofu — likely Trust on First Use — appears to be a predictive quality score assigned to new URLs before they have any history, giving them a starting position in search results.
Based on its bootstrap function, Tofu likely evaluates signals such as:
- Site-wide quality signals — The parent domain's existing quality scores (inheriting from Chard's site-level assessment)
- Technical health indicators — Page speed, mobile-friendliness, proper markup
- Topical alignment — Whether the new page's content is consistent with the site's established topical focus
- Outbound link profile — What the page links to as an indicator of its quality neighborhood
☝ The API reveals tofu as a single numeric attribute — these input dimensions are inferred from its bootstrap function, not from the API documentation itself.
The SEO community has long speculated about a "Google sandbox" for new sites. Tofu is a plausible candidate mechanism. A low Tofu score wouldn't mean Google ignores your page — it would mean Google assigns a cautious initial quality estimate. Over time, the Tofu score would be superseded by a more comprehensive predictedDefaultNsr score built from actual behavioral data and content analysis. If this reading is correct, the "sandbox" is really just Tofu being conservative.
The implication is clear: new pages on established, high-quality domains get a better starting position than new pages on fresh domains. This isn't a conspiracy — it's a sensible bootstrapping strategy. If a domain has consistently produced quality content, its next page is likely quality too.
Google's Keto Quality Model: The Versioned Predictor
Google's Keto Model
Role: Versioned quality predictor — Google's newest and most actively evolving model
API attributes: ketoScore (VersionedFloatSignal)
Keto is Google's most actively versioned quality model, described in the API documentation as a VersionedFloatSignal. That data type is significant — it means Google can deploy new versions of Keto independently, and the versioning structure is consistent with A/B testing different model iterations.
While Chard appears to use a phrase-model approach (rooted in the 2013 Panda patent), Keto's architecture is unknown. The VersionedFloatSignal type tells us the output format, not the model behind it — though the versioning pattern is consistent with modern ML deployment practices.
What the versioning tells us:
- Continuous improvement — Google isn't running one static quality model. Keto gets updated, and each version is tracked separately
- A/B testing capability — Different Keto versions can run on different traffic segments, allowing Google to validate improvements before full rollout
- The quality bar moves — Content that scored well under Keto v1 might score differently under Keto v3. The target is moving
Keto likely exists alongside Chard because ensemble methods are more reliable than single models. If both Chard and Keto score a page as low quality, the combined signal would be stronger than either alone. If they disagree, the other attributes (Tofu, Rhubarb, contentEffort) provide additional data points. This kind of redundancy is standard ML practice for exactly this reason — resilience to any single model's blind spots.
Google's Rhubarb Quality Model: The Page-Site Delta Scorer
Google's Rhubarb Model — The Escape Hatch
Role: Measures the quality difference between a specific page and its parent site
API attributes: rhubarbScore (site-URL delta signal)
Rhubarb answers the question every content creator on a mediocre domain has asked: "Can my individual page overcome my site's reputation?"
The answer appears to be yes — and Rhubarb is the strongest candidate mechanism.

- Positive Rhubarb → Page is better than the site average. The page can rise above its domain's quality ceiling
- Zero Rhubarb → Page is consistent with its site. Standard site-level signals apply
- Negative Rhubarb → Page is worse than the site average. Even a strong site can't save a weak page
If this reading is correct, Rhubarb explains why a single exceptional article on an otherwise average blog can rank on page one — and why a phoned-in page on an authoritative domain can still fail. Without a page-site delta signal, quality would be purely site-level — penalizing every page on a weak domain and rewarding every page on a strong one. The delta mechanism adds nuance: individual pages get individual verdicts.
This has profound implications for content strategy. You don't need to fix every page on your site before your best content can rank. You need to make your best content demonstrably better than your site average. Rhubarb will notice.
Google's contentEffort Quality Model: The LLM-Based Quality Judge
Google's contentEffort Model
Role: LLM-based evaluation of demonstrable human authoring effort
API attributes: contentEffort
This is the newest and most remarkable signal in the ensemble. Google is using a large language model to evaluate whether content shows genuine human effort — and the signal feeds directly into ranking.
Based on its alignment with Google's Quality Rater Guidelines, contentEffort likely evaluates dimensions such as:
| Dimension | What It Looks For | Low-Effort Signal |
|---|---|---|
| Utility | Does the content solve the user's problem? | Generic advice, surface-level coverage |
| Expertise | Does the author demonstrate domain knowledge? | Wikipedia-style summaries, no depth |
| Originality | Does the content add something competitors don't? | Rehashed talking points, template content |
| Trustworthiness | Are claims sourced? Is authorship clear? | Unsourced assertions, anonymous content |
☝ The API reveals contentEffort as a single attribute — these evaluation dimensions are inferred from alignment with Google's Quality Rater Guidelines, not from the API documentation itself.
contentEffort is the strongest candidate for Google's defense against scaled AI content. An LLM evaluating LLM output — looking for signs of genuine human investment that AI-generated content consistently lacks: original data, first-hand experience, unique methodology, real case studies. Content that could have been generated by prompting ChatGPT with "write a guide about X" would likely score poorly on contentEffort, regardless of how polished it reads — though the exact scoring criteria are not revealed in the API schema.
