The Seed Distance PageRank Patent
The 2024 Google API leak revealed an attribute called PagerankNS — a 16-bit integer stored on every single page in Google's index. Most people assumed the "NS" stood for "namespace." The strongest reading is that NS stands for NearestSeeds — a naming convention that maps directly to a 2006 patent by Google engineer Nissan Hajaj. If that reading is correct, it strongly suggests that Google has been running a seed-distance variation of PageRank since at least 2006 — measuring proximity to trusted sites rather than counting raw citations.
This article is built on three sources: the patent text (the legal document filed with the USPTO), the 2024 Google API documentation leak, and observable ranking behavior. The patent proves Google designed a seed-distance ranking system. The API leak shows attribute names consistent with it. Neither proves this exact formula runs in production today — and the patent itself describes its approach as "one possible variation of PageRank." I'll be explicit throughout about where evidence ends and inference begins.
If you've read my analysis of the Reference Contexts patent, that system evaluates what is written around your links. If you've read the Historical Data patent, that one monitors when your links appeared. This patent answers a more fundamental question: how far is your page from the sites Google already trusts? And the answer carries exponential consequences.
The Honest Hedge
Every analysis has a threshold where certainty ends and inference begins. Here's where that line falls for this patent:
- Google filed and was granted a patent for ranking pages based on shortest distances from hand-curated seed sites, using exponential decay scoring.
- The system uses k nearest seeds (k = 3–6), assigns link lengths based on outdegree properties, and pages unreachable from any seed receive no score.
- The patent names Google Directory and The New York Times as example seeds.
- The parent application was filed in 2006; the continuation was granted in 2018. Year 4 maintenance fees were paid.
- The patent describes itself as describing "one possible variation of PageRank" — not a confirmed replacement of the original.
- The API attribute
PagerankNS(NearestSeeds) stored as uint16 strongly suggests this patent's seed-distance model is reflected in production scoring. - The downstream signal
authorityPromotioninCompressedQualitySignalssuggests seed distance feeds the Q* composite score — meaning it may contribute to the final ranking computation. - The
homepagePagerankNsattribute implies site-level seed distance scoring exists alongside page-level scoring. - Patent continuations and fee payments suggest ongoing legal value — though this proves portfolio maintenance, not necessarily production relevance.
- The exact seed list — it's presumably evolved significantly since Google Directory was discontinued in 2011.
- The current value of k (3? 6? dynamic?).
- Whether seeds are global or topic-sensitive (query-specific micro-seed clusters).
- Whether Graph Neural Networks or SpamBrain pre-processing have superseded the explicit shortest-path formula while preserving the seed-distance concept.
- Whether modern "distance" includes entity co-occurrence (unlinked mentions) alongside hyperlink paths.
- The exact weighting of seed distance within the Q* composite score.
- A maintenance fee reminder has been mailed — if fees aren't paid, the patent expires. This doesn't mean Google would stop using the technology, but it would mean competitors could freely implement it.
