The Reasonable Surfer Patent
In June 2004, Jeff Dean — co-inventor of MapReduce, TensorFlow, and the most senior technical leader in Google's history — filed a patent describing a system that would fundamentally change how links work. The premise was simple: PageRank's original model treats every link on a page as equally likely to be clicked. That's demonstrably false. A 16px editorial link in the opening paragraph of a relevant article is not the same as an 8px footer link buried under 500 other URLs. This patent replaces equal-weight PageRank with machine-learned per-link weights — and the 2024 API leak confirms that Google stores those weights, per-link, in production.
Do you see the ads on the right-hand side of YouTube? Yeah, me neither. But I sure do get hit by the mid-content interstitial ads in the video. It's no different with links. Placement determines attention. Attention determines value. This patent is the math behind that intuition.
This patent isn't a revelation to experienced link builders. I don't think a single SEO veteran would be surprised by what's in it. If they are, they really need to read something other than Search Engine Journal. The value of this analysis isn't surprise — it's confirmation. Every practitioner who has ever prioritized editorial in-content placements over directory listings was following this patent unknowingly. This article documents the mathematical receipt for what good operators already knew worked.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
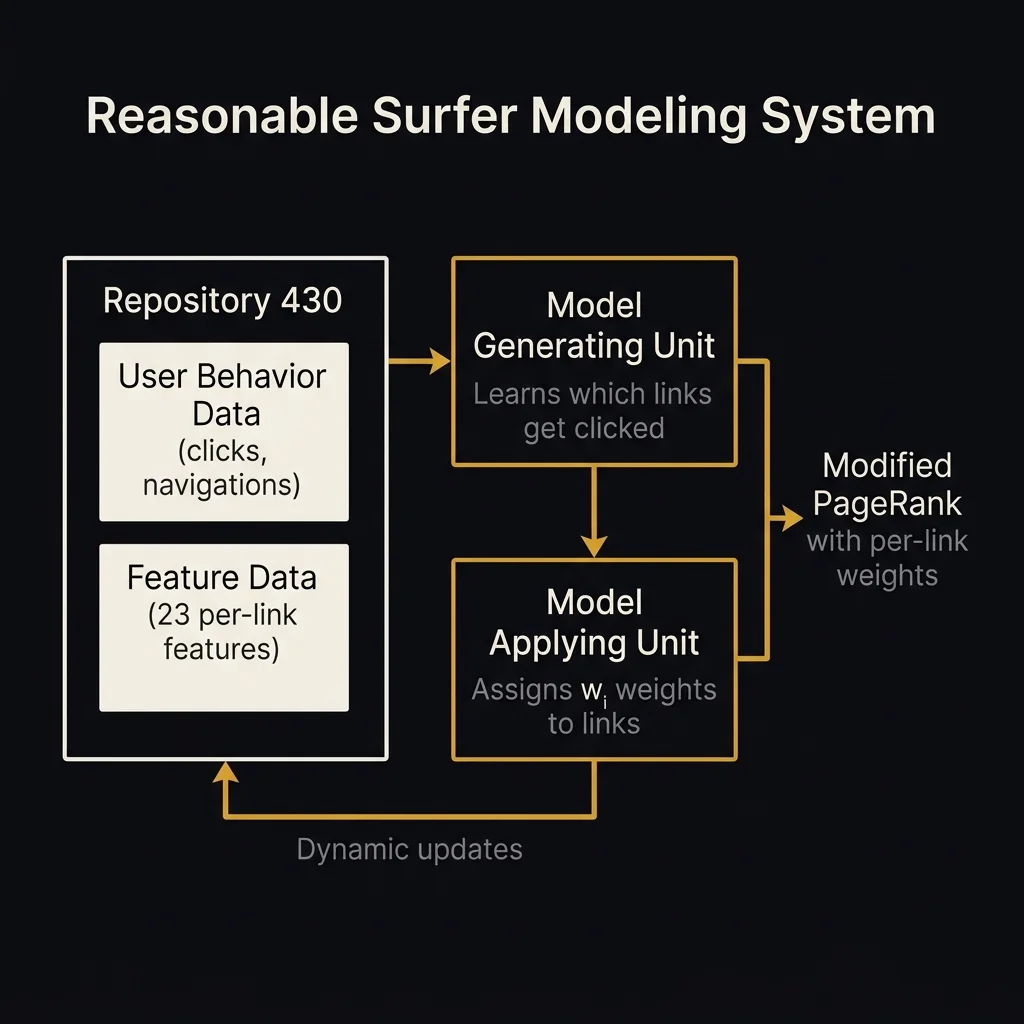
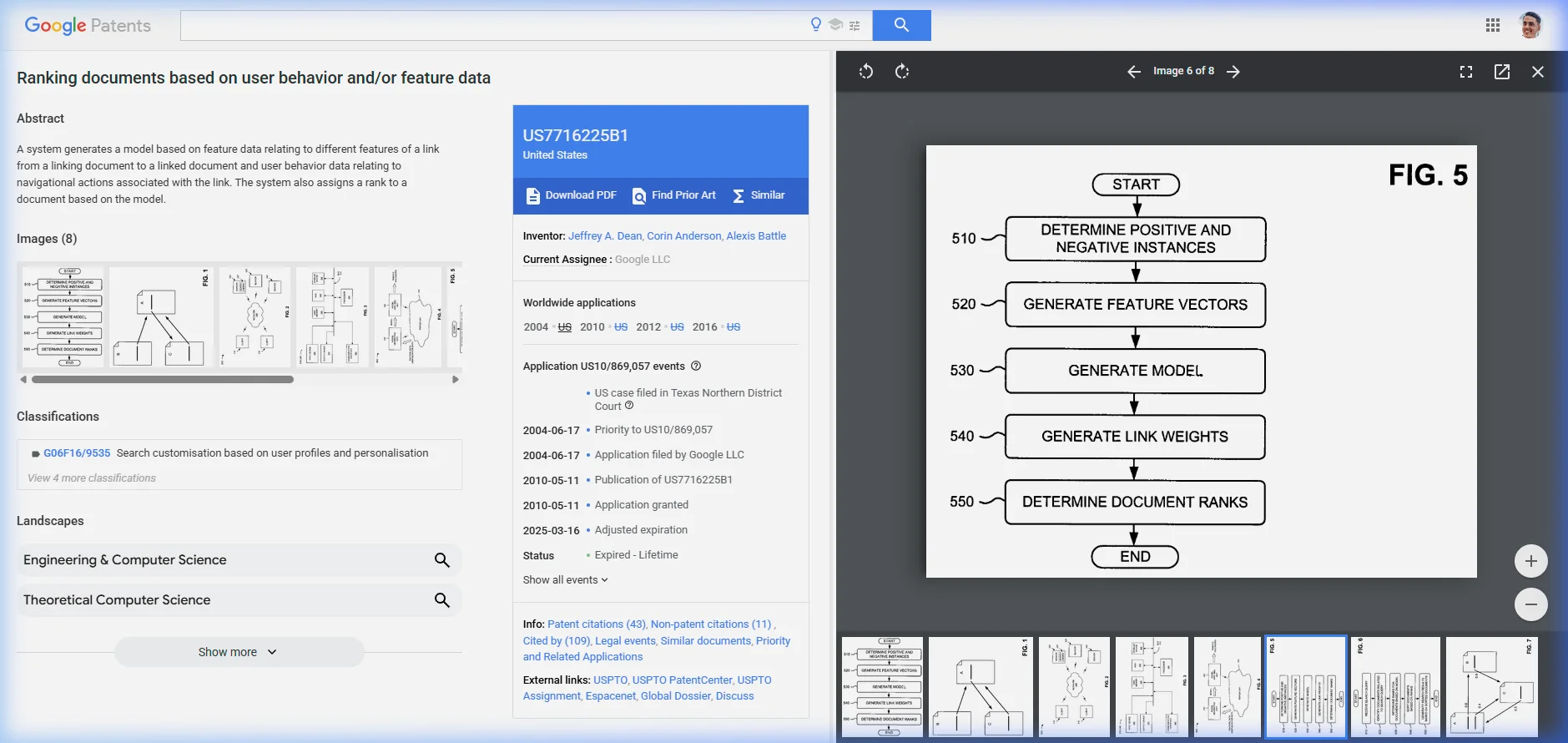
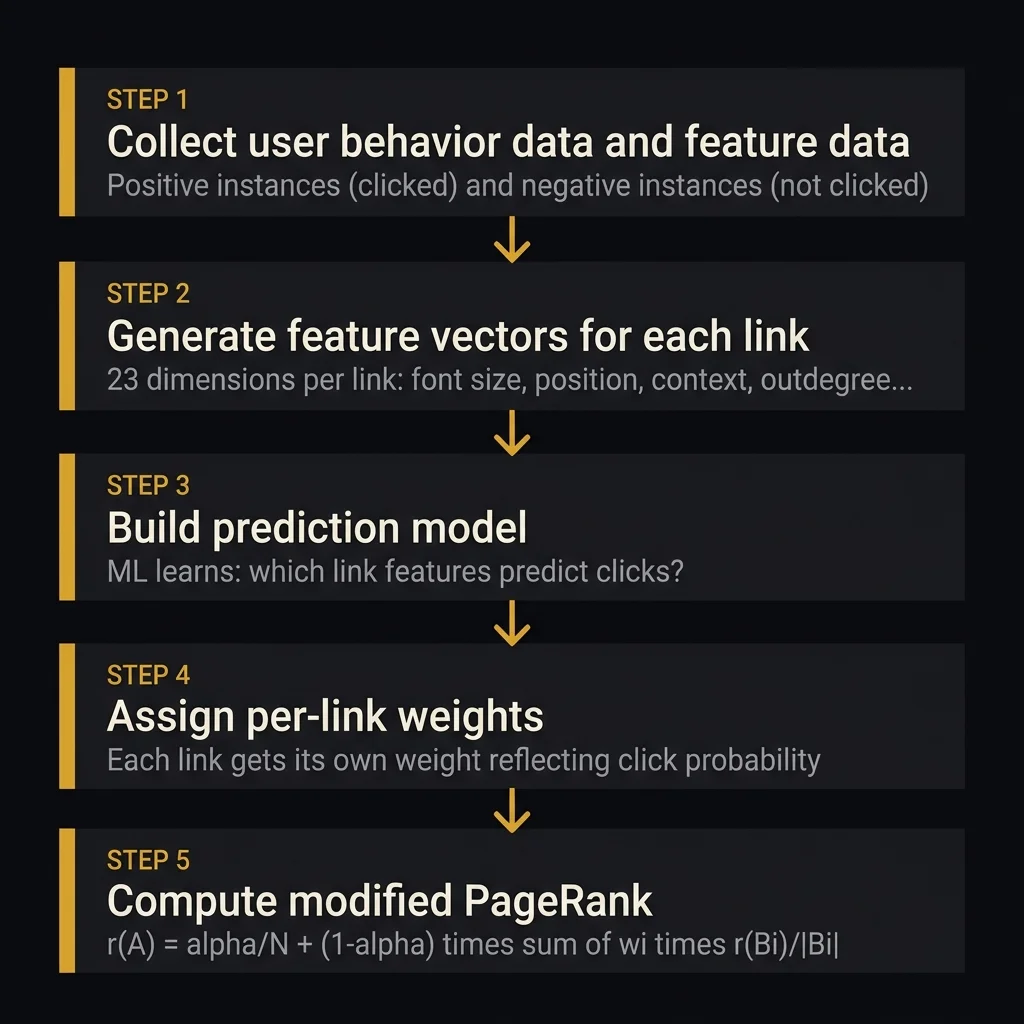
- Google designed a system where every link gets its own individually-computed weight (wᵢ) based on machine learning, replacing PageRank's equal distribution model. The modified formula is explicitly stated:
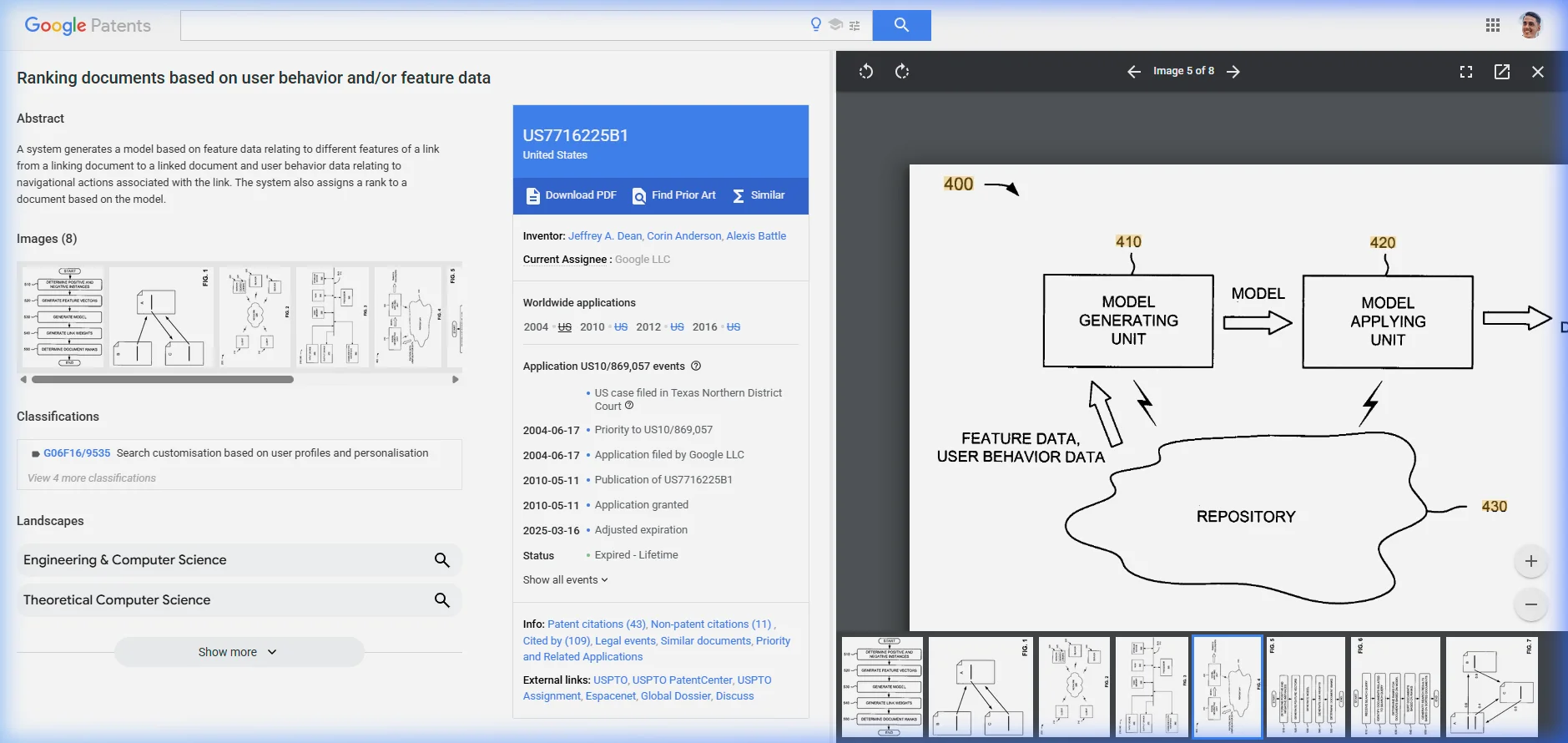
r(A) = α/N + (1-α) × Σ[wᵢ × r(Bᵢ)/|Bᵢ|]. - The system extracts 23 features per link across three categories: link features (font size, position, anchor text, commerciality), source document features (URL, outdegree, topical cluster), and target document features (URL, same host/domain check).
- Weights are learned from user behavior data — positive instances (users clicked the link) and negative instances (users didn't). The model is explicitly described as dynamic: it updates as user behavior changes.
- The system learns both general rules (links with larger font = higher click probability) and document-specific rules (e.g., links under "More Top Stories" on cnn.com = high probability).
- The patent was filed by Jeffrey A. Dean — co-inventor of MapReduce and TensorFlow, Google Senior Fellow. This is core infrastructure IP, not a junior filing.
- The API leak reveals
pagerankWeight(float),fontsize,offset,context2, andoutdegree— 5 direct attribute matches confirming the patent's mechanisms are stored per-link in production.
- The
pagerankWeightattribute in the API leak is the operational output of this patent's formula — the wᵢ in Equation 1. The naming and function match is near-certain. - The
sourceTypeattribute (HIGH_QUALITY → MEDIUM → LOW → BLACKHOLE) extends the patent's source-page quality concept into a tiered classification system the patent didn't describe explicitly. - The
anchorMismatchDemotionattribute (0-1023) extends the patent's topical cluster matching into a 10-bit demotion penalty — the patent described topic match as a feature; the API reveals it's also a punishment mechanism. - The patent's feature-based model likely serves as the permanent base layer that Chrome first-party click data augments — because most pages don't generate enough within-page outbound clicks for behavioral data alone to produce reliable weights.
