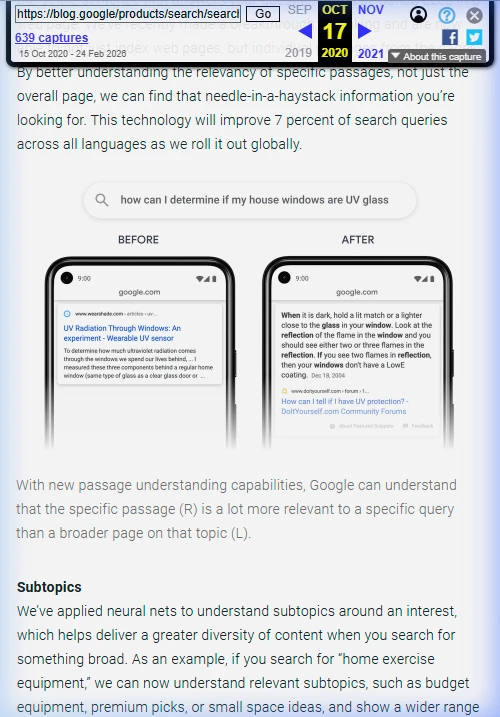
In October 2020, Google published a one-line announcement: passage ranking "will improve 7 percent of search queries across all languages as we roll it out globally." No explanation of the mechanism. No technical details. When I dug into the patents behind it, I found something worth understanding: not what passage ranking does, but why the heading structure matters at the mechanism level. It isn't about keywords in headings. It's about constructing a mathematical path from your page title to every answer you want to claim. US Patent 11,409,748 B1 is that mechanism, and it was filed eight years before Google announced it publicly.
This patent describes a core mechanism for passage-level answer selection — how Google decides which section of your page to promote as the answer, and which ones it passes over. If you've read my On-Page SEO guide, this is the evidentiary source for Section 3.
This article interprets a granted Google patent (filed 2014, granted 2022) alongside corroborating API attributes and DOJ trial testimony. The patent describes the mechanism's design intent — not necessarily its current implementation, which has likely evolved with neural approaches. Where claims are inferred rather than confirmed, I've aimed to say so.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- Google filed this patent in 2014, received the grant in 2022, and it's currently active.
- The patent describes a specific system for scoring passages using heading vectors — 5 sub-systems with explicit formulas.
- Google publicly confirmed passage ranking as a live feature in October 2020, describing it as operational across 7% of queries at launch.
- The API leak reveals
headingTagWeightas a real attribute — a strong match for this patent's mechanism of differentially weighting terms by heading position. - The
sectionHeadingAnchoredExpansionattribute strongly matches this patent's description of heading-anchored passage boundaries. - DOJ trial testimony established that Google's ranking stack operates at sub-page granularities (Tr. 6330:25–6332:11) and layers traditional and neural systems (Tr. 6440:13–18) — consistent with passage-level scoring being operational.
- That the specific scoring formulas in this patent (depth thresholds, boost factors, coverage ratios) are implemented in production as described, rather than evolved since the 2014 filing.
- That the API attributes we cite map directly to this patent's data structures rather than a later, unpatented implementation.
- That the depth threshold value of 2 (used in the patent's worked example) is still the production value.
- That the rigid multipliers and depth thresholds have been superseded by dynamic, multi-dimensional weights determined by neural networks like BERT and MUM. We use the patent's numbers to illustrate the architectural logic, not as literal production values.
- Exactly which combination of the 5 scoring sub-systems is active in any given query or vertical.
- Whether the boost factors are static values or ML-learned parameters that vary by topic area.
- Whether a neural passage embedding model has partially or fully superseded this patent's explicit vector mechanism — patents describe inventions at a point in time, not current implementations.
- How Privacy Sandbox changes affecting Chrome click data interact with the DOJ-described NavBoost feedback loop for featured snippets.