Patent Metadata
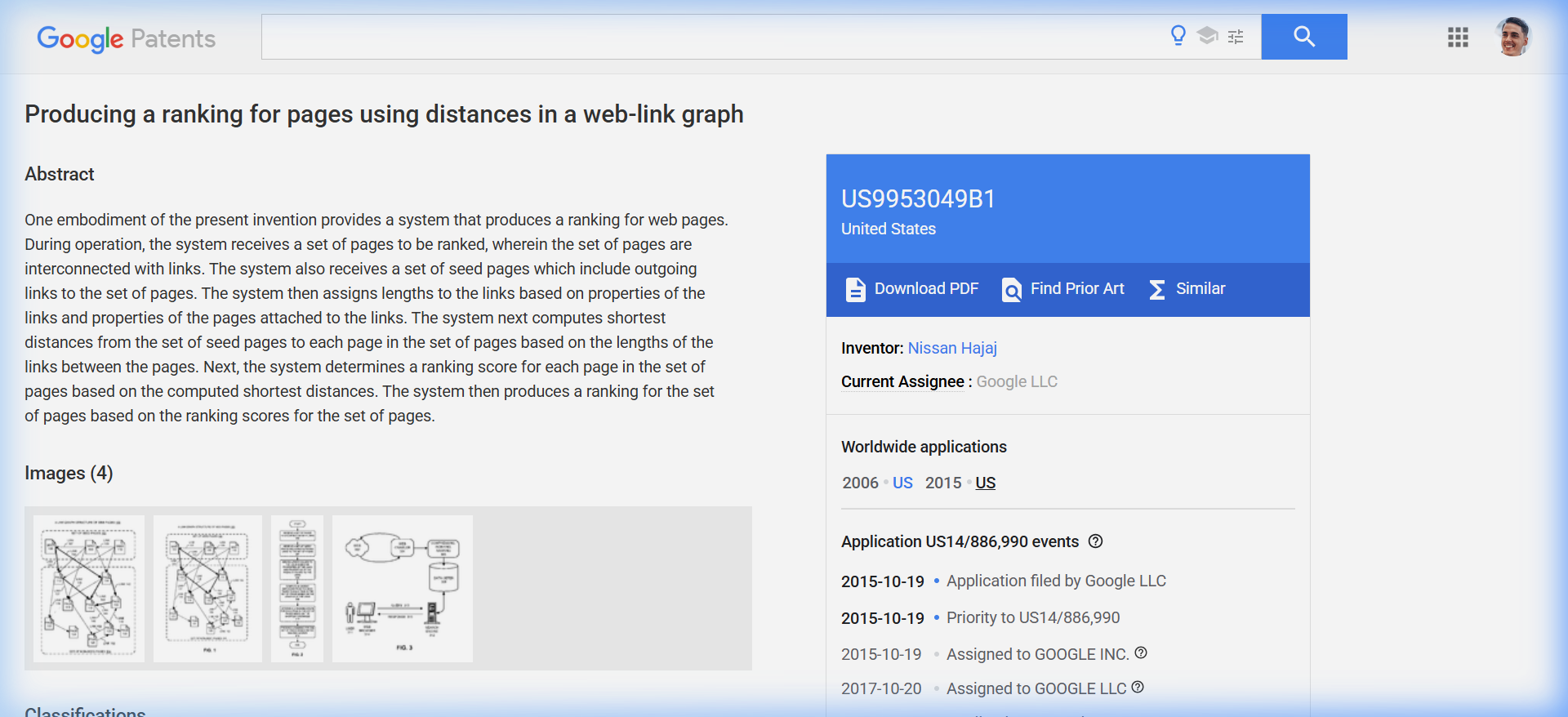
What This Patent Does (Plain English)
Classic PageRank (the 1998 version) asked: "How many pages link to this page, and how important are they?" This patent describes a variation of that approach — one that asks: "How far is this page from the websites Google has hand-selected as trustworthy?"
Here's what the system does:
- Select seed sites — Human reviewers at Google curate a set of trusted "seed" websites. The patent names Google Directory and The New York Times as examples. Seeds must be reliable, diverse across fields of public interest, and well-connected with many outgoing links.
- Assign link lengths — Every link on the web is assigned a "length" based on the source page's properties. A page with 5 outgoing links creates short links. A page with 5,000 outgoing links creates very long links. More outgoing links = each individual link is worth less.
- Compute shortest paths — For every page on the web, the system calculates the shortest path from the k nearest seed sites (typically k = 3–6). This requires shortest-path computation in a weighted directed graph — the same class of graph traversal used in GPS navigation.
- Apply exponential decay — The ranking score is proportional to e−D(p), where D(p) is the distance from the kth nearest seed. This is an exponential function — every additional hop away from a seed site doesn't just reduce score linearly; it collapses it exponentially.
- Produce ranking — Pages are ranked by their distance scores. Pages unreachable from any seed get no score at all — they are unscored by this mechanism.