- Whether the ML model behind
pagerankWeightis still logistic regression / naive Bayes (as the patent describes) or has been replaced by a neural network. Given Google's 2026 ML stack, the model is likely unrecognizable from the 2004 specification. - What the full feature set looks like in 2026. The patent lists 23 features from a 2004 web. Modern features likely include JavaScript-rendered link context, mobile viewport positioning, cross-device user sessions, and touch vs. click behavior differentiation.
- Whether there is a "NavBoost for outbound clicks" system. NavBoost (confirmed in the DOJ trial) tracks SERP clicks and dwell time. This patent tracks within-page outbound link clicks. Both use click data — but we don't know if they share infrastructure or remain separate systems.
- The exact threshold at which a link's
pagerankWeightapproaches zero — i.e., whether links that receive no clicks are truly zeroed out or merely heavily demoted.
Patent Metadata
Jeffrey Dean is Google's Chief Scientist and the most senior technical leader in the company's history. He co-designed MapReduce (the system that made large-scale web indexing possible), BigTable (the database underneath Search), and TensorFlow (the ML framework that powers modern Google). His co-authored patent on this research library is US7346839B2 (Historical Data) — the link age and velocity patent. When Jeff Dean patents a link-weighting system, it's not speculative research. It's infrastructure being formalized.
What This Patent Does (Plain English)
Original PageRank counts all links equally. A link in a footer = a link in the body = a link in a sidebar = a link on a "Terms of Service" page. This patent says that's wrong — and replaces equal distribution with a per-link weight (wᵢ) based on the predicted probability that a reasonable surfer would click that particular link.
The modified formula:
pagerankWeight per anchor.Here's what the system does:
- Extracts 23 features per link — font size, position on page, anchor text, surrounding context, source page outdegree, topical match between source and target, and 17 more dimensions.
- Collects user behavior data — which links users actually click (positive instances) and which they ignore (negative instances). "The user behavior data might be obtained from a web browser or a browser assistant."
- Trains an ML model — using naive Bayes, decision trees, logistic regression, or a "hand-tailored approach" to predict click probability.
- Assigns per-link weights — each link gets wᵢ reflecting the probability a reasonable surfer would select it.
- Computes modified PageRank — the weight determines how much equity each link actually passes.
Wait. Let me translate that to human.
↓
The Worked Example
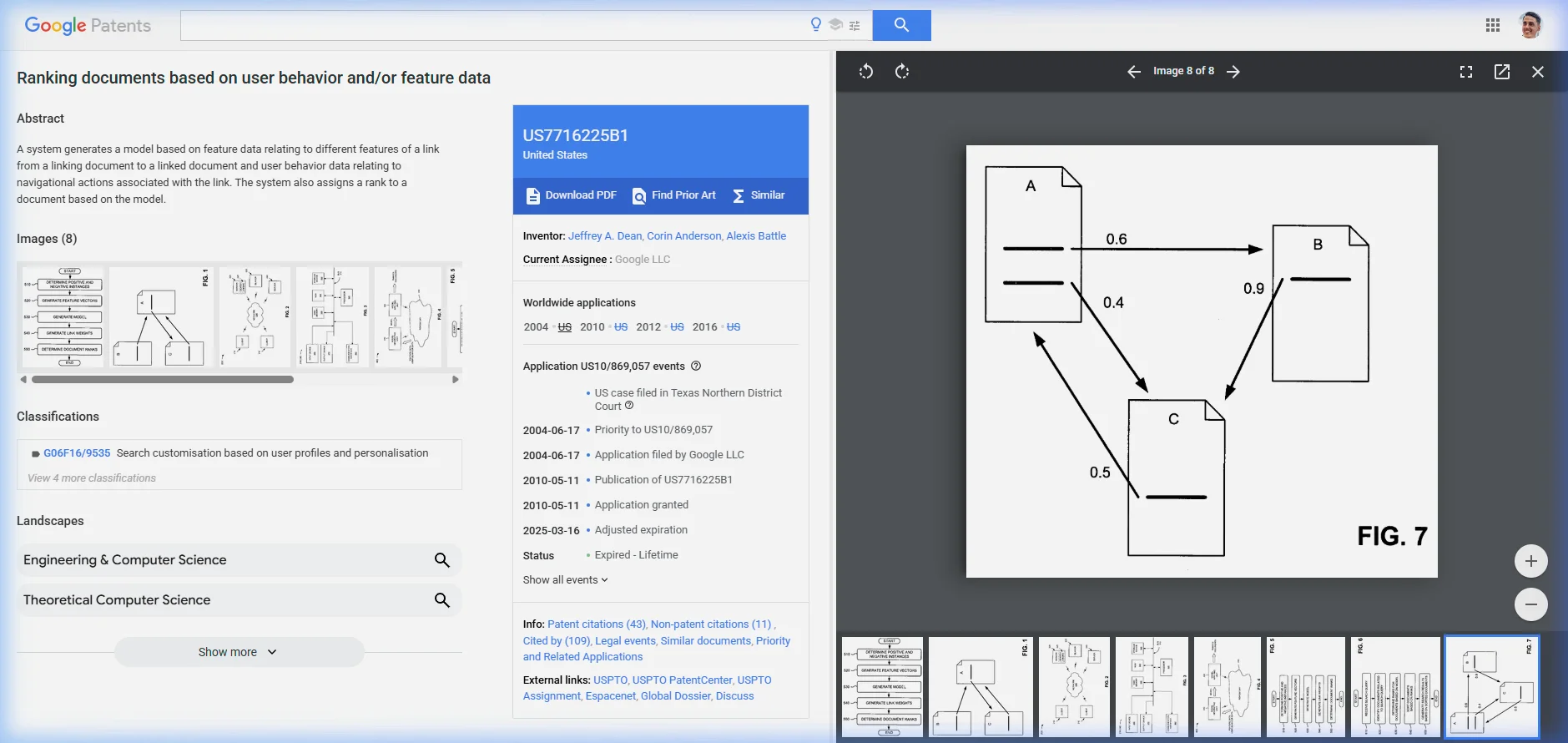
The patent includes a concrete example (FIG. 7) showing three documents with weighted links:
| Link | Weight (wᵢ) |
|---|---|
| C → A | 0.5 |
| A → B | 0.6 |
| B → C | 0.9 |
| A → C | 0.4 |
With α = 0.5, the resulting ranks: r(A) ≈ 0.237, r(B) ≈ 0.202, r(C) ≈ 0.281. Document C ranks highest — not because it has the most links, but because it receives the highest-weighted link (B→C at w=0.9). One high-quality editorial link outweighs two mediocre ones.