Patent Metadata
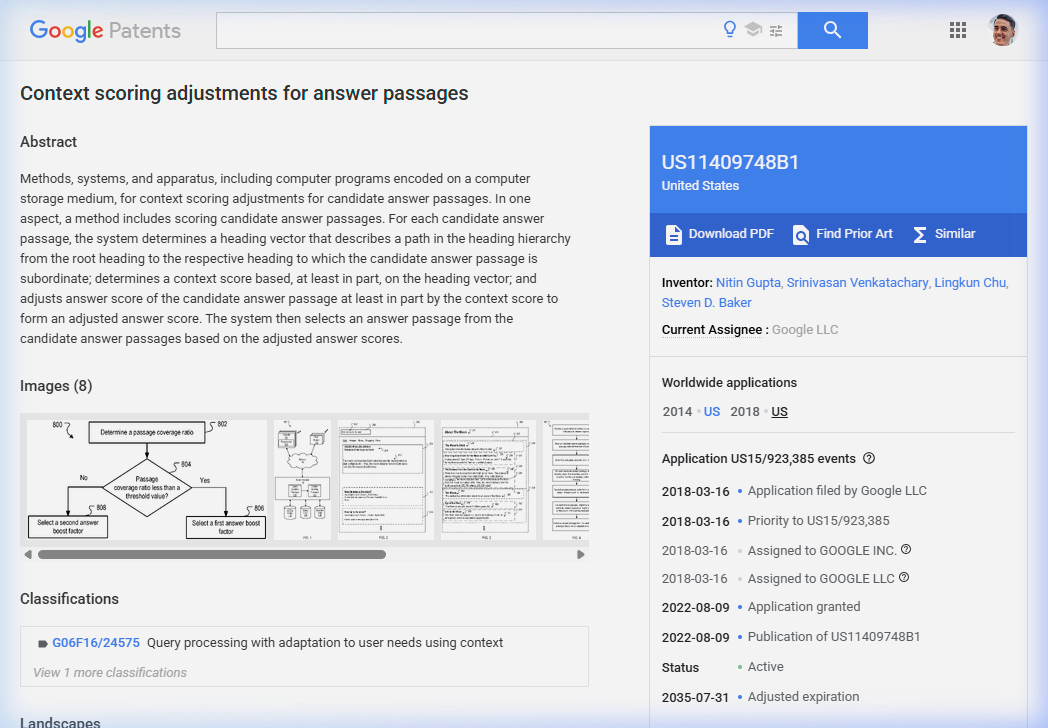
That filing date matters as context. Google was building and testing heading-based passage scoring before the SEO industry had clear evidence that heading hierarchy carried algorithmic weight. By the time Google told the SEO world passage ranking existed, the concept behind passage ranking had been in development for at least six years before anyone outside Google knew it existed.
What This Patent Does (Plain English)
Google doesn't just need to find the right page — it needs to find the right passage within the page. The one that actually answers the question. This patent describes the scoring system that decides which passage wins.
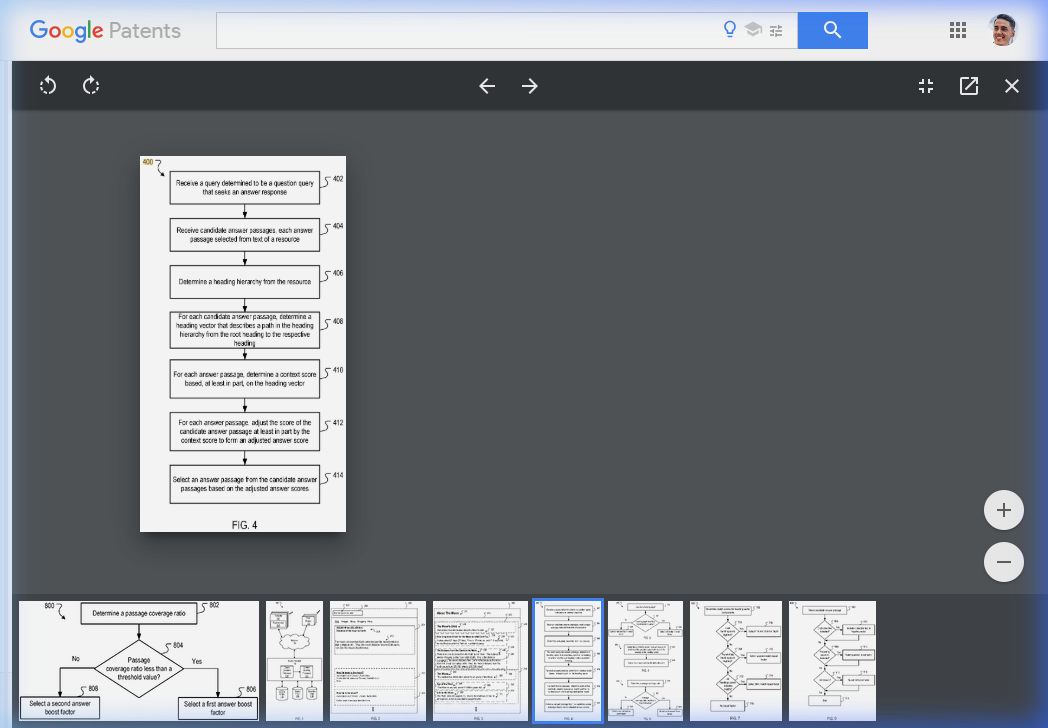
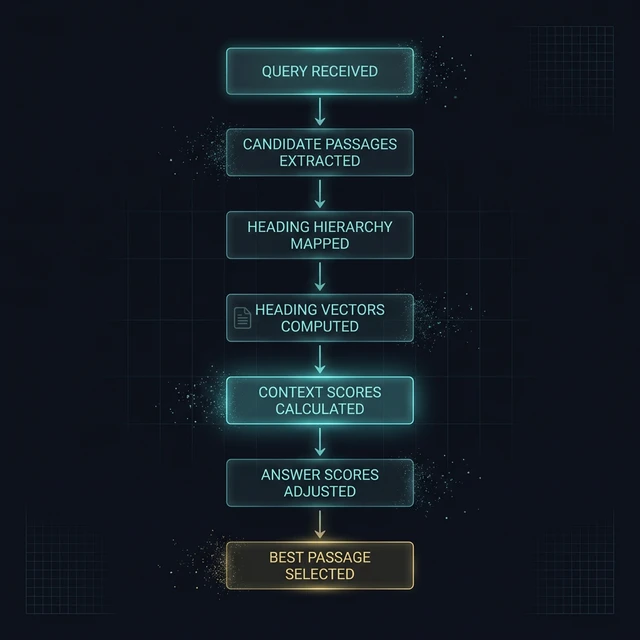
Here's the five-step process:
- Receives candidate answer passages — text sections from pages that could potentially answer the query
- Maps the heading hierarchy of each page — parsing the DOM tree to identify heading tags (H1, H2, H3) and their parent-child relationships
- Computes a heading vector for each candidate passage — an ordered path from the root heading down to the heading the passage sits under
- Calculates a context score based on that heading vector — using depth, text similarity, and heading match patterns
- Adjusts the original answer score by the context score — passages with better heading context rise; those without it sink
The output: the passage with the highest adjusted answer score is selected. And the thing that adjusts the score — the mechanism this entire patent describes — is your heading structure.
Here's what this looks like in the actual patent. This is FIG. 4 — the core algorithmic flow:
Wait. Let me translate that to human.
↓