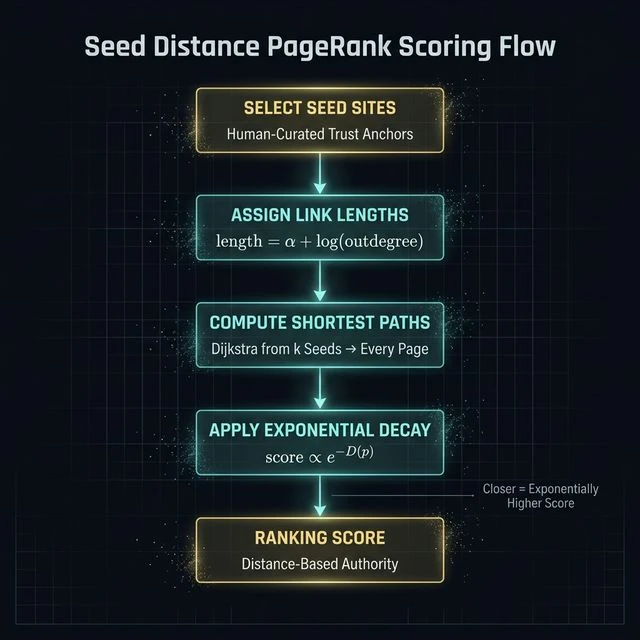
Link Length: Why Outdegree Destroys Value
Every link in the web graph is assigned a "length" — a numerical value representing how much distance that link adds between the source and destination. This is the mechanism that makes editorial links from focused pages mathematically superior to links from directories, link roundups, and resource pages with hundreds of outgoing links.
Here's the formula:
Here's what this means in practice:
| Source Page Type | Outgoing Links | Link Length | Relative Value |
|---|---|---|---|
| Editorial article mentioning you in context | 5 | 1.77 | Strongest — genuine endorsement |
| Curated resource page | 20 | 3.16 | Strong — selective curation |
| Blog post with many outlinks | 100 | 4.77 | Medium — diluted |
| Link roundup | 500 | 6.38 | Weak — mass listing |
| Directory page | 5,000 | 8.68 | Nearly worthless — commodity link |
These values are worked examples using the patent's formula with a natural-log reading. The actual ranking score depends on weighted shortest paths through multiple links, the kth nearest seed calculation, and optional link weights — not on a single link's outdegree in isolation.
Under this patent's model, a link from a page with 5,000 outgoing links creates roughly 5× more mathematical distance than a link from a page with 5 outgoing links. That's not a small difference — it means the link from the directory page adds substantially more "distance" between you and the seed sites. And because the final score uses exponential decay, that extra distance has devastating downstream effects.
This patent's formula counts all outgoing links on a page — including navigation, footers, and sidebars. Modern web pages routinely have 200+ links in their DOM from mega-menus alone. Google's Reasonable Surfer patent (US7716225B1) and subsequent DOM segmentation models isolate the main content block, likely calculating effective outdegree from editorial links in the body text — not raw HTML link count. The practitioner takeaway is the same (fewer editorial links on the page = stronger signal), but the raw numbers in the table above assume the patent's simplest reading, not Google's likely modern refinement.