Wait. Let me translate that to human.
↓
The 23 Features Google Extracts from Every Link
This is the most concrete, actionable section of the patent. Google extracts features across three categories — the link itself, the source page, and the target page — and feeds them all into the ML model that produces wᵢ.
Features of the Link Itself
| # | Feature | What It Measures | API Confirmation |
|---|---|---|---|
| 1 | Font size of anchor text | Visual prominence | ✅ fontsize |
| 2 | Position on page | Above/below fold, header, footer, sidebar | ✅ offset |
| 3 | Position in list | Ordinal position if the link is within a list | — |
| 4 | Font color and attributes | Italics, gray text, same color as background | — |
| 5 | Number of words in anchor text | Anchor text length | — |
| 6 | Actual words in anchor text | The specific anchor text content | — |
| 7 | Commerciality of anchor text | Whether anchor text is commercial ("buy now") | — |
| 8 | Type of link | Image link vs. text link | — |
| 9 | Image aspect ratio | If image link, the dimensions (banner ad proportions detectable) | — |
| 10 | Context surrounding the link | Text around the link — editorial vs. navigational | ✅ context2 |
Features of the Source Document
| # | Feature | What It Measures | API Confirmation |
|---|---|---|---|
| 11 | URL of source document | Source page identity | — |
| 12 | Website of source | Domain-level identity | — |
| 13 | Number of links (outdegree) | Total outbound links from the source page | ✅ outdegree |
| 14 | Words in the document | Presence of specific terms in source page | — |
| 15 | Words in headings | Source page heading content | — |
| 16 | Topical cluster | What topic category the source belongs to | — |
| 17 | Topic match | Does source topic match anchor text topic? | 🔶 anchorMismatchDemotion |
Features of the Target Document
| # | Feature | What It Measures | API Confirmation |
|---|---|---|---|
| 18 | URL of target document | Target page identity | — |
| 19 | Website of target | Target domain identity | — |
| 20 | Same host check | Is target on same host as source? | — |
| 21 | Same domain check | Is target on same domain as source? | — |
| 22 | Words in target URL | Semantic content of the target URL | — |
| 23 | Length of target URL | URL complexity — spammy URLs tend to be longer | — |

This feature list is the most concrete evidence available for how Google evaluates individual links. Five of the 23 features have direct API leak confirmation — a 22% direct hit rate on a 2004 patent, which is remarkably high. The remaining 18 features are likely still used but may be stored differently, computed at crawl time rather than per-anchor, or absorbed into larger neural models. The patent's own language says these lists are "not exhaustive" — meaning the production system likely includes additional features the patent didn't describe.
The Behavioral Model: How User Clicks Train the Weights
The patent describes a specific mechanism for learning link weights from user behavior. It's not abstract — it specifies exactly how positive and negative instances are generated:
Page W has forward links to documents X, Y, and Z. The user behavior data shows these clicks: (W,X) twice and (W,Z) once. The system generates:
- 3 positive instances: 2 for W→X, 1 for W→Z
- 6 negative instances: 1 for W→X (when W→Z was clicked instead), 3 for W→Y (never clicked), 2 for W→Z (when W→X was clicked instead)
Every time a user picks one link, all the links they didn't pick become negative training data. The model learns click probability from the ratio of positive to negative instances, weighted by the 23-feature vector.
The patent specifies four ML techniques for building the model: naive Bayes, decision trees, logistic regression, and a "hand-tailored approach." And critically, the model is dynamic: "Since links periodically appear and disappear and user behavior data is constantly changing, model applying unit 420 may periodically update the weights assigned to the links."
Wait. Let me translate that to human.
↓
This patent describes click data collection via "a web browser or a browser assistant" — referring to the Google Toolbar, which is how Google gathered user behavior data in 2004. In 2026, Google owns Chrome (65%+ global browser market share). The behavioral data stream is orders of magnitude richer than what was available when this patent was filed. Every scroll, every dwell, every bounce, every tab switch — all of it feeds behavioral models that make the patent's positive/negative click instances look like counting on fingers. But here's the nuance: most pages don't generate enough outbound link clicks for behavioral data alone to produce reliable weights. A page with 100 visits per month and 10 outbound links generates single-digit clicks on those links. The sample size is too small for pure behavioral modeling. Which means the patent's feature-based model — font size, position, context — likely still operates as the base layer that Chrome click data augments where traffic provides sufficient signal.