The Core Mechanism: 5 Scoring Sub-Systems
The patent doesn't describe one scoring method — it describes five, each using the heading vector differently. The context scoring processor can implement any of these alone or in combination. Here's what each one actually does:
1. Heading Depth Scoring — How Deep Is the Passage? (FIG. 5)
The simplest mechanism. The system counts how many heading levels deep a passage is from the root. If the depth exceeds a threshold (the patent uses 2 as an example), the passage gets a depth boost.
"Deep passage scores are increased relative to shallow passage scores… The deeper the depth, the greater the increase in the answer score."
What this means directly: a passage under a generic H1 like "About Our Company" has depth 1 — no boost. A passage under H1 → H2 → H3 about the exact thing the user searched for has depth 3 — maximum boost. I've seen this play out in featured snippet gains after restructuring flat article layouts into properly nested hierarchies. The content didn't change. The headings did. The snippet changed within weeks.
2. Heading Text Similarity — Does Your Heading Match the Query? (FIG. 6)
The system compares the text of headings in the heading vector against the query. It can compare the closest heading alone, or concatenate multiple heading texts for comparison. Standard similarity measures: term matching, synonym matching.
The patent's own worked example: for the query "How far away is the moon," a heading vector containing [The Moon's Orbit → The Distance from the Earth to the Moon] scores higher than [The Moon's Orbit → How long does it take to orbit Earth?] — because "distance" semantically matches "far away." This is not keyword stuffing — it's heading specificity rewarded.