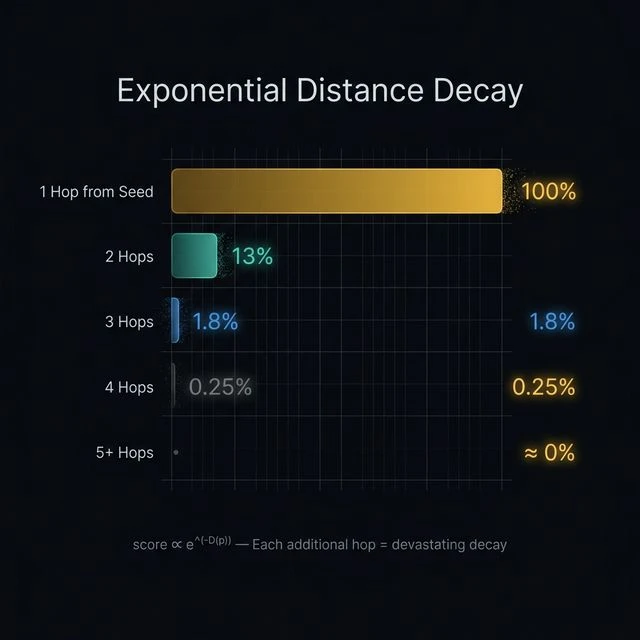
Exponential Decay: The Distance Cliff
This is the mechanism that makes seed distance so consequential. The ranking score for any page is calculated as:
The exponential function creates a cliff, not a slope. The following is a worked example — not a universal lookup from the patent. It assumes each hop passes through a low-outdegree editorial page (roughly 6 outlinks, link length ≈ 2.0):
| Hops from Seed | Score (e−D) | % of 1-Hop Value |
|---|---|---|
| 1 hop | 0.135 | 100% |
| 2 hops | 0.018 | 13% |
| 3 hops | 0.0025 | 1.8% |
| 4 hops | 0.00033 | 0.25% |
| 5+ hops | 0.000045 | ≈ 0% |
Look at that cliff. Two hops from a seed site and you're already at 13% of the maximum value. Three hops and you're under 2%. This is why a single link from a major publication can outperform dozens of links from sites further down the chain — and it's why link chains (whether PBN chains or otherwise) face mathematical headwinds that no amount of volume can overcome.
This doesn't mean sites three or four hops from a seed are worthless. I wouldn't call sites that are three, four hops away from seed dead — not at all. The aggregate of many medium-distance links still contributes meaningfully to your overall profile. But this table explains why the last link sometimes unlocks everything: you already had 50 links that built the foundation, and the 51st link from a seed-adjacent site was the one piece your profile was missing. That one gap was a much bigger deficiency than missing the other 50 combined.
Seed Selection and Tuning: Google's Trust Anchor Network
The entire system rests on one critical foundation: the seed set. These are the "trust anchors" from which all distance is measured. The patent is unusually specific about what makes a good seed:
- Reliable — consistently high-quality over time
- Diverse — covering "a wide range of fields of public interests," not all in ONE vertical
- Well-connected — seeds need large numbers of outgoing links to "facilitate identifying other useful and high-quality pages"
- Manually selected — "selecting the seeds involves a human manually identifying these high-quality pages"
The patent gives two specific examples: Google Directory (the curated web directory Google discontinued in 2011) and The New York Times. These are exactly the kinds of sites you'd expect — broad editorial authority, high trust, deep link graphs reaching into every corner of the web.
The patent describes an iterative refinement process: the ranking results are fed back to "evaluate the quality and the contribution of the seeds, and then modify the list of seeds and/or the weights of the seeds based on this information." In other words, the seed set isn't static — Google continuously evaluates which seeds are producing useful distance signals and adjusts the set accordingly. Seeds that stop connecting to high-quality pages can be demoted or removed. This is an evolving trust network, not a fixed list.
Two structural shifts since 2006 complicate the patent's literal model. First, most major Seed Sites (Forbes, NYT, universities, health portals) now default to rel="nofollow" or rel="sponsored" on outbound links — meaning the pure hyperlink-distance calculation the patent describes faces broken bridges at exactly the points where trust should flow most freely. Second, Google likely uses topic-sensitive seed clusters rather than a single universal list. Your "distance" to a seed isn't absolute — it's relative to the query topic. A DR 30 niche-specific journal that's a topical seed for your vertical may carry more weight than a global news seed linking to a tangentially related page. The patent describes a single global seed list; modern Google likely runs thousands of contextual micro-seed networks.
The k-Nearest Seeds
The system doesn't measure distance from just one seed — it uses the kth nearest seed, where k is typically 3–6. This means your page needs to be close to multiple seed sites, not just one. A single link from The New York Times is valuable, but a page reachable from three different seed sites through short paths is structurally stronger than a page reachable from only one.
This is why link diversity isn't just a best practice — it's architecturally built into the scoring function. Google's system literally measures proximity to k different trust anchors. A diverse link profile that connects you to multiple corners of the seed network will structurally tend to outscore a concentrated profile from a single direction.
The Unreachable Problem
Pages that cannot be reached from any seed through any path receive no score at all. They are unscored by this process. This has implications for brand-new websites, orphan pages, and sites in corners of the web that aren't connected to the broader link ecosystem. The patent states: "not all the pages in the set of pages receive ranking scores through this process. A page that cannot be reached by any of the seed pages will not be ranked."
Seed Distance SEO Implications: What This Means for Your Link Profile
1. The "51st Link" Effect Is Real
I've seen this pattern hundreds of times: a site builds 50 good links and ranks respectably but not competitively. Then they land one placement on Healthline, or Forbes, or a major industry publication — and everything unlocks.
Here's why: SEO is a competition. You're not ranked on an absolute scale — you're ranked relative to the sites around you. If your competitors have built volume but lack seed proximity, that single seed-adjacent link gives you a structural advantage they can't replicate with quantity. You now have something they don't. And because the scoring is exponential, that one link doesn't just add to your profile — it transforms the math. The 50 foundation links that were "doing nothing" suddenly click, because the distance calculation changed. The foundation was always there; the bridge to the seed network was the missing piece.
2. Digital PR Is the Seed Distance Accelerator
Digital PR is amazing — but in isolation, it's nowhere nearly as amazing as when you combine it with everything else. A single high-trust placement shortens your distance to the seed network dramatically. But if that's your only link building strategy, you're missing the aggregate volume that medium-distance links provide. The ideal strategy is both: PR placements for seed proximity plus sustained outreach for breadth.
3. Outdegree Is Your Silent Enemy
Every additional outgoing link on your source page makes your link longer in the graph. A link from a page with 5 outlinks is ~5× shorter than a link from a page with 5,000. When evaluating backlink opportunities, how many other links does this page have? is one of the most underrated questions in link building. Guest posts on exclusive placement pages > guest posts on pages citing 50 other sources.
4. Brand Consensus Works Through Seed Distance
When your brand is mentioned and linked from multiple seed-adjacent publications — industry journals, major media, academic institutions — you're not just building "brand awareness." You're shortening your graph distance to multiple seeds simultaneously. Brand consensus isn't a vague metric — it's the structural result of being close to many trust anchors at once.
5. LLMs Inherit Seed Trust
Imagine an article on Bank of America's website that mentions the best lenders in a given state and links to you. What source will an LLM never question as trustable? Bank of America. The seed distance concept doesn't just apply to traditional rankings — it extends to how AI systems select which sources to cite. Seed-adjacent sources get cited in AI-generated answers without friction, because the trust signal is baked into the graph structure that LLMs are trained on or retrieve from.
US8577893B1 (Reference Contexts) — Evaluates the editorial context around your links. Seed Distance measures how far you are; Reference Contexts measures how naturally your links are embedded. Both feed into link quality scoring.
US7346839B2 (Historical Data) — Monitors the temporal patterns of your link acquisition. Seed Distance is spatial; Historical Data is temporal. Together they form the positional and velocity dimensions of link quality.
Two more forces reshape how seed distance works in practice. First, SpamBrain — Google's neural spam detector — pre-processes the link graph before any distance calculation runs. If SpamBrain identifies unnatural link patterns (tiered chains, PBN clusters, sudden link velocity spikes), it can sever nodes from the graph entirely. Your mathematical distance may look excellent in third-party tools, but Google's graph may have already amputated the bridges that created it. Second, modern Google doesn't limit "distance" to hyperlinks. The API's repositoryWebrefEntityJoin system extracts entity co-occurrence from raw text — no <a href> required. If a Seed Entity (like The New York Times or WHO) mentions your brand in running text, Google's neural models can shorten your effective distance without a literal link existing. The patent describes a hyperlink-only graph; the 2026 reality includes entity-level proximity as a parallel distance signal.
Google API Leak Cross-Reference: PagerankNS
The 2024 Google API leak — first reported by Rand Fishkin and investigated by Mike King at iPullRank — revealed five attributes that align directly with this patent's mechanisms:
| Patent Mechanism | API Attribute | API Evidence |
|---|---|---|
| NearestSeeds distance scoring | PagerankNS (uint16, 0–65535) in GDocumentBase | ✅ STRONG MATCH — NS = NearestSeeds |
| Exponential decay from seed sites | pagerankWeight (float) in AnchorsAnchor | ✅ STRONG MATCH — per-anchor weight consistent with distance-based decay |
| Link length = α + log(outdegree) | outdegree + outsites in AnchorsAnchorSource | ✅ STRONG MATCH — stores outdegree data the formula requires |
| — | scaledSelectionTierRank (0–32767) — normalized tier position | 🔶 API EXTENDS |
| — | authorityPromotion in CompressedQualitySignals | 🔶 API EXTENDS |
✅ STRONG MATCH = the API attribute name and data type align closely with the patent mechanism, but the API doesn't confirm the formula is implemented exactly as filed. 🔶 API EXTENDS = the API reveals a signal not described in the patent but consistent with its architecture. 📄 PATENT ONLY = the patent describes a concept with no matching API attribute discovered in the leak.
PagerankNS — where NS most likely stands for NearestSeeds. This is the strongest available clue — not proof — that Google's production PageRank incorporates a seed-distance model. The API gives us attribute names and data types, not scoring formulas. The patent gives us the formulas. Together they form a strong but still incomplete evidentiary chain. The API also reveals authorityPromotion — a quality boost in the Q* composite score that appears derived from seed distance — suggesting seed distance doesn't just affect PageRank but likely feeds the master quality signal.
The API leak provides attribute names and data types — not the actual scoring formulas. The patent provides the formulas. Together they form a strong evidentiary chain. Neither alone is proof; together, they're as close to proof as we get in SEO. The API also reveals homepagePagerankNs — a site-level seed distance score — which the patent doesn't explicitly describe but is a logical extension of the per-page distance calculation.
Citation Network
Patent Family Chain
US9165040B1 (parent, filed 2006, granted 2015) → US9953049B1 (this patent, continuation, granted 2018)
Forward Citations (Patents Citing This Patent)
| Patent | Relevance |
|---|---|
| US20160335257A1 | Extends graph-based ranking methodology |
| US10692298B2 | Builds on distance-based page quality assessment |
| US20230153924A1 | Recent (2023) patent application citing seed distance concepts |
Related Articles on This Site
- US8577893B1 (Reference Contexts) — While Seed Distance measures how far your page is from trusted sources, Reference Contexts measures how naturally each link is embedded in its surrounding text. Distance + context = the complete link quality picture.
- US7346839B2 (Historical Data) — Historical Data watches for temporal anomalies in link acquisition. Seed Distance gives the spatial dimension; Historical Data gives the temporal dimension. A page that suddenly shortens its seed distance through a burst of high-trust links will trigger temporal analysis.
- US7603350B1 (Entity Trust) — If Seed Distance measures trust through the link graph, Entity Trust measures trust through the entity graph — how much the people who vouch for your content are trusted by others. Both were filed in 2006, four months apart, by different Google engineers. Two dimensions of the same trust architecture.
- US7716225B1 (Reasonable Surfer) — Seed Distance determines how far your page is from Google's trust anchors. The Reasonable Surfer determines how much equity each link actually passes, using ML-learned per-link weights. You need both: links from seed-adjacent sites (short distance) AND those links need to be high-weight editorial placements (high wᵢ).
- US8682892B1 (Implied Links) — Implied Links extends the distance concept: you can be "close" to a trusted source through a brand mention, not just through a hyperlink path. Both patents feed
CompressedQualitySignals. Seed Distance measures graph proximity through links; Implied Links adds unlinked entity mentions as a parallel channel. - NavBoost Deep Dive — Seed Distance determines how close you are to trust; NavBoost determines whether users confirm that trust with their behaviour. A page can have excellent seed proximity but poor engagement — or vice versa. The practitioner synthesis maps how NavBoost's host-level quality scoring creates a statistical distribution that interacts with the trust signals seed distance provides.
Seed Distance: What Doesn't Matter as Much as SEOs Think
The nature of this patent is simple: trust radiates from known sources, and it decays with distance. That's not an algorithm quirk — that's how human trust actually works. You trust your doctor's recommendation more than a stranger's. You trust the stranger your doctor recommended more than someone five referrals removed. The web graph works the same way.
The flavor — the specific math, the kth nearest seed, the logarithmic link length formula — that was the 2006 approach, refined through 2018. Google has likely evolved the implementation. The seed set has certainly changed since Google Directory shut down. The k value may be dynamic. The decay function may have been modified.
But the architecture — measuring distance from trust anchors rather than counting raw citations — that isn't going anywhere. It's too fundamental. It's the difference between asking "how many people vouch for you?" and "how close are you to people we already trust?" The second question is harder to game, more resistant to manipulation, and more aligned with how authority actually propagates through networks.
The SEO industry still obsesses over Domain Rating as if it's the signal. It isn't. DR measures the aggregate power of all incoming links — it's a useful proxy, but it doesn't measure seed distance. Two DR 60 sites can have wildly different distances from the seed network. DR is like measuring someone's height. Seed distance is like measuring their relationship to power. Both are real — but don't confuse one for the other.
Here's what I tell clients: if you're worried about which links to build next, stop wondering about DR and start asking — how close is this site to the sites Google already trusts? That's the question this patent's architecture rewards — and the API naming suggests it's closer to Google's actual scoring than raw link counts are.
Frequently Asked Questions
What does patent US9953049B1 actually do?
It describes a distance-measurement variation of PageRank. Instead of asking "how many pages link to you?", the system measures how far your page is from a hand-curated set of trusted seed sites — and applies exponential decay to the score. Closer pages get exponentially higher scores.
What is PagerankNS in the Google API leak?
PagerankNS is a uint16 integer (0–65535) stored on every document in Google's index. NS most likely stands for NearestSeeds — strongly suggesting that Google's production PageRank incorporates a seed-distance model rather than relying solely on the 1998 citation-counting approach. It appears to feed into authorityPromotion, which is part of the Q* composite quality score.
Does seed distance make PBNs (private blog networks) useless?
Not directly. Seed distance penalizes chained PBNs — where private sites link to each other in chains, adding hops and compounding distance. A PBN using expired or auctioned domains that are already close to the seed network may retain some of the previous owner's graph position — though this patent doesn't address domain ownership transfers, and SpamBrain's ability to detect unnatural link patterns in acquired domains adds significant uncertainty to this strategy.
Why does one Forbes link sometimes outperform 50 niche blog links?
Profile completion. If you already have 50 good mid-distance links, your aggregate foundation is solid but you're missing seed proximity. One Forbes link closes that gap — you were at 99% and it fills the final 1%. That last 1% was a bigger deficiency than the other 50 combined. Forbes alone without the foundation wouldn't rank you either — it's the combination that unlocks competitive positions.
How does seed distance affect AI Overviews and LLMs?
LLMs inherit graph-based trust signals. When an LLM selects which sources to cite in generated answers, it leans toward sources that come from seed-adjacent sites — because those are the sources with the strongest structural trust markers. Being one hop from Bank of America or Healthline doesn't just help your traditional rankings; it makes you a more likely citation target in AI-generated responses.
Is Domain Rating (DR) the same as seed distance?
No. DR measures the aggregate strength of all incoming links to a domain — it's a third-party metric from Ahrefs that approximates PageRank. Seed distance measures proximity to Google's hand-curated trust anchors. Two DR 60 sites can have very different seed distances. Think of DR as measuring how many people vouch for you, and seed distance as measuring how close those people are to actual power. Both are real signals, but they measure different things.
What happens to pages that aren't connected to any seed site?
They receive no score at all. The patent explicitly states that "a page that cannot be reached by any of the seed pages will not be ranked." This affects brand-new websites, orphan pages without inbound links, and sites in isolated corners of the web. Getting your first link from a seed-connected domain isn't just helpful — it's the entry ticket to being scored at all.