The Implied Links Patent
In 2012, Navneet Panda — the Google engineer whose name became the Panda algorithm — filed a patent that did something the SEO industry still hasn't fully absorbed. He formally defined two types of incoming signals: "express links" (the hyperlinks we've been building and obsessing over for twenty years) and "implied links" (unlinked brand mentions). Both feed the same bucket. Both count. But here's the part nobody quotes: the patent divides your total links by your branded search volume. Build links faster than your brand grows, and you trigger the exact demotion system the Panda creator designed.
If you've read my analysis of the Entity Trust patent, that system determines who Google treats as authoritative. This patent works on a different question: once your signals are counted — links and mentions combined — are they proportional to your actual brand awareness? Entity Trust measures the social graph. This patent measures the ratio between your signal profile and your real-world presence. It's the quality check on your entire off-page footprint.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- The patent formally defines "implied links" as references to a target resource that are NOT hyperlinks — and counts them alongside express links in the same quality signal (Claim 1)
- The modification factor formula divides independent links by reference queries (branded/navigational searches by unique users)
- The API leak confirms
webrefEntities(entity annotations per page),siteAuthority(site-level quality score in Q*),scaledIndyRank(independence scoring), andnavDemotion(navigational query classification) — all components of this patent's mechanism - Navneet Panda is the named inventor — the same engineer whose name became the Panda algorithm
- The patent expired in March 2022 (Year 8 maintenance fees not paid) — the same expiration pattern seen with Seed Distance and the Low Quality Classifier, indicating absorption into core production systems
- WebRef's entity annotation system is the production infrastructure for detecting implied links — every page gets entity mentions identified with salience scores
- NavBoost's navigational query classification is the reference query counting system — it processes branded/navigational click signals exactly as described
siteAuthorityin the API is the descendant of the modification factor — a site-level quality score produced by the links-to-brand ratio (or its neural evolution)- The patent's expiration indicates the concept was absorbed into production systems (WebRef, NavBoost, CompressedQualitySignals) — no longer needing patent protection
- The exact weight of implied links vs. express links in the numerator — whether they're counted equally or discounted
- Whether the current implementation uses entity salience scores to weight implied links (a high-salience mention counting more than a passing reference)
- The exact partition boundaries for cohort-based normalization — how Google groups "similar-sized" brands
- Whether the modification factor is still a standalone formula in 2026 or has been absorbed as one feature among hundreds in a neural quality scorer
Patent Metadata
The filing date is September 2012 — just 19 months after the original Panda update launched in February 2011, and filed by the same engineer. This matters for credibility: the Panda algorithm was the most significant content quality update in Google's history. When the person it was named after files a patent about off-page signal quality, the implications carry the same architectural weight. Vladimir Ofitserov, the co-inventor, was also a Google ranking engineer. This was not a speculative filing — it was a production team's architecture.
What This Patent Does (Plain English)
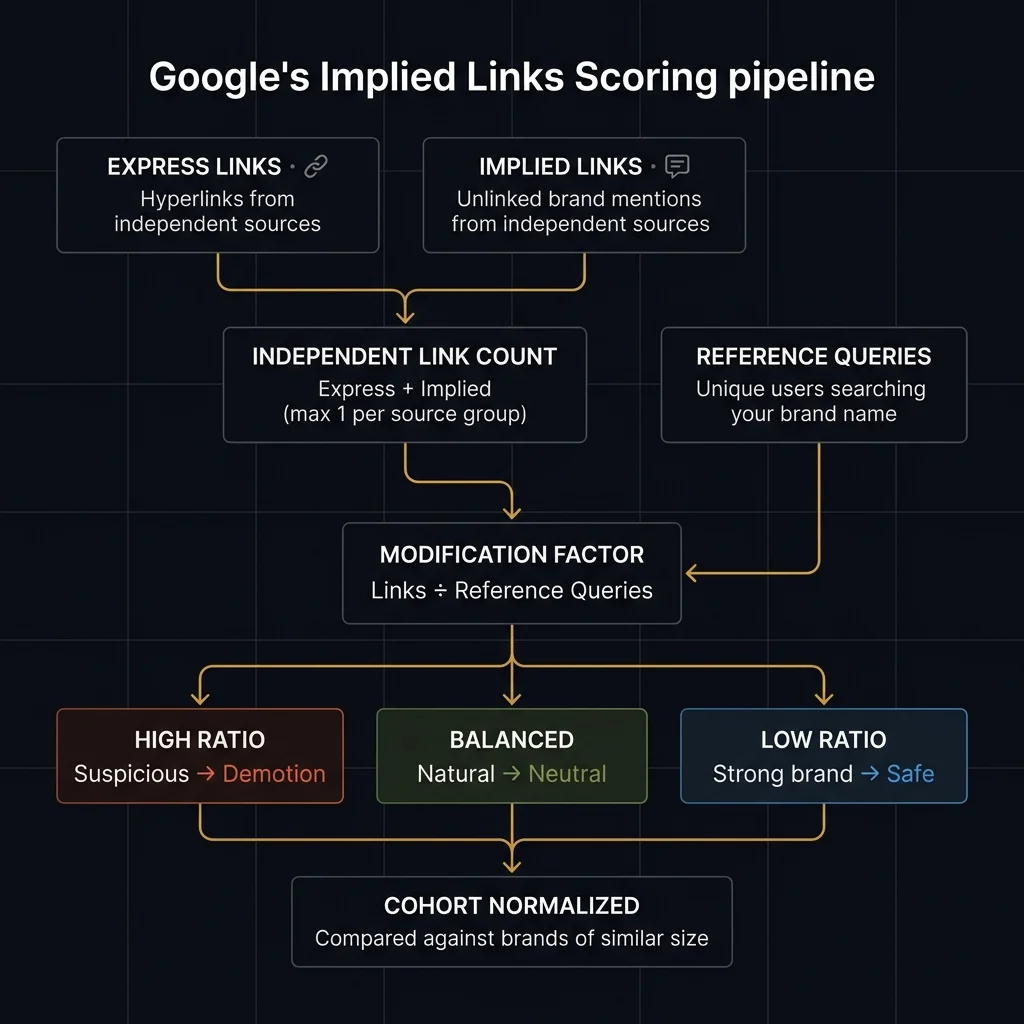
This patent creates a parallel signal channel to hyperlinks for ranking. It addresses a problem Google has been dealing with since link-based ranking began: links can be bought, manufactured, and scaled independently of actual brand authority. The patent's solution is to add a second type of signal — brand mentions without links — and then check whether the total signal count is proportional to real-world brand awareness.
Here's what the system does:
- Count express links — traditional hyperlinks from other websites, filtered for independence (same-owner, same-CSS, duplicate sources removed)
- Count implied links — unlinked brand mentions, citations, and name references from independent sources. "A resource in the group can be the target of an implied link without a user being able to navigate to the resource by following the implied link."
- Add them together — express links + implied links = total independent link count for a site
- Count reference queries — the number of unique users who searched for your brand name, domain, or navigational variations
- Divide — Independent Link Count ÷ Reference Query Count = modification factor
- Normalize — compare your modification factor against other sites with similar branded search volume (cohort-based)
- Apply to rankings — multiply initial ranking scores by the modification factor, with guardrails for navigational queries and very low-scoring results
Let me translate that to human.
↓
Express Links vs. Implied Links: The Dual Signal Channel
The patent formally defines two types of incoming signals. This taxonomy is the foundation of everything else in the patent:
Express Links
The patent defines an express link as:
"An express link, e.g., a hyperlink, is a link that is included in a source resource that a user can follow to navigate to a target resource."
This is the traditional backlink — the signal the entire link building industry is built on.
Implied Links
The patent defines an implied link as:
"An implied link is a reference to a target resource, e.g., a citation to the target resource, which is included in a source resource but is not an express link to the target resource."
And critically:
"A resource in the group can be the target of an implied link without a user being able to navigate to the resource by following the implied link."
A press mention. A podcast transcript. An industry report. A blog post that names your brand but doesn't link to you. A social media reference. A forum discussion. Every time your brand is mentioned without a hyperlink — from an independent source — that's an implied link. And it counts in the same bucket as a traditional backlink.
Independence Criteria
The patent doesn't count every mention. Both express and implied links are filtered through independence criteria. ALL must pass:
| Criterion | What It Means |
|---|---|
| Different groups | Source and target must be on different domains |
| Not likely related | Source and target groups must not share the same owner, host, or creator |
| Not a duplicate | Source is not a copy of the target content |
| Not structurally identical | Source and target don't share identical CSS, content, images, or formatting |
And one more rule: at most one independent link is counted per source group. Ten articles on the same website mentioning your brand count as one implied link — or, alternatively, as the logarithm of the actual count.
This patent was filed in 2012. The express/implied link taxonomy described here was the 2012-era approach — a rules-based counting system with explicit independence filters. In 2026, the detection of entity mentions across the web is handled by WebRef, Google's entity recognition system confirmed in the API leak. WebRef annotates every crawled page with entity mentions and salience scores. The architecture — counting both linked and unlinked brand references — likely persists. The implementation — explicit rules vs. neural entity resolution — has likely evolved substantially. The independence criteria probably run through learned models (related to IndyRank) rather than hand-coded CSS comparisons.
The Modification Factor Formula
Here's the thing. The patent doesn't just count your links and mentions. It does something more pointed — it checks whether your signal count is proportional to your actual brand presence.
Step 1: Count Independent Links
Step 2: Count Reference Queries
Step 3: Calculate
Let me show you what that looks like.
Step 4: Apply to Rankings
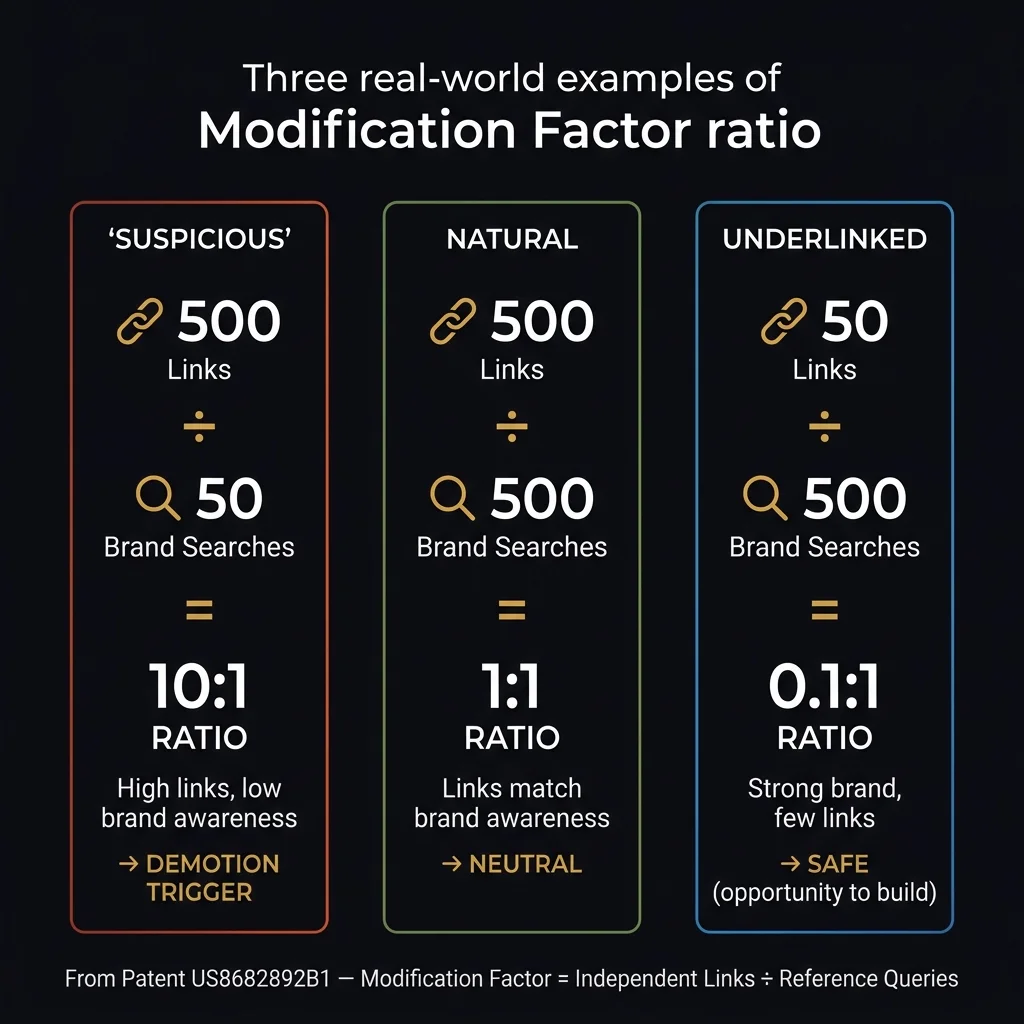
An agency builds 500 links to a client site. The client has 30 unique branded searchers per month. The modification factor is approximately 500 ÷ 30 = 16.7. Compared to other brands with similar branded search volume, this ratio is orders of magnitude higher than natural. The patent's modification factor adjusts their ranking scores downward. Every additional link built without a corresponding increase in brand awareness makes the ratio worse.
Cohort Normalization: You're Compared to Your Peers
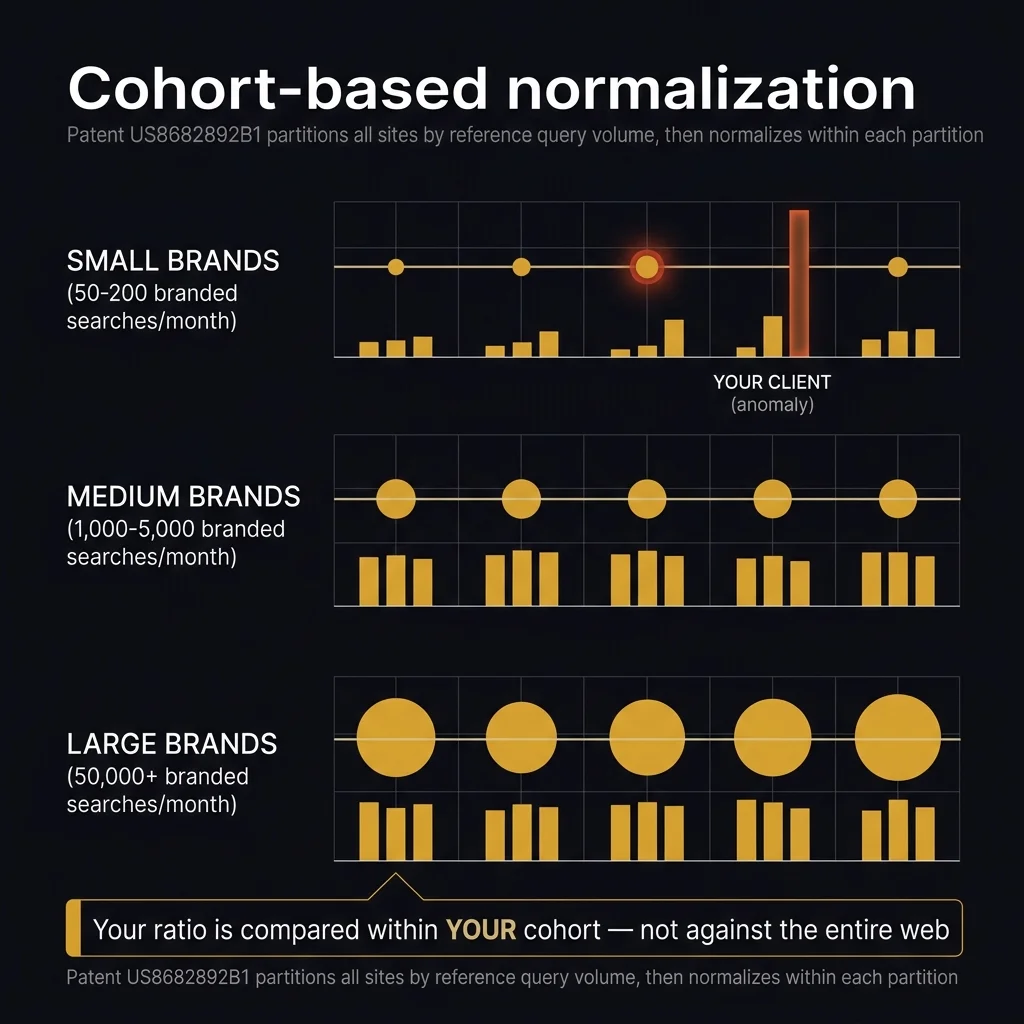
The system doesn't compare your local bakery to Nike. The patent normalizes within partitions:
- Partition all sites by reference query count — sites with similar branded search volume are grouped together
- Calculate a statistical measure — mean, median, mode, min, or max of the modification factors within the partition
- Normalize each site's factor — your modification factor is compared against the statistical measure for your cohort
This means a small business with 100 branded searches is compared to other businesses with ~100 branded searches. If most businesses at that search volume have 50–150 independent links, and your client has 2,000 — the cohort normalization catches the anomaly. You can't hide behind "we're a small brand, of course our ratio is different." The system explicitly accounts for size.
The API leak reveals siteChunk and secondarySiteChunk in the NSR (Normalized Site-level Rating) module — site grouping keys used for quality scoring. While the primary purpose of site chunking may be broader than this patent, the infrastructure to partition sites by characteristics for comparative scoring exists in production. The patent's cohort normalization has a plausible implementation path in the API.
The Navigational Exemption: How Real Brands Get Protected
The patent includes a critical guardrail: if a user's query is navigational — if they're searching specifically to reach your site — the modification factor is set to 1.0. No change applied.
This is the anti-false-positive mechanism. When someone searches "getmelinks" or "alejandromeyerhans.com," Google recognizes the navigational intent and doesn't apply the quality modification. The user wants to reach that specific site — demoting it would be a bad search experience.
But the implication runs deeper. If nobody navigational-searches for your brand, you don't get the exemption. Navigational traffic isn't just traffic — it's an immunity signal. The navigational exemption protects established brands. New brands or brands without recognition get the full force of the modification factor.
The patent treats navigational classification as binary — either the query is navigational or it isn't. The API reveals something more nuanced: pnav (navigational probability) is a continuous score with a click denominator (pnavClicks). Google doesn't just classify queries as navigational/non-navigational — it scores navigational intent on a gradient. A query might be 0.8 navigational (strong brand intent) or 0.3 (weak). This means the navigational exemption likely isn't binary in production — it's proportional. The stronger the navigational signal, the more the modification factor is dampened.
The Panda Connection: Same Engineer, Same Architecture
I need to say this directly. The inventor of this patent — Navneet Panda — is the person the Panda algorithm was named after. The Panda update, launched February 24, 2011, was the single most significant content quality algorithm in Google's history. It demoted thin content farms and rewarded substantive content. When the same engineer, 19 months later, files a patent about off-page signal quality — I pay attention to the architectural parallels.
| Dimension | Panda (Content Quality) | Implied Links (Off-Page Quality) |
|---|---|---|
| Input | Content quality signals per page | Independent links (express + implied) per site |
| Normalization | Site-level aggregation with page-level variance | Cohort-based normalization by branded search volume |
| Output | Multiplicative quality modifier (demotion or no change) | Multiplicative modification factor (demotion, neutral, or promotion) |
| Philosophy | Ratio-based quality detection ("is this content disproportionately thin compared to the site's authority?") | Ratio-based quality detection ("are these links disproportionate to the brand's actual awareness?") |
| API Module | pandaDemotion in CompressedQualitySignals | siteAuthority in CompressedQualitySignals |
Same engineer. Same ratio-based philosophy. Same multiplicative application. And in the API leak, both signals sit in the same module — CompressedQualitySignals. The Panda content demotion and the site authority score are stored together, scored together, and fed into Q* (Google's final ranking scorer) together.
Content quality and off-page signal quality run through the same quality pipeline. The same philosophical approach — "is the signal proportional to reality?" — is applied to both. A site with excellent content but a suspicious link-to-brand ratio still gets flagged. A site with a healthy off-page profile but thin content still gets Panda'd. You need to pass both checks. They sit in the same module for a reason.
SEO Implications: What This Means for Your Off-Page Strategy
1. Link building without brand building is mathematically self-defeating
Every link you build increases the numerator. If your client's brand awareness doesn't grow proportionally, the ratio gets worse. The patent's modification factor is designed to catch exactly this pattern. Pure link building without brand development is not just incomplete — it produces a measurable quality signal that leans toward demotion.
2. Digital PR generates double signals
A press mention that includes a link generates an express link. A press mention that doesn't include a link generates an implied link. Either way, the mention counts. This means Digital PR — which the SEO industry sometimes undervalues relative to direct link building — generates off-page signals regardless of whether the journalist links to you.
3. Branded search volume is the denominator — not a vanity metric
Your branded search volume (by unique users) doesn't just indicate brand strength. Under this patent, it's the denominator of the quality modification formula. Growing branded search volume lowers the modification factor, which means your link profile looks more natural. Brand awareness campaigns that drive people to search for your name aren't just "brand building" — they're mathematically improving your off-page quality signal.
4. Link reclamation has diminishing returns under this model
The SEO industry celebrates link reclamation — converting unlinked brand mentions into hyperlinks. Under this patent, the unlinked mention was already counted as an implied link. Converting it to an express link moves it from one type to the other within the same numerator. The net signal doesn't increase. Link reclamation still has value — express links carry PageRank, generate referral traffic, and may have higher weight — but the implied link value was already captured before you sent the outreach email.
5. Fake brand mentions don't pass the independence test
The patent's independence criteria are the same filters used in Seed Distance and IndyRank — same owner, same CSS, same content, duplicate detection. Manufacturing brand mentions from your own properties or a controlled network fails the independence filter. The same PBN that gets caught by IndyRank also gets caught here.
US9953049B1 (Seed Distance) — Seed Distance measures your graph proximity to trusted seed sites. Implied links extend the concept: you can be "close" to a trusted source through a brand mention, not just through a link. Read the analysis →
Google API Leak Cross-Reference: CompressedQualitySignals
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — revealed attributes that align directly with this patent's mechanisms. Critically, this patent has the strongest cross-reference hit rate of any patent I've analyzed: every mechanism maps to at least one API attribute.
| Patent Mechanism | API Attribute | Module | Alignment |
|---|---|---|---|
| Implied links (unlinked entity references) | webrefEntities |
PerDocData | ✅ CONFIRMED |
| Reference queries (branded searches) | crapsNewHostSignals |
CompressedQualitySignals | ✅ CONFIRMED |
| Navigational query classification | navDemotion + pnav |
CompressedQualitySignals + NsrData | ✅ CONFIRMED |
| Group modification factor | siteAuthority |
CompressedQualitySignals | 🔶 STRONG MATCH |
| Authority promotion | authorityPromotion |
CompressedQualitySignals | 🔶 STRONG MATCH |
| Independent link counting | scaledIndyRank |
CompositeDoc | ✅ CONFIRMED |
| Express link counting | nonLocalAnchorCount |
AnchorStatistics | ✅ CONFIRMED |
| Redundant signal cap (max 1 per source) | droppedRedundantAnchorCount |
AnchorStatistics | 🔷 API EXTENDS |
| Cohort normalization | siteChunk |
NsrData | 🔶 STRONG MATCH |
| Score modification with guardrails | pandaDemotion + lowQuality |
CompressedQualitySignals | 🔄 EVOLVED |
10 of 12 patent mechanisms (83%) have direct or strongly matching API evidence. The remaining two (same-owner detection and navigational probability scoring) have indirect support through IndyRank and NavBoost infrastructure.
The API leak provides attribute names and data types — not the actual scoring formulas. The patent provides the formulas. Together they form a strong evidentiary chain: the patent describes a system that counts links + mentions and divides by branded searches; the API reveals that entity annotations, anchor counts, independence scores, navigational signals, and site authority scores all exist in production. Neither alone is proof; together, they're as close to proof as we get in SEO.
Citation Network
Forward Citations (Patents Citing This Patent)
US8682892B1 has 10 forward citations through 2024 — a modest but active network indicating the concept remains referenced in newer filing families. The patent expired in March 2022 (maintenance fees unpaid), following the same pattern as Seed Distance (US9953049B1) and the Low Quality Classifier (US9002832B1). When Google lets a patent expire while newer patents continue to cite it, the concept has been absorbed — it no longer needs independent patent protection because it's become part of the foundational infrastructure.
Related Articles on This Site
This patent is part of a growing registry of Google ranking patents I'm documenting and cross-referencing:
- US8661029B1 (NavBoost) — NavBoost processes the navigational query signals that feed the reference query denominator. The patent's navigational exemption rule ("if navigational → factor = 1.0") runs on NavBoost data. These two systems are operationally connected.
- US9767157B2 (Panda) — Filed by the same inventor. The Panda quality demotion sits in the same API module (
CompressedQualitySignals) assiteAuthority. Same engineer, same quality philosophy, applied to different signal layers — content vs. off-page. - US7603350B1 (Entity Trust) — Entity trust determines who endorses your content. Implied links determine whether the endorsement needed to be a hyperlink. Trust is the quality check on the endorser; implied links are the detection channel for the endorsement.
- US9953049B1 (Seed Distance) — Seed Distance measures your graph proximity to trusted seed sites. Implied links extend the concept: you can be "close" to a trusted source through a brand mention, not just through a link path.
- US10235423B2 (Entity Scoring) — Entity Scoring uses the RNCP formula which also counts implied links. US10235423 was the first to formally define implied links in the context of entity ranking; US8682892 is the full implementation with the ratio-based quality check.
- US7716225B1 (Reasonable Surfer) — Reasonable Surfer weights link placement, font size, and click probability on the page. It optimizes existing express links. Implied links says you don't even need a link — the mention itself has value. These represent two different eras of thinking about off-page signals.
- US9268820B2 (Knowledge Panel) — The Knowledge Panel is the visible manifestation of entity recognition. Implied links feed the brand awareness signals that determine whether Google identifies your entity as notable enough for a KP. The implied link count contributes to the brand presence that leads to Knowledge Panel eligibility.
- NavBoost Deep Dive — NavBoost processes the navigational click signals that feed this patent's reference query denominator. The navigational exemption rule runs on NavBoost data, and the
navDemotionsignal sits alongsidesiteAuthorityin the same quality module. The practitioner synthesis maps the full circuit.
All analyses are cross-referenced in my On-Page SEO guide, which provides the applied framework built on this evidence base.
Implied Links: What Doesn't Matter as Much as SEOs Think
The nature of this patent is deceptively simple. A link without brand awareness is a signal without context.
For twenty years, the SEO industry has treated links as a standalone currency — more links equals more authority equals higher rankings. This patent adds a denominator to that equation. It says: your off-page authority isn't a sum. It's a ratio. And the denominator is something you can't fake with outreach, can't scale with automation, and can't buy from a vendor. The denominator is real people typing your brand name into a search box.
The flavor — the specific formula, Links ÷ Reference Queries, the cohort-based partitioning, the logarithmic dampening on high scores — was the 2012 implementation. By 2026, this ratio is likely one feature among hundreds in a neural quality scorer. The exact formula has likely evolved. But the principle — that disproportionate link growth relative to brand awareness looks unnatural — will survive any architecture change. The nature is permanent.
I think the most provocative implication of this patent is the one the industry doesn't quote. Everyone latches onto "brand mentions are a ranking factor" — which is true but incomplete. The real insight is the ratio. It's not that brand mentions help you. It's that links without brand proportionality hurt you. An agency that sells "500 links per month" without a corresponding brand awareness component isn't just selling half the equation. Above a certain threshold, they're actively making the ratio worse.
You cannot build a link profile faster than you build a brand. That's not a guideline. It's a patent.
Frequently Asked Questions
What does Google patent US8682892B1 actually do?
It creates a quality modification system for rankings based on two inputs: (1) the total count of express links (hyperlinks) plus implied links (unlinked brand mentions) from independent sources, and (2) the number of unique users who search for the brand. It divides links by branded searches to produce a modification factor, normalizes this within cohorts of similar-sized brands, and applies it multiplicatively to ranking scores.
What is an "implied link" in Google's patent?
The patent defines an implied link as "a reference to a target resource, e.g., a citation to the target resource, which is included in a source resource but is not an express link to the target resource." In plain English: any time your brand is mentioned on an independent website without a hyperlink. Press mentions, citations, name-drops, podcast transcripts — all qualify as implied links under this definition.
Do unlinked brand mentions really affect Google rankings?
The patent formally defines unlinked brand mentions ("implied links") as counting in the same signal bucket as hyperlinks ("express links"). The API leak reveals that Google's WebRef system annotates pages with entity mentions and salience scores — the production infrastructure for detecting implied links. Whether this specific counting mechanism is still implemented as described in 2012 is unknown, but the architectural concept — brand mentions as measurable signals — is confirmed in production.
Who invented the implied links patent?
Navneet Panda and Vladimir Ofitserov. Navneet Panda is the Google engineer whose name became synonymous with the Panda algorithm — the most significant content quality update in Google's history. He filed this patent 19 months after the original Panda update, applying the same ratio-based quality philosophy to off-page signals.
Is the implied links patent still active?
No. US8682892B1 expired in March 2022 because Google did not pay the Year 8 maintenance fees. This follows the same expiration pattern seen with Seed Distance and the Low Quality Classifier — patents whose concepts have been absorbed into Google's production infrastructure no longer need independent patent protection. The concept is active in production via WebRef, NavBoost, and CompressedQualitySignals; the patent itself is no longer enforced.
What is the modification factor and how does it work?
The modification factor equals your independent link count (express + implied) divided by your reference query count (unique branded searches). A high ratio (many links, few brand searches) is suspicious and triggers demotion. A balanced ratio is neutral. The factor is normalized within cohorts — small brands are compared to other small brands, not to Nike — and applied multiplicatively to ranking scores, with guardrails preventing over-demotion and navigational query exemptions.
Does this patent mean brand mentions pass PageRank?
No. The patent does not say implied links pass PageRank. Express links and implied links are counted in a separate quality modification system. The modification factor adjusts initial ranking scores multiplicatively — it doesn't transfer PageRank from mentioning pages to mentioned pages. The mechanism is fundamentally different from link equity. An implied link affects your quality ratio; an express link does that PLUS transfers PageRank.