3. Multi-Level Heading Match — Which Level of the Hierarchy Best Matches? (FIG. 7)
The most sophisticated scoring mechanism. It generates three separate match scores and assigns different boost weights to each:
| Match Level | What's Compared | Boost Factor |
|---|---|---|
| Last heading | Query vs. the heading directly above the passage | Highest boost |
| Penultimate | Query vs. last heading + its parent heading combined | Medium boost |
| All headings | Query vs. all headings in the vector concatenated | Lowest boost |
The hierarchy here is deliberate. If the heading directly above the passage matches the query — highest boost. If you need to reach up to the parent heading to construct a match — lower boost. If you need all headings to collectively imply relevance — lowest boost. The implication: the heading closest to your content matters most. Your H3 should be able to stand alone as an answer to the query, not depend on H1 context to be relevant.
4. Passage Coverage Ratio — How Much of the Section Does the Passage Cover? (FIG. 8)
This is about completeness. The system calculates how much of the full text section the candidate passage covers. A passage that captures most of its parent section's content gets a boost; a small fragment doesn't.
The threshold values mentioned in the patent: 0.3, 0.35, or 0.4. Below the threshold — no boost. Above it — boost factor scales with coverage. This is why featured snippets tend to pull from passages that feel self-contained and complete, not fragmentary. A two-sentence answer buried in an 800-word section that wanders in multiple directions is fighting an uphill battle.
5. Additional Passage Ranking Features — Bold Text, Questions, and Lists (FIG. 9)
Three more signals the system evaluates:
- Distinctive text detection — bolded text within a passage that isn't a header is added to the heading vector, effectively increasing depth by 1. Bolded key terms = additional specificity signal at no additional heading cost.
- Preceding question detection — if a question appears in text before the candidate passage, the passage gets a proximity-based boost that's inversely proportional to text distance. Question heading directly above the answer → highest boost.
- List detection — lists in the center of a page, without excessive links, receive a list boost factor. This explains why "step N: do X" formatted answers appear so often as featured snippets for procedural queries.
Use question-format headings. Bold the terms that carry the most query relevance within your paragraphs. Structure instructional content as numbered lists. The patent is explicit about which features trigger scoring boosts — and these three require zero additional keyword research to implement.
Key Patent Text: What Google Actually Filed
Here's the actual patent language — the specific claims and definitions that make this analysis concrete rather than speculative.
The Heading Vector Definition
"For each candidate answer passage: determining a heading vector that describes a path in the heading hierarchy from the root heading to the respective heading to which the candidate answer passage is subordinate."
That one claim sentence is the whole mechanism. Your heading structure is converted into a vector — a mathematical object with direction (the path through your heading hierarchy) and magnitude (the depth, a count of levels). The passage isn't scored in isolation; it's scored in relation to its position in the page's heading tree.
How Google Parses the DOM for Heading Structure
"The context scoring processor processes heading tags in a DOM tree to determine a heading hierarchy."
Let me show you what this looks like in practice. The patent uses a "Moon" page as its worked example. This is FIG. 3 — the literal page structure Google used to explain heading vectors:
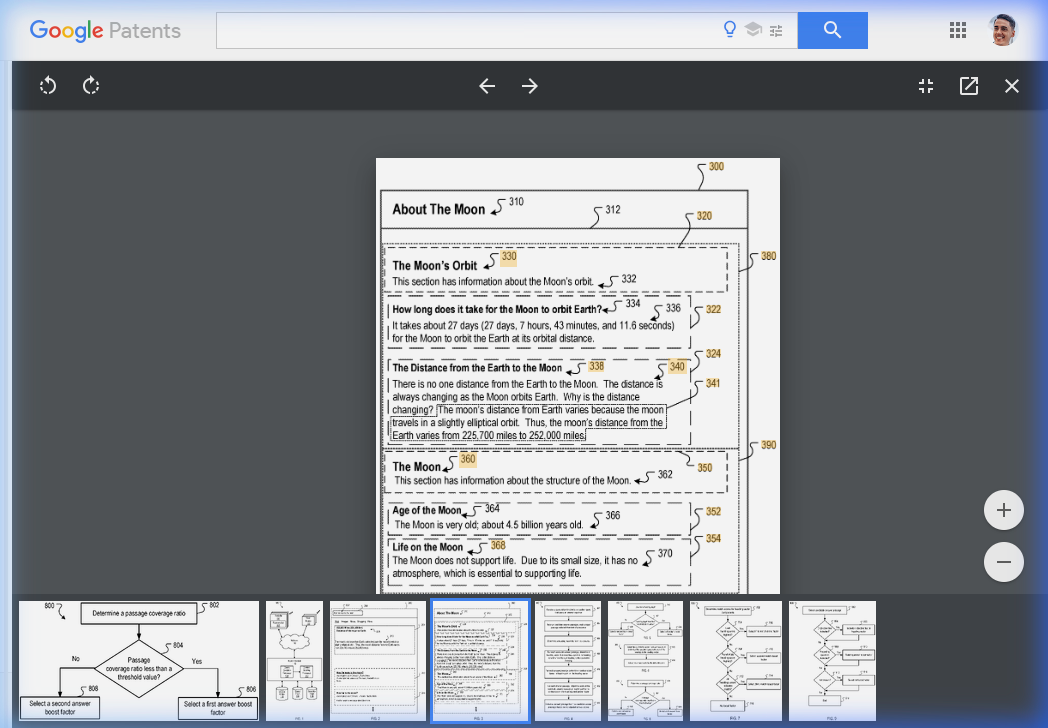
Now let me show you what Google actually sees.
↓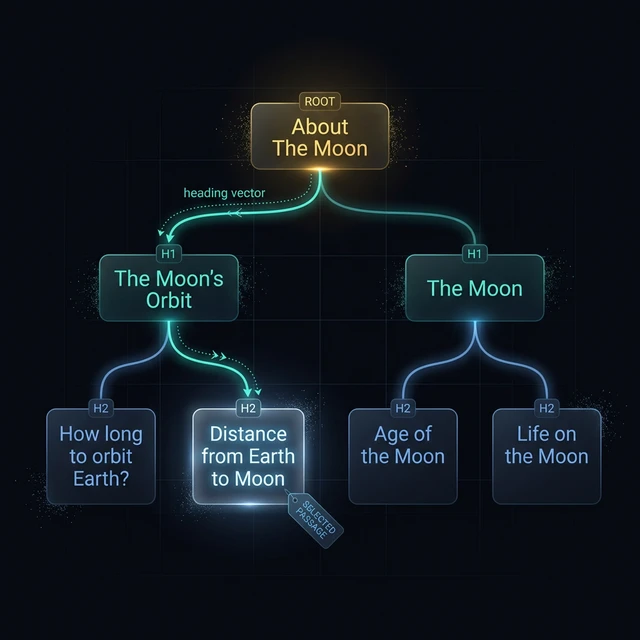
The heading vectors for passages within this page would be:
V1 = [ROOT: "About The Moon" → H1: "The Moon's Orbit" → H2: "How long to orbit Earth?"]
V2 = [ROOT: "About The Moon" → H1: "The Moon's Orbit" → H2: "Distance from Earth to Moon"]
V3 = [ROOT: "About The Moon" → H1: "The Moon" → H2: "Age of the Moon"]For the query "How far away is the moon," V2 wins the context scoring. The heading text "Distance from Earth to Moon" is semantically similar to "how far away." V1 and V3 both lose on heading text similarity — not because they're bad headings, but because they're not heading toward the right answer.
The Heading Depth Boost — Exact Patent Language
"An answer score can be adjusted based on the depth of the heading vector. A first adjustment occurs for a depth of 1; a second adjustment for the depth of 2; a third adjustment for the depth of 3; and so on. The deeper the depth, the greater the increase in the answer score."
The patent is explicit: deeper = higher adjusted score. Every additional heading level you add — when it genuinely organizes your content — gives Google more specificity to work with and gives your passage a scoring advantage.
What Passage Ranking Means for Your On-Page SEO
After working with this patent across client audits, here's what I actually change in practice:
1. Headings Are Scoring Inputs, Not Labels
Every heading on your page becomes a node in the heading vector. The text of each heading is compared against user queries for every passage it's an ancestor of. If your H2 says "More Information" instead of "Distance from Earth to the Moon" — you're actively degrading the context score of every passage beneath it. I audit this by checking whether each heading, read alone, tells you precisely what the content beneath it answers.
2. Heading Hierarchy Depth Is an Explicit Ranking Feature
An older convention suggested Google only processes H1 and H2 meaningfully. This patent says otherwise: deeper heading structures generate longer heading vectors, which receive higher depth boosts. I use H3s and H4s freely — but only when each level adds genuine specificity to the one above it. Adding an H3 that says "Details" under an H2 that said "Overview" is noise. Adding an H3 that narrows the topic of the H2 to a specific sub-question is useful depth.
3. Question Headings Trigger Two Boosts Simultaneously
The preceding question detection mechanism in FIG. 9 rewards passages preceded by a question. If you format a heading as a question matching a common query (heading text similarity boost) and immediately answer it in the body text (preceding question proximity boost), you're stacking two scoring mechanisms on the same passage. For featured snippets specifically, this combination is the strongest structural advantage the patent describes.
4. Flat Page Structure → Reduced Heading Match Advantage
The multi-level heading match system tests three scenarios: last heading alone, penultimate heading, and all headings combined. Deeper hierarchies unlock the strongest comparisons — the "last heading" match gives the highest boost because it's the most specific. A flat page where everything sits under H2 with no nesting still gets heading comparisons, but it loses the depth advantage that comes from distinguishing between parent and child headings. The patent's scoring rewards specificity at each level, so pages with H1 → H2 → H3 hierarchy have more opportunities to score well on heading similarity. Flat pages aren't disqualified — they're structurally limited in how many scoring advantages they can access.
5. Bold Key Terms Within Passage Text
Bolded text that isn't a header gets added to the heading vector as an effective depth increment. It's the smallest signal in the patent, but it costs nothing. I bold the terms within each paragraph that carry the most relevance to the query the section targets — not every term, just the anchor terms.
Rule 1: Every heading must describe the content beneath it — not summarize, not tease, describe.
Rule 2: Build nested hierarchies where each level adds specificity. H3 should narrow H2; H4 should narrow H3.
Rule 3: For featured snippets: question-format heading + immediate answer + bolded key terms in that answer.
Google API Leak Cross-Reference: Heading Vector Implementation
The 2024 Google API documentation leak — first reported by Rand Fishkin and investigated in depth by Mike King at iPullRank — revealed several attributes that align directly with this patent's mechanisms:
| Patent Mechanism | API Attribute | API Evidence |
|---|---|---|
| Heading text as a scored term source | headingTagWeight in SignalTermData | ✅ STRONG MATCH — explicit weighting of terms by heading tag level |
| Per-term differentiation by document position | SignalTermData (15 attributes per term including position) | ✅ STRONG MATCH — tracks whether a term appears in heading vs. body |
| Section-anchored passage boundary expansion | sectionHeadingAnchoredExpansion | ✅ STRONG MATCH — passage boundaries are determined by heading hierarchy |
| Passage selection for display as featured answer | richSnippetDocumentInfo | 🔶 API EXTENDS — output stage of the system; API confirms display formatting |
| Heading depth as a differentiator | headingTagDepth | 📜 PATENT ONLY — no direct API attribute; inferred from headingTagWeight structure |
✅ STRONG MATCH = the API attribute exists and its name/structure aligns closely with this patent mechanism. This confirms the data structure is present in production, not that Google implements this specific patent's formula as described.
The API leak provides attribute names and data types — not the actual scoring formulas. The patent provides the formulas. Together they form a strong evidentiary chain: the patent describes the system; the API shows the data structures used to implement it. The headingTagWeight attribute alone is enough to corroborate that heading tags are treated as differentially-weighted scoring inputs. That's the core claim of this patent, supported by production data.
Where the DOJ Trial Corroborates Passage Ranking
The DOJ v. Google antitrust trial (2023–2024) didn't cite this patent directly, but produced testimony relevant to passage-level scoring — though no exhibits addressed passage ranking specifically:
- Sub-page granularity in retrieval: Google VP Pandu Nayak testified that Google's retrieval system processes documents at sub-page granularity (Tr. 6330:25–6332:11), and that traditional ranking systems like NavBoost and QBST operate on specific user interactions with individual results (Tr. 6405:15–22). While this testimony addresses retrieval and click scoring rather than passage ranking specifically, it establishes that Google operates at granularities below the full URL.
- Result-level interaction logging: Eric Lehman confirmed that Google "logs data about every search result that appears on the SRP" (UPX0870 at .016), and that "scoring teams extract both narrow and general patterns" from user interactions including "a long look" at knowledge panels (UPX0228 at -502). This is consistent with — though not proof of — passage-level engagement tracking.
- Traditional and neural systems coexist: Nayak testified that BERT "does not subsume big memorization systems, navboost, QBST, etc." (Tr. 6440:13–18), establishing that Google's ranking stack layers multiple approaches — traditional and neural — rather than replacing one with the other. This supports the patent's continued relevance alongside newer ML approaches.
The most relevant DOJ contribution for this patent: establishing that Google's ranking stack operates at sub-page granularities and layers multiple scoring approaches — exactly the architecture this patent describes. The trial didn't cite this patent directly, but the operational testimony is consistent with passage-level scoring being live.
Citation Network
Patent Family Chain
US9959315B1 (parent — original 2014 filing) → US11409748B1 (this continuation — 2022 grant)
Forward Citations (Patents Citing This Patent)
| Patent | Relevance |
|---|---|
| US20220045954A1 | Directly cites this patent — extends passage answer scoring with additional contextual signals beyond heading vectors. |
Patent Family (Same Application, Different Jurisdictions)
| Patent | Jurisdiction |
|---|---|
| WO2015166508A1 | International (WIPO) |
| US10467343B2 | United States |
| CN115033671A | China |
| WO2024063776A1 | International (WIPO) — 2024 filing extends this lineage |
Related Articles on This Site
- US10235423B2 (Entity Scoring) — the entity formula
S = a·R + b·N + c·C + d·Poperates at the page level; this patent operates at the passage level. Together they show Google scoring content at two levels of granularity simultaneously. Your entity score affects which page ranks; your passage score affects which answer it shows. - US8661029B1 (NavBoost / CRAPS) — when this patent's scoring selects a passage as a featured snippet and a user clicks it, that click feeds NavBoost. Passage ranking selects the answer; NavBoost records whether users found it satisfying. The selection and the feedback loop are distinct systems that reinforce each other. See also: How NavBoost Really Works.
- US9767157B2 (Panda) — Panda evaluates site-level content quality before passage ranking applies. A site below Panda's quality threshold may not get its passages considered at all. Passage depth scoring only helps if you've already cleared Panda's bar.
- Quality Scoring Ensemble — Google's
contentEffortsignal evaluates whether your content demonstrates practitioner expertise. Featured snippet candidates that pass passage ranking scoring are then subject to quality filtering — good heading structure gets you nominated; actual expertise determines if you win. - US7346839B2 (Historical Data) — where this patent evaluates the on-page heading structure, Historical Data evaluates the off-page link graph over time. Together they represent the on-page + off-page scoring foundations. A page with perfect heading hierarchy still needs temporally consistent links to rank.
Heading Vectors: What Doesn't Matter as Much as SEOs Think
The nature of this patent is that your content's structure is a scoring input, not just a usability feature. That truth doesn't change regardless of implementation. Google needs to locate answers within pages. Some mechanism maps structural context to passage relevance. Whether it's a formal heading vector or a neural embedding trained on heading structure, the underlying requirement is the same: your headings need to say what they mean.
The flavor — the five sub-systems, the explicit depth thresholds, the coverage ratios — was the 2014 approach. By 2022 when this patent was granted, I'd expect substantial ML evolution on top of the core mechanism. The heading vector math is probably not running verbatim. What's likely still running: the differential weighting of terms by heading position, the passage boundary determination by heading hierarchy, and the basic principle that a passage under a specific, query-relevant heading wins over one under a generic ancestor.
To put it in engineering terms: Google's incentive is always to minimise the cost of extracting the right answer at scale. Even for advanced LLMs, parsing an answer from a clean heading hierarchy is computationally cheaper than extracting it from an unstructured wall of text. By following the structural principles this patent describes, you're reducing Google's cost of extraction — making your answer easier to index, retrieve, and cite than your competitors'. That economic reality persists regardless of whether the scoring mechanism is a 2014 formula or a 2026 neural model.
What I tell clients, and what I think this patent actually says if you read it as principle rather than formula: don't write headings for humans and assume Google will figure out the rest. Write headings for the question you're trying to answer. Use them to build a hierarchy that traces the path from "what is this page about" down to "what does this specific paragraph answer." The heading vector is Google trying to follow that path. Make the path easy to follow.
Most SEOs I talk to are still debating whether H3s matter. The patent says they matter because they give Google more path to follow. The mechanism was designed in 2014. We just didn't see it until now.
From Patent Heuristic to Neural System
A fair question for discerning readers: if Google now runs Transformers, BERT, and MUM, why does a 2014 rule-based patent still matter?
The answer is in how machine learning systems are built. Early Google patents — including this one — describe heuristics: explicit, hand-coded rules like "add a depth boost for passages under H3." When Google transitioned to deep-learning ranking (starting with RankBrain in 2015, then BERT in 2019, and MUM in 2021), they didn't discard these heuristics. They used them to generate the training labels for their neural networks. The AI learned that passages structurally nested under specific, relevant headings tend to answer queries better — because the heuristic data said so.
This distinction matters for how you read the math in this article. The literal formulas — depth threshold of 2, coverage ratio checks, explicit heading vector concatenation — are likely not running as hardcoded if/then statements in 2026. But the architectural intuition those formulas encoded is baked into the neural models that replaced them. A Transformer doesn't "count" heading levels. It converts the full DOM structure into a semantic embedding — a high-dimensional vector where well-structured passages cluster closer to matching queries than unstructured ones.
The practical implication is the same either way: a passage wrapped in a logical H2 → H3 hierarchy produces a denser, more specific embedding than the same text floating in a flat page. You're not optimising for the 2014 multiplier. You're optimising for the architectural principle the multiplier was designed to capture — and which the neural systems learned from it.
This patent uses "heading vector" to mean a literal DOM path: [Root → H2 → H3]. Modern systems use "vector" to mean a semantic embedding — a list of hundreds of numbers representing meaning. Both usages are correct in their context. The structural path this patent describes is now likely an input to the embedding, not a standalone scoring signal. Your heading hierarchy still shapes the vector — it just feeds a neural model rather than a formula.
Frequently Asked Questions
What does Google patent US11409748B1 actually do?
It scores individual passages within a page by converting the heading hierarchy (H1→H2→H3) into a mathematical heading vector, then comparing that vector's text and depth against the user's query. Passages with heading paths that closely match the query receive higher context scores and are more likely to appear as featured answers.
Does this patent prove that heading structure affects rankings?
The evidence is strong. The patent describes heading tags being parsed from the DOM and converted into passage scoring inputs — heading depth boosts, heading-to-query similarity scores, and heading match patterns all adjust passage answer scores. The API leak's headingTagWeight attribute corroborates that heading-level weighting exists in the production data structure. Together, they provide the strongest available evidence that heading structure is an active ranking signal — though patents describe design intent, not necessarily current implementation.
What is a heading vector in this patent?
A heading vector is an ordered path from the root heading (typically the page title) through each parent heading down to the heading under which a passage appears. For example, if a passage sits under an H3, the heading vector is [ROOT → H1 → H2 → H3]. Google uses this vector for depth scoring, text similarity scoring, and multi-level heading match scoring. The vector has both direction (the path) and magnitude (the depth level).
How does heading depth affect passage scoring?
Deeper passages receive higher boost factors. The patent defines a depth threshold — passages below the threshold are classified as "shallow" and scored lower. The patent uses 2 as an example threshold: depth of 1 gets a first adjustment; depth of 2 gets a second, larger adjustment; depth of 3 gets a third, even larger adjustment. Deeper always wins over shallower, all else being equal.
Is passage ranking the same as passage indexing?
No. Passage indexing means Google can separately index individual passages of a page. This patent — Context Scoring Adjustments for Answer Passages — describes how Google scores and selects the best passage to display as a featured answer. They're related but distinct: passage indexing is about what enters the index; this patent is about what gets selected as the answer when a query fires.
What should I do differently with my headings based on this patent?
Three things. First, make every heading genuinely describe the content beneath it — Google checks heading-to-passage text similarity and the heading closest to the passage matters most. Second, build a nested hierarchy where H3s narrow H2s and H4s narrow H3s — deeper, well-structured sections score higher on depth boost. Third, use question-format headings where the query is known — the patent explicitly rewards passages preceded by questions with proximity-based boosts, which stack with heading text similarity.
Does the page title count in the heading vector?
Yes. The patent calls it the "root heading" — the top of the hierarchy from which all vectors are traced. Every passage on your page starts its heading vector from this root. A page title that's too generic (like "Blog Post" or "Product Page") means every passage on that page starts with a weak root node. A specific, query-relevant title strengthens every heading vector on the page simultaneously.