The contentEffort Connection to Google's E-E-A-T Framework
contentEffort is the strongest candidate for a technical implementation of E-E-A-T's "Experience" dimension. When Google's Quality Rater Guidelines say "Does the content demonstrate first-hand experience?" — contentEffort is likely the system that answers that question at scale, algorithmically.
| E-E-A-T Dimension | Technical Signal | How It's Measured |
|---|---|---|
| Experience | contentEffort | LLM evaluates first-hand knowledge, original examples |
| Expertise | isAuthor + relevanceScore | Author detection, topic relevance |
| Authoritativeness | isPublisher + normalizedTopicality | Publisher detection, topical focus |
| Trustworthiness | nsr + scamness + spambrainLavcScore | Site quality, scam detection |
☝ These E-E-A-T-to-API mappings reflect attribute function alignment — Google has not published an official mapping between E-E-A-T dimensions and specific API attributes.
How Google's Quality Scoring Ensemble Feeds the Three Pandas
The five quality models don't produce a ranking directly. They feed into Google's quality firewall — the Three Pandas:
| Variant | Scope | Demotion Range |
|---|---|---|
| Panda | Site-level | 0–1023 |
| BabyPanda | Page-level | 0–1023 |
| BabyPanda V2 | Page-level (updated model) | 0–1023 |
Each Panda variant produces a granular demotion score from 0 to 1023. This isn't binary pass/fail — it's a sliding scale. A page might receive a BabyPanda demotion of 150 out of 1023, meaning it's not severely penalized but is slightly held back compared to higher-quality competitors.
Key signals that likely contribute to the Panda demotion calculation:
contentEffort— from the ensemblepage2vecLq— neural similarity to known low-quality pagesclutterScore— ad density and layout qualityspambrainLavcScore— AI-generated content fingerprintsracterScores— additional auto-content detection
Content is created → Chard/Keto/Tofu/Rhubarb/contentEffort evaluate it → These signals feed Panda/BabyPanda → Panda produces a demotion multiplier → The demotion multiplier adjusts the page's ranking potential, working alongside NavBoost, Entity Scoring, and Passage Ranking.
Patent Connection: Google's Panda Patent US9767157B2
While the five quality models are API leak revelations, the theoretical foundation traces back to a specific patent: US9767157B2 — Predicting Site Quality, co-invented by Navneet Panda and Yun Zhou.
The patent describes a phrase-model architecture for predicting site quality:
- Collect n-grams (2-grams through 5-grams) across all pages on a site
- Calculate relative frequency — how often each phrase appears relative to the site's total content
- Map frequencies to quality scores — using baseline scores from previously-evaluated sites
- Aggregate — compute a weighted average across all phrases to produce a site quality score
- Smooth — apply linear interpolation to prevent outlier phrases from dominating the prediction
The patent reveals that the language you use signals your quality tier. Low-quality sites share linguistic patterns — specific n-grams that appear at characteristic frequencies. High-quality sites share different patterns. Chard likely implements this phrase-model approach as its content analysis foundation. The phrases on your pages are likely being statistically compared to patterns from millions of scored sites.
Read the full patent analysis: Patent US9767157B2: Predicting Site Quality — The Panda Patent
How to Score Well Across All Five Google Quality Models
| Model | What Drives High Scores | Common Mistakes |
|---|---|---|
| Chard | Original, comprehensive content with professional language patterns | Template content, thin pages pulling the site average down |
| Tofu | Publishing on an established, quality domain with clear topical focus | Launching on a fresh domain with no quality history |
| Keto | Continuously improving content — the model evaluates current state | Leaving content stale and outdated |
| Rhubarb | Making individual pages significantly better than your site average | Making every page the same quality — no standouts |
| contentEffort | Original data, case studies, methodology, first-hand experience | Generic AI-generated content with no unique contribution |
If these five models do function as an ensemble, the design philosophy is clear: quality is hard to fake along all dimensions simultaneously. You might game one signal temporarily — write polished prose that satisfies contentEffort, or publish on a strong domain that inherits favorable Tofu scores. But scoring well across Chard, Tofu, Keto, Rhubarb, AND contentEffort at the same time, consistently, across every page? That starts to resemble actually creating quality content. The ensemble structure — if we're reading it correctly — makes authenticity the path of least resistance.