General Rules vs. Document-Specific Rules
The model learns two kinds of patterns — and this distinction is significant:
General Rules (Apply Across All Documents)
- Links with larger font anchor text → higher probability of selection
- Links higher on the page → higher probability of selection
- Links where source topic matches target topic → higher probability of selection
Document-Specific Rules (Apply to Specific Pages)
These examples come directly from the patent text — they reveal how eerily specific the model gets:
- Link under "More Top Stories" on cnn.com → HIGH probability
- Link with target URL containing "domainpark" → LOW probability
- Link from a document with a popup → LOW probability
- Link to a domain ending in ".tv" → LOW probability
- Link with multiple hyphens in target URL → LOW probability
The cnn.com example reveals that Google's link-weighting model doesn't just learn universal patterns — it learns the editorial architecture of individual websites. A link in CNN's "More Top Stories" section gets high weight because the model has learned that users consistently click those links. A link in CNN's footer gets low weight because users don't. This means Google's system can distinguish between the premium editorial sections and the navigational templates of any website it crawls regularly — and assign different weights accordingly. Your link's position within the source site's editorial hierarchy matters as much as the site's raw authority.
SEO Implications: What This Means for Link Building
1. The DR Illusion
A client approaches saying they have DR 40-50. You dig deeper, and the DR is primarily driven by business citations — pages where they're one of 500 other listings, profile pages, signature links. Ahrefs calculates DR from the raw link graph, but Ahrefs can't see fontsize, offset, or context2. The Reasonable Surfer model can. DR is a proxy metric measuring aggregate link power. It tells you nothing about whether the links that built it were editorial in-content placements (high wᵢ) or 8px footer links on pages with 500 outbound URLs (low wᵢ). Two DR 50 sites can have wildly different pagerankWeight profiles.
2. Font Size Is a Literal Signal
The patent lists "font size of the anchor text associated with the link" as a feature. The API leak stores fontsize per anchor. A link in 16px body text passes more equity than the same link in 8px footer text. Google doesn't measure link prominence metaphorically — it stores the actual measurement. When you're evaluating a potential link placement, look at where the link will sit in the page's visual hierarchy. A link in the first paragraph of an article at body font size is worth exponentially more than a link in a widget sidebar.
3. Position Above the Fold Matters
The patent specifically mentions "above or below the first screenful viewed on an 800×600 browser display." The 800×600 viewport is laughably out of date. But the API attribute offset reveals Google still measures vertical position — just with modern viewport dimensions. Higher on the page = higher weight. This isn't speculation; it's stored per-link.
4. Outdegree Dilution Is Real — and Unequal
A page with 10 outbound links gives each link approximately 100× more equity than the same page with 1,000 outbound links. But the Reasonable Surfer model makes the distribution even more unequal — the one editorial in-content link on a clean page with 10 total links gets an outsized share of the equity versus 9 navigational links. This is why a single guest post on a clean industry blog outperforms 50 business citations on directory pages.
5. The Surrounding Context Hash
Google doesn't just read anchor text. The patent describes "the context of [the link]" as a feature, and the API stores this as context2 — a hash of surrounding text. My analysis of the Reference Contexts patent (US8577893B1) describes how Google analyzes the full surrounding paragraph. The two patents form a complementary system: Reasonable Surfer determines link weight; Reference Contexts validates the editorial context. Additionally, the API reveals anchorMismatchDemotion — a 10-bit penalty (0–1023) that fires when the anchor text topic doesn't match the surrounding content topic. Getting a keyword-rich anchor placed in an irrelevant article doesn't game the system; it triggers a demotion.
6. Topic Match Between Source and Target
The patent explicitly checks "a topical cluster associated with the source document matches a topical cluster associated with anchor text of a link." Off-topic links get lower wᵢ. A cooking blog linking to your SEO tool with anchor text "best SEO tools" — surrounded by a paragraph about marinara sauce — gets lower weight than the same link from an SEO industry blog where the surrounding content is topically aligned. Relevance isn't a bonus. It's built into the weight calculation.
7. The Uncomfortable Implication
Links nobody clicks pass less equity. The patent's model learns from positive instances (clicks) and negative instances (non-clicks). If a link receives zero positive instances, the model assigns it a low wᵢ — potentially approaching zero. This explains why links from pages with no traffic are practically worthless even when the source page has PageRank. If nobody visits the page, nobody clicks the link, and the wᵢ for that link approaches zero. The link exists on paper but passes minimal equity because the Reasonable Surfer model says "no reasonable surfer would select this link."
If you're putting money behind your off-page efforts, make sure that you invest in the kinds of places that will yield links most likely to generate clicks. That's the unit of measurement this patent defines — not "number of links" but "predicted click probability of each link."
A Canadian medical devices company we started building links for in June 2024. Starting position: 232 referring domains, DR 47, 112 keywords in the top 3. Current position (April 2026): 2,200 referring domains, DR 61, 604 keywords in the top 3, 508 AI citations, traffic up 140%. They show #1 on AI Overview for their primary category in Canada. Did they have links before? Yes. Were all new placements built following Reasonable Surfer principles — high on the page, in editorially relevant environments, with contextually appropriate anchors? Yes. The patent describes the math. The results confirm it at scale.
US8577893B1 (Reference Contexts) — Reference Contexts evaluates the editorial context surrounding links. If the Reasonable Surfer determines link weight, Reference Contexts validates whether the editorial context is genuine.
US7346839B2 (Historical Data) — Historical Data monitors temporal anomalies in link acquisition. A sudden spike of high-wᵢ links appearing overnight would trigger temporal analysis. This patent determines the weight; Historical Data monitors the timeline.
US9953049B1 (Seed Distance) — Seed Distance measures how far your page is from sites Google already trusts. Reasonable Surfer determines how much equity each link passes. Both are needed: you need links from seed-adjacent sites (Seed Distance) AND those links need to be high-weight editorial placements (Reasonable Surfer).
Google API Leak Cross-Reference
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — reveals multiple attributes that align directly with this patent's mechanisms. With 5 confirmed matches and 3 extensions, this patent has the highest API confirmation rate of any patent in this research library.
| Patent Mechanism | API Attribute | Alignment |
|---|---|---|
| Per-link weight (wᵢ) | pagerankWeight (float) in AnchorsAnchor | ✅ CONFIRMED — this IS the patent's wᵢ, stored per-anchor in production |
| Font size of anchor text | fontsize (float) in AnchorsAnchor | ✅ CONFIRMED — verbatim naming, per-anchor storage |
| Position of link on page | offset (uint32) in AnchorsAnchor | ✅ CONFIRMED — vertical position, per-anchor storage |
| Context surrounding the link | context2 (hash) in AnchorsAnchor | ✅ CONFIRMED — surrounding text hash, per-anchor storage |
| Number of links (outdegree) | outdegree (uint32) in AnchorsAnchorSource | ✅ CONFIRMED — source page link count |
| Source page quality tier | sourceType (enum: HIGH_QUALITY → BLACKHOLE) in AnchorsAnchor | 🔶 API EXTENDS — 5-tier classification not described in patent |
| Topical cluster match | anchorMismatchDemotion (int, 0-1023) in CompressedQualitySignals | 🔶 API EXTENDS — patent describes match as a feature; API reveals it's also a 10-bit penalty |
| Source page PageRank | pagerank (uint16, 0-65535) + pagerankNs in AnchorsAnchorSource | 🔶 API EXTENDS — 65,536 levels of granularity vs. old toolbar's 0-10 |
| User behavior (click instances) | — | 📜 PATENT ONLY — click data feeds upstream models, not stored per-anchor |
| User class personalization | — | 📜 PATENT ONLY — claimed in 2016 continuation, no direct API attribute |
| Image link aspect ratio | — | 📜 PATENT ONLY — likely computed at crawl time, not stored per-anchor |
| — | indyrank (uint16) in AnchorsAnchorSource | 🆕 API ONLY — source page independence score (PBN defense) |
✅ CONFIRMED = patent mechanism has direct, named API attribute match. 🔶 API EXTENDS = API reveals more detail than the patent describes. 📜 PATENT ONLY = patent describes mechanism, no direct API attribute found. 🆕 API ONLY = API reveals signal with no direct patent basis.
The pagerankWeight attribute in AnchorsAnchor is the single most important discovery in this cross-reference. It's stored as a float, per-anchor — meaning every single link pointing to your site has its own individually-computed weight. Not 1/outdegree. Not equal shares. A per-link, ML-computed weight that reflects whether a "reasonable surfer" would click it. The naming directly maps to this patent's Equation 1: wᵢ × r(Bᵢ)/|Bᵢ|. The wᵢ IS the pagerankWeight.
The API reveals indyrank (uint16) in AnchorsAnchorSource — a source page independence score. This attribute has no direct basis in the patent but is architecturally consistent with it: if the system measures per-link quality, it also needs to detect when multiple "independent" source pages are actually controlled by the same entity (PBN detection). indyrank appears to be the defense mechanism — measuring whether linking pages are genuinely independently owned. High indyrank = genuinely independent source. Low indyrank = potential coordinated link network.
Citation Network
Patent Family Chain
US7716225B1 (this patent, filed 2004, granted 2010 — expired, lifetime) → US8117209B1 (2012, expired — fee related) → US9305099B1 (2016, expired — fee related) → US10152520B1 (2018, expired — lifetime)
The original and final continuation both expired with "Lifetime" status — Google paid all fees and let the 20-year term run out naturally. Continuations 1 and 2 expired as "Fee Related" — Google stopped paying. The pattern: keep the broadest claims (original) and the most modern expansion (2016's user-class personalization), let the intermediate filings lapse. The 2016 continuation added classification G06F16/9535 — "Search customisation based on user profiles and personalisation" — meaning Google waited 12 years to formally claim per-user-class link weighting, likely because they had finally operationalized it.
Key Patent Citations (Cited by This Patent)
| Patent | Relevance |
|---|---|
| US6285999B1 | The original PageRank patent — explicitly cited as the base ranking model this patent modifies |
Related Articles on This Site
- US8577893B1 (Reference Contexts) — The editorial context validation layer. Reasonable Surfer determines link weight; Reference Contexts validates whether the surrounding content is genuine editorial material. The two patents form a complementary system — weight + context.
- US7346839B2 (Historical Data) — Co-invented by Jeff Dean. Monitors temporal patterns in link acquisition — age, velocity, freshness. If Reasonable Surfer evaluates each link's quality, Historical Data monitors how those links appeared over time.
- US9953049B1 (Seed Distance) — Measures structural trust through the link graph. Seed Distance asks "how close is this page to sites Google trusts?" Reasonable Surfer asks "how much equity does each link actually pass?" Both dimensions needed simultaneously.
- US7603350B1 (Entity Trust) — Measures trust between entities (people, organizations). Entity trust is the social layer; Reasonable Surfer is the structural layer. A link from a high-entity-trust author in an editorial placement (high wᵢ) on a seed-adjacent site is the trifecta.
- US8661029B1 (NavBoost) — NavBoost uses user click data for SERP ranking. Reasonable Surfer uses user click data for link weighting. Both use clicks — but NavBoost asks "do users click this search result?" while Reasonable Surfer asks "do users click links within this page?" They likely share click data infrastructure but serve different functions. See also: How NavBoost Really Works.
- US10235423B2 (Entity Scoring) — Entity Scoring computes an authority score from entity attributes. The entity behind the source page — and its scored authority — likely feeds into the source page's
sourceTypeclassification, which in turn affects thepagerankWeightof links from that page. - Quality Scoring Ensemble — Five independent quality systems cross-validating each other. The Reasonable Surfer's
pagerankWeightfeeds into the ensemble's link quality assessment — one signal among many, but a foundational one. - US8682892B1 (Implied Links) — Reasonable Surfer weighs express links (hyperlinks). Implied Links counts both express AND implied links (unlinked brand mentions). The Reasonable Surfer determines how much equity each hyperlink passes; Implied Links determines whether the ratio of all links to brand awareness looks natural. One is a per-link quality signal; the other is a portfolio-level proportionality check.
Nature vs. Flavor: The 2004 Blueprint and the 2026 Reality
The nature of this patent is permanent: not all links are created equal, and behavioral data — what humans actually click — is the ultimate arbiter of link value. That principle hasn't changed since 2004, and it won't change. It reflects how humans actually use the web.
The flavor — naive Bayes classifiers, Google Toolbar data collection, 800×600 viewports, static HTML pages — that was the 2004 technology available to implement the principle. By 2026, everything about the implementation has changed. Google runs transformer-based neural networks, not logistic regression. Chrome provides first-party behavioral data across 65%+ of the web's users. JavaScript-rendered pages are the norm, not the exception. Mobile viewports have replaced 800×600. Touch interactions coexist with clicks.
But here's the subtlety that most commentators miss: the patent's feature-based model isn't obsolete. It's the permanent base layer. Chrome click data provides rich behavioral signal for high-traffic pages. But most pages on the web — the long tail — don't generate enough outbound link clicks for behavioral data alone to produce reliable weights. A page with 100 monthly visits and 10 outbound links might see single-digit clicks across all those links. The sample size is too small. For those pages — which represent the vast majority of the web — the feature-based model (font size, position, surrounding context) is still the primary signal. Chrome data augments it where available. It doesn't replace it.
NavBoost tracks SERP clicks and dwell time — not within-page outbound link clicks. Unless there's a "NavBoost for outbound clicks" patent I haven't found, the Reasonable Surfer model remains the primary system for within-page link weighting. And the API leak confirms the outputs are still stored per-link: pagerankWeight, fontsize, offset, context2. The principle is permanent. The implementation is unrecognizable.
The SEO industry chases Domain Rating. But DR is a third-party proxy metric measuring aggregate link power. It tells you nothing about font size, position, editorial context, topic match, or click probability. Two DR 50 sites can have wildly different pagerankWeight profiles. This patent explains the structural difference between them — and it has for twenty years.
The reality of 2026 link building was formalized in a Google patent in 2004, co-authored by the man who designed the systems that make Google run. This patent isn't a revelation. It's a receipt.
Frequently Asked Questions
What is the Reasonable Surfer patent?
US7716225B1 — "Ranking documents based on user behavior and/or feature data" — is a Google patent filed in 2004 that replaces PageRank's equal-weight link model with machine-learned per-link weights. Each link gets a weight (wᵢ) based on its predicted click probability, determined by 23 features including font size, position on page, surrounding context, and topical relevance. The patent's core formula is: r(A) = α/N + (1-α) × Σ[wᵢ × r(Bᵢ)/|Bᵢ|].
Is the Reasonable Surfer model still used in 2026?
The 2024 Google API leak confirms that per-link weights are still stored in production: pagerankWeight, fontsize, offset, context2, and outdegree are all stored per-anchor in the AnchorsAnchor module. The ML model behind these weights has likely evolved well beyond the patent's naive Bayes and logistic regression — but the per-link weighting principle is actively in production.
Does font size really affect link equity?
Yes. The patent lists "font size of the anchor text" as a feature, and the API leak stores fontsize as a float value per anchor. A link in 16px body text passes more equity than the same link in 8px footer text. This is not metaphorical — Google literally records the font size measurement for every link it indexes.
Do footer and sidebar links pass less PageRank?
The patent's model predicts that links in visually prominent, editorially placed positions have higher click probability — and therefore higher wᵢ — than links in footers, sidebars, and navigation menus. The API attribute offset confirms Google measures vertical position per-link. While footer links aren't "worth zero," they carry substantially less weight than in-content editorial links. The Reasonable Surfer model makes this mathematically explicit.
How does this patent relate to NavBoost?
Both use user click data, but for different purposes. NavBoost (confirmed in the DOJ trial) uses SERP clicks to rank search results — it asks "do users click this result and stay?" The Reasonable Surfer uses within-page link clicks to weight link equity — it asks "do users click this link on the page?" They're complementary systems that likely share click data infrastructure (both drawing from Chrome) but serve different ranking functions.
Why does outdegree matter for link building?
A page with 10 outbound links distributes approximately 100× more equity per link than the same page with 1,000 outbound links. But the Reasonable Surfer model makes this even more unequal — the editorial in-content link on a clean page gets a disproportionate share based on its higher wᵢ, while 9 navigational links share the remainder. This is why links from clean editorial pages with few outbound links are exponentially more valuable than links from directories, blogrolls, or resource pages with hundreds of outbound links.
What should I change about my link building strategy based on this patent?
Stop counting links. Start evaluating link quality through the lens of this patent: (1) Is the link high on the page? (2) Is it in body-size font within editorial content? (3) Is the surrounding context topically relevant? (4) Does the source page have low outdegree? (5) Does the source page actually get traffic (positive click instances)? If you're investing in link building, invest in placements most likely to generate clicks. That's the unit of measurement this patent defines.