Citation Network
Source Evidence
Unlike the patent-based analyses in this series, the Quality Scoring Ensemble draws from API leak evidence rather than granted patents. The primary source is the QualityNsrPQData module within the leaked Content Warehouse API, corroborated by Google's acknowledgment of the leak's authenticity.
Patent Foundation
- US9767157B2 — Panda (Site Quality) — The phrase-model architecture in this patent is the theoretical backbone for Chard. It describes the n-gram frequency analysis that Chard likely implements. The patent predates the API leak by over a decade.
Related Articles on This Site
- US8661029B1 — NavBoost (CRAPS) — NavBoost feeds click data alongside these quality signals. Quality scoring gates entry; NavBoost reorders what remains. Together they are the two halves of Google's quality-and-satisfaction loop. See also: How NavBoost Really Works.
- US10235423B2 — Entity Scoring — Entity scoring determines ranking position; quality scoring determines whether demotion applies. The two systems operate in parallel — who ranks is determined by entity metrics; whether they stay ranked is determined by quality signals.
- US11409748B1 — Passage Ranking — Passage ranking operates at the sub-page level while quality scoring evaluates at the page level. contentEffort likely examines the same heading structures that passage ranking uses as mathematical vectors.
- US7346839B2 (Historical Data) — Historical Data's temporal link signals feed into the same quality aggregation pipeline. The velocity and freshness checks from this 2003 patent contribute to the overall quality picture that Chard, Keto, and the ensemble evaluate.
- US7603350B1 (Entity Trust) — Entity Trust evaluates whether the people behind content are themselves trusted. Quality scoring evaluates whether the content itself is quality. Together they answer two questions: is this content good, and should we believe the person who wrote it?
Quality Scoring: What Doesn't Matter as Much as SEOs Think
The nature of this system is ancient: good content is recognizable. Humans can tell the difference between a carefully researched article and a template. Between original investigation and rehashed summaries. Between writing that comes from experience and writing that comes from autocomplete.
The ensemble is Google's attempt to mechanize that recognition. Five different models looking at the same page, each asking a different version of the same question: is this genuinely good?
The flavor will change. Keto will get new versions. contentEffort's LLM will improve. Chard's YMYL variant will evolve. New models might join the ensemble. Old ones might be retired.
But the nature — evaluating content from multiple independent angles and using consensus to determine quality — is permanent. It's how peer review works. It's how editorial boards work. It's how any serious quality evaluation system works. Google is doing at machine scale what humans have done for centuries: getting multiple independent opinions and trusting the consensus.
The practical takeaway is brutally simple. Create content that five different quality evaluators, each looking at different aspects, would all call "good." That's your north star. Not one metric. Not one optimization. Five independent judges, all agreeing.
That's a high bar. It's supposed to be.
Frequently Asked Questions
What are Google's five quality scoring models?
Chard (content quality baseline), Tofu (trust on first use for new URLs), Keto (versioned ML predictor), Rhubarb (page vs. site quality delta), and contentEffort (LLM-based authoring effort estimation). All five were revealed in the 2024 API leak within the QualityNsrPQData module.
What is Rhubarb and how does it help individual pages?
Rhubarb measures the quality gap between a specific page and its parent site. A positive Rhubarb score means the page is better than the site average — allowing it to rank higher than the site's general quality ceiling would permit. This is how standout content on mediocre domains can still rank.
What is contentEffort and how does Google measure it?
contentEffort is an LLM-based signal where an AI model likely evaluates demonstrable human effort in content creation. Based on alignment with the Quality Rater Guidelines, it appears to assess dimensions like utility, expertise, originality, and trustworthiness — making it the strongest candidate for E-E-A-T's "Experience" implementation. These evaluation dimensions are inferred, not confirmed by the API schema.
How do the five models work together?
As an ensemble. The five signals feed into the Three Pandas (Panda, BabyPanda, BabyPanda V2) which produce granular demotion scores from 0 to 1023. When multiple models agree on quality, the system has high confidence. Disagreement leads to other signals breaking the tie.
What is the QualityNsrPQData module?
A data structure within Google's Content Warehouse API that encapsulates page-level quality signals. It feeds directly into core ranking systems and contains all five quality models plus additional attributes like clutterScore, page2vecLq, and spambrainLavcScore. It was revealed in the 2024 API leak.
How can I improve my quality scores?
Create genuinely comprehensive, original content with first-hand examples (contentEffort). Build consistent site-wide quality (Chard). Make individual pages even stronger than your site average (Rhubarb). Ensure new pages launch with strong technical foundations (Tofu). Keep content updated (Keto evaluates